 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUDsim: Quantifying Discourse Similarities in LLM-Generated Text
Apr 12, 2025



As large language models become increasingly capable at various writing tasks, their weakness at generating unique and creative content becomes a major liability. Although LLMs have the ability to generate text covering diverse topics, there is an overall sense of repetitiveness across texts that we aim to formalize and quantify via a similarity metric. The familiarity between documents arises from the persistence of underlying discourse structures. However, existing similarity metrics dependent on lexical overlap and syntactic patterns largely capture $\textit{content}$ overlap, thus making them unsuitable for detecting $\textit{structural}$ similarities. We introduce an abstraction based on linguistic theories in Questions Under Discussion (QUD) and question semantics to help quantify differences in discourse progression. We then use this framework to build $\textbf{QUDsim}$, a similarity metric that can detect discursive parallels between documents. Using QUDsim, we find that LLMs often reuse discourse structures (more so than humans) across samples, even when content differs. Furthermore, LLMs are not only repetitive and structurally uniform, but are also divergent from human authors in the types of structures they use.
Which questions should I answer? Salience Prediction of Inquisitive Questions
Apr 16, 2024Inquisitive questions -- open-ended, curiosity-driven questions people ask as they read -- are an integral part of discourse processing (Kehler and Rohde, 2017; Onea, 2016) and comprehension (Prince, 2004). Recent work in NLP has taken advantage of question generation capabilities of LLMs to enhance a wide range of applications. But the space of inquisitive questions is vast: many questions can be evoked from a given context. So which of those should be prioritized to find answers? Linguistic theories, unfortunately, have not yet provided an answer to this question. This paper presents QSALIENCE, a salience predictor of inquisitive questions. QSALIENCE is instruction-tuned over our dataset of linguist-annotated salience scores of 1,766 (context, question) pairs. A question scores high on salience if answering it would greatly enhance the understanding of the text (Van Rooy, 2003). We show that highly salient questions are empirically more likely to be answered in the same article, bridging potential questions (Onea, 2016) with Questions Under Discussion (Roberts, 2012). We further validate our findings by showing that answering salient questions is an indicator of summarization quality in news.
QUDEVAL: The Evaluation of Questions Under Discussion Discourse Parsing
Nov 01, 2023
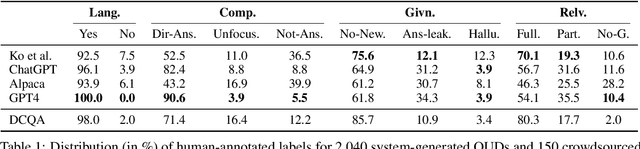
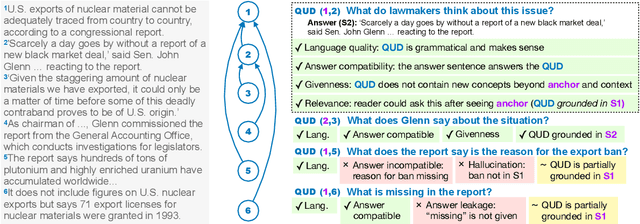
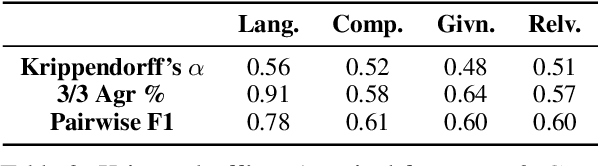
Questions Under Discussion (QUD) is a versatile linguistic framework in which discourse progresses as continuously asking questions and answering them. Automatic parsing of a discourse to produce a QUD structure thus entails a complex question generation task: given a document and an answer sentence, generate a question that satisfies linguistic constraints of QUD and can be grounded in an anchor sentence in prior context. These questions are known to be curiosity-driven and open-ended. This work introduces the first framework for the automatic evaluation of QUD parsing, instantiating the theoretical constraints of QUD in a concrete protocol. We present QUDeval, a dataset of fine-grained evaluation of 2,190 QUD questions generated from both fine-tuned systems and LLMs. Using QUDeval, we show that satisfying all constraints of QUD is still challenging for modern LLMs, and that existing evaluation metrics poorly approximate parser quality. Encouragingly, human-authored QUDs are scored highly by our human evaluators, suggesting that there is headroom for further progress on language modeling to improve both QUD parsing and QUD evaluation.
Elaborative Simplification as Implicit Questions Under Discussion
May 17, 2023Automated text simplification, a technique useful for making text more accessible to people such as children and emergent bilinguals, is often thought of as a monolingual translation task from complex sentences to simplified sentences using encoder-decoder models. This view fails to account for elaborative simplification, where new information is added into the simplified text. This paper proposes to view elaborative simplification through the lens of the Question Under Discussion (QUD) framework, providing a robust way to investigate what writers elaborate upon, how they elaborate, and how elaborations fit into the discourse context by viewing elaborations as explicit answers to implicit questions. We introduce ElabQUD, consisting of 1.3K elaborations accompanied with implicit QUDs, to study these phenomena. We show that explicitly modeling QUD (via question generation) not only provides essential understanding of elaborative simplification and how the elaborations connect with the rest of the discourse, but also substantially improves the quality of elaboration generation.
Discourse Analysis via Questions and Answers: Parsing Dependency Structures of Questions Under Discussion
Oct 12, 2022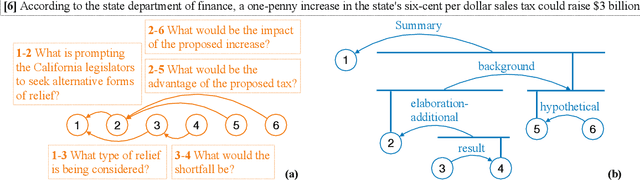

