 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Hitori Puzzles: Neurosymbolic Proof Staging for Sequential Decisions
Aug 19, 2025We propose a neurosymbolic approach to the explanation of complex sequences of decisions that combines the strengths of decision procedures and Large Language Models (LLMs). We demonstrate this approach by producing explanations for the solutions of Hitori puzzles. The rules of Hitori include local constraints that are effectively explained by short resolution proofs. However, they also include a connectivity constraint that is more suitable for visual explanations. Hence, Hitori provides an excellent testing ground for a flexible combination of SAT solvers and LLMs. We have implemented a tool that assists humans in solving Hitori puzzles, and we present experimental evidence of its effectiveness.
Show, Don't Tell: Learning Reward Machines from Demonstrations for Reinforcement Learning-Based Cardiac Pacemaker Synthesis
Nov 04, 2024An (artificial cardiac) pacemaker is an implantable electronic device that sends electrical impulses to the heart to regulate the heartbeat. As the number of pacemaker users continues to rise, so does the demand for features with additional sensors, adaptability, and improved battery performance. Reinforcement learning (RL) has recently been proposed as a performant algorithm for creative design space exploration, adaptation, and statistical verification of cardiac pacemakers. The design of correct reward functions, expressed as a reward machine, is a key programming activity in this process. In 2007, Boston Scientific published a detailed description of their pacemaker specifications. This document has since formed the basis for several formal characterizations of pacemaker specifications using real-time automata and logic. However, because these translations are done manually, they are challenging to verify. Moreover, capturing requirements in automata or logic is notoriously difficult. We posit that it is significantly easier for domain experts, such as electrophysiologists, to observe and identify abnormalities in electrocardiograms that correspond to patient-pacemaker interactions. Therefore, we explore the possibility of learning correctness specifications from such labeled demonstrations in the form of a reward machine and training an RL agent to synthesize a cardiac pacemaker based on the resulting reward machine. We leverage advances in machine learning to extract signals from labeled demonstrations as reward machines using recurrent neural networks and transformer architectures. These reward machines are then used to design a simple pacemaker with RL. Finally, we validate the resulting pacemaker using properties extracted from the Boston Scientific document.
All Entities are Not Created Equal: Examining the Long Tail for Fine-Grained Entity Typing
Oct 22, 2024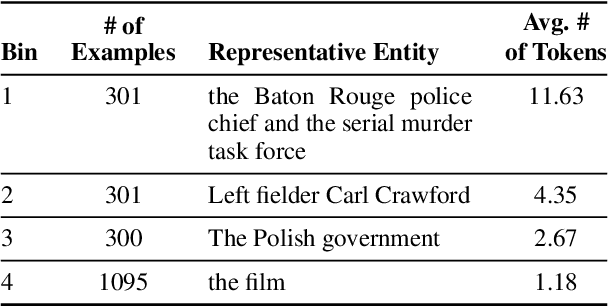
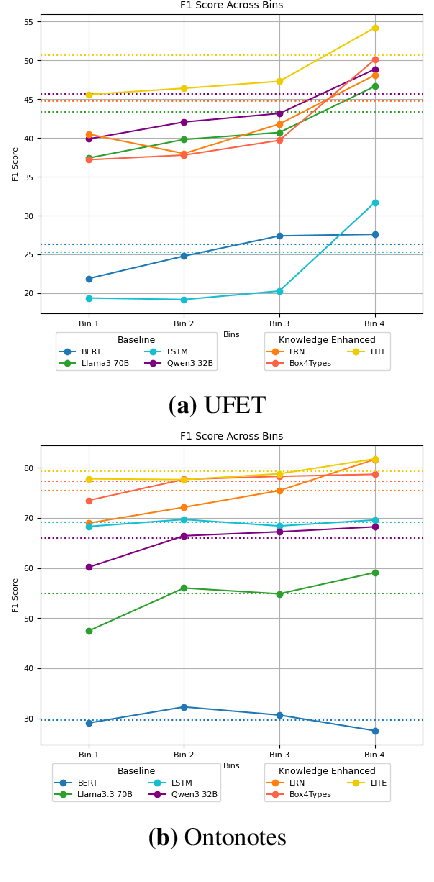
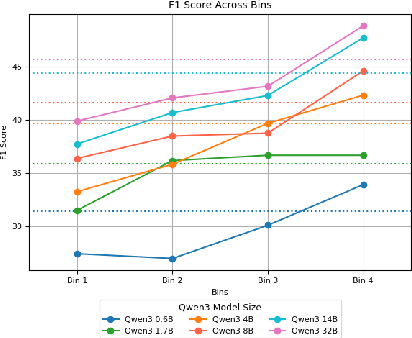
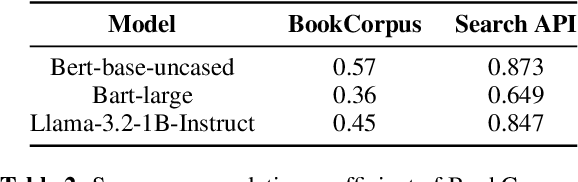
Pre-trained language models (PLMs) are trained on large amounts of data, which helps capture world knowledge alongside linguistic competence. Due to this, they are extensively used for ultra-fine entity typing tasks, where they provide the entity knowledge held in its parameter space. Given that PLMs learn from co-occurrence patterns, they likely contain more knowledge or less knowledge about entities depending on their how frequent they are in the pre-training data. In this work, we probe PLMs to elicit encoded entity probabilities and demonstrate that they highly correlate with their frequency in large-scale internet data. Then, we demonstrate that entity-typing approaches that rely on PLMs struggle with entities at the long tail on the distribution. Our findings suggests that we need to go beyond PLMs to produce solutions that perform well for rare, new or infrequent entities.
Studying the Effects of Collaboration in Interactive Theme Discovery Systems
Aug 16, 2024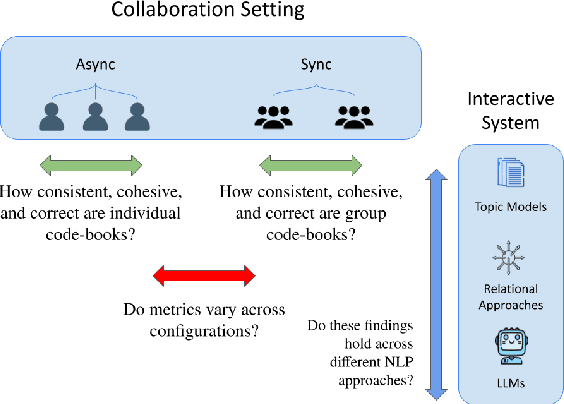

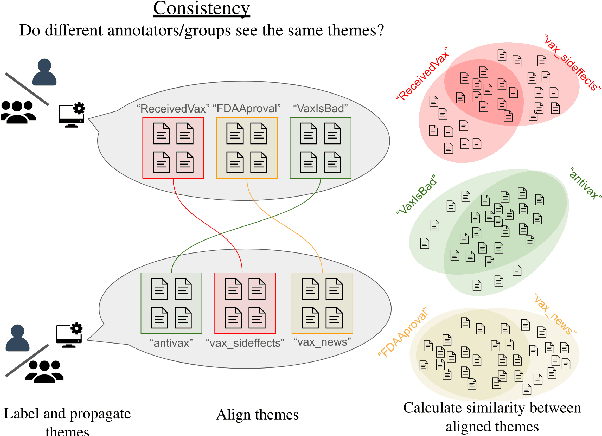
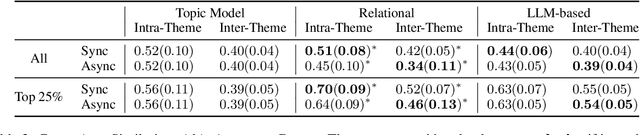
NLP-assisted solutions have gained considerable traction to support qualitative data analysis. However, there does not exist a unified evaluation framework that can account for the many different settings in which qualitative researchers may employ them. In this paper, we take a first step in this direction by proposing an evaluation framework to study the way in which different tools may result in different outcomes depending on the collaboration strategy employed. Specifically, we study the impact of synchronous vs. asynchronous collaboration using two different NLP-assisted qualitative research tools and present a comprehensive analysis of significant differences in the consistency, cohesiveness, and correctness of their outputs.
On the Potential and Limitations of Few-Shot In-Context Learning to Generate Metamorphic Specifications for Tax Preparation Software
Nov 20, 2023
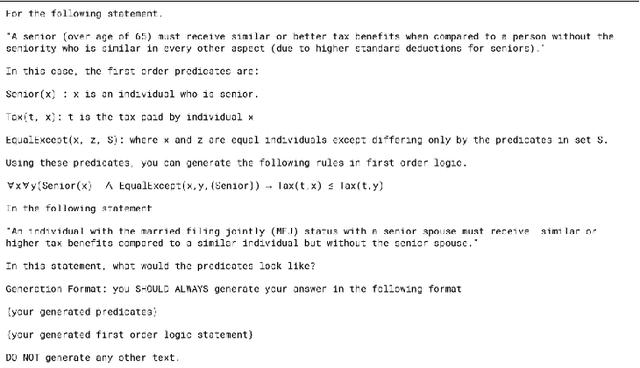


Due to the ever-increasing complexity of income tax laws in the United States, the number of US taxpayers filing their taxes using tax preparation software (henceforth, tax software) continues to increase. According to the U.S. Internal Revenue Service (IRS), in FY22, nearly 50% of taxpayers filed their individual income taxes using tax software. Given the legal consequences of incorrectly filing taxes for the taxpayer, ensuring the correctness of tax software is of paramount importance. Metamorphic testing has emerged as a leading solution to test and debug legal-critical tax software due to the absence of correctness requirements and trustworthy datasets. The key idea behind metamorphic testing is to express the properties of a system in terms of the relationship between one input and its slightly metamorphosed twinned input. Extracting metamorphic properties from IRS tax publications is a tedious and time-consuming process. As a response, this paper formulates the task of generating metamorphic specifications as a translation task between properties extracted from tax documents - expressed in natural language - to a contrastive first-order logic form. We perform a systematic analysis on the potential and limitations of in-context learning with Large Language Models(LLMs) for this task, and outline a research agenda towards automating the generation of metamorphic specifications for tax preparation software.
System Demo: Tool and Infrastructure for Offensive Language Error Analysis (OLEA) in English
Oct 28, 2022



The automatic detection of offensive language is a pressing societal need. Many systems perform well on explicit offensive language but struggle to detect more complex, nuanced, or implicit cases of offensive and hateful language. OLEA is an open-source Python library that provides easy-to-use tools for error analysis in the context of detecting offensive language in English. OLEA also provides an infrastructure for re-distribution of new datasets and analysis methods requiring very little coding.
Discourse Analysis via Questions and Answers: Parsing Dependency Structures of Questions Under Discussion
Oct 12, 2022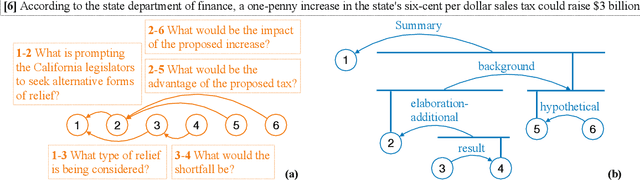

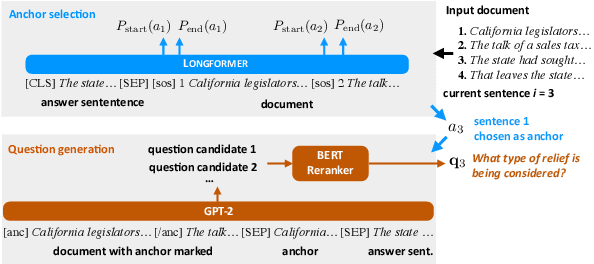
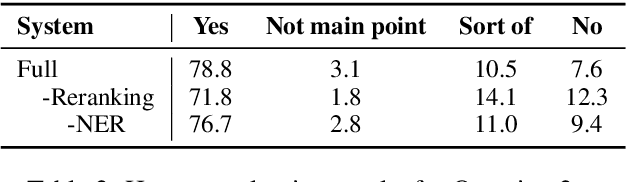
Automatic discourse processing, which can help understand how sentences connect to each other, is bottlenecked by data: current discourse formalisms pose highly demanding annotation tasks involving large taxonomies of discourse relations, making them inaccessible to lay annotators. This work instead adopts the linguistic framework of Questions Under Discussion (QUD) for discourse analysis and seeks to derive QUD structures automatically. QUD views each sentence as an answer to a question triggered in prior context; thus, we characterize relationships between sentences as free-form questions, in contrast to exhaustive fine-grained taxonomies. We develop the first-of-its-kind QUD parser that derives a dependency structure of questions over