 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUDEVAL: The Evaluation of Questions Under Discussion Discourse Parsing
Paper and Code

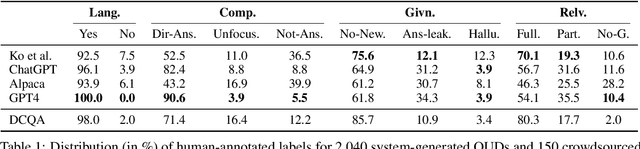
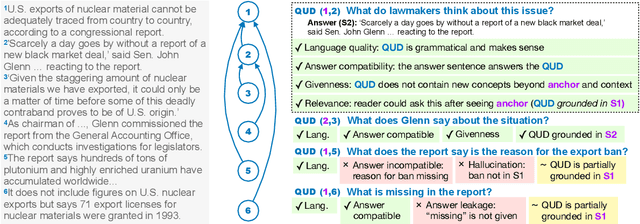
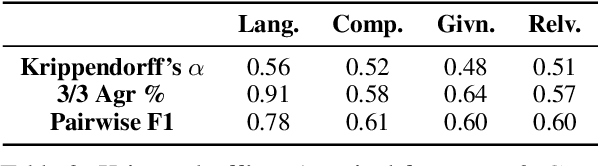
Questions Under Discussion (QUD) is a versatile linguistic framework in which discourse progresses as continuously asking questions and answering them. Automatic parsing of a discourse to produce a QUD structure thus entails a complex question generation task: given a document and an answer sentence, generate a question that satisfies linguistic constraints of QUD and can be grounded in an anchor sentence in prior context. These questions are known to be curiosity-driven and open-ended. This work introduces the first framework for the automatic evaluation of QUD parsing, instantiating the theoretical constraints of QUD in a concrete protocol. We present QUDeval, a dataset of fine-grained evaluation of 2,190 QUD questions generated from both fine-tuned systems and LLMs. Using QUDeval, we show that satisfying all constraints of QUD is still challenging for modern LLMs, and that existing evaluation metrics poorly approximate parser quality. Encouragingly, human-authored QUDs are scored highly by our human evaluators, suggesting that there is headroom for further progress on language modeling to improve both QUD parsing and QUD evaluation.