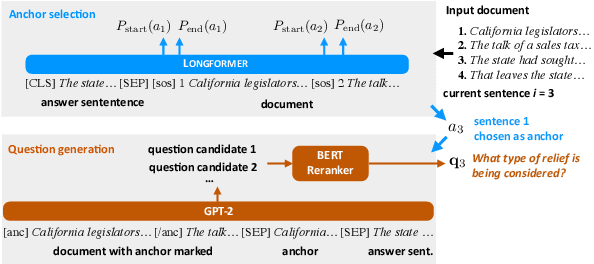
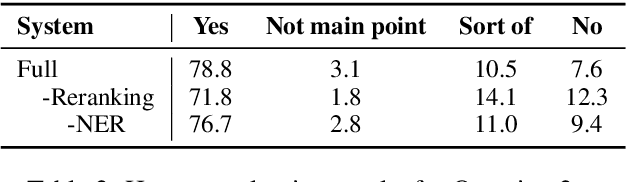
Automatic discourse processing, which can help understand how sentences connect to each other, is bottlenecked by data: current discourse formalisms pose highly demanding annotation tasks involving large taxonomies of discourse relations, making them inaccessible to lay annotators. This work instead adopts the linguistic framework of Questions Under Discussion (QUD) for discourse analysis and seeks to derive QUD structures automatically. QUD views each sentence as an answer to a question triggered in prior context; thus, we characterize relationships between sentences as free-form questions, in contrast to exhaustive fine-grained taxonomies. We develop the first-of-its-kind QUD parser that derives a dependency structure of questions over full documents, trained using a large question-answering dataset DCQA annotated in a manner consistent with the QUD framework. Importantly, data collection is easily crowdsourced using DCQA's paradigm. We show that this leads to a parser attaining strong performance according to human evaluation. We illustrate how our QUD structure is distinct from RST trees, and demonstrate the utility of QUD analysis in the context of document simplification. Our findings show that QUD parsing is an appealing alternative for automatic discourse processing.
longhorns at DADC 2022: How many linguists does it take to fool a Question Answering model? A systematic approach to adversarial attacks
Jun 29, 2022



Developing methods to adversarially challenge NLP systems is a promising avenue for improving both model performance and interpretability. Here, we describe the approach of the team "longhorns" on Task 1 of the The First Workshop on Dynamic Adversarial Data Collection (DADC), which asked teams to manually fool a model on an Extractive Question Answering task. Our team finished first, with a model error rate of 62%. We advocate for a systematic, linguistically informed approach to formulating adversarial questions, and we describe the results of our pilot experiments, as well as our official submission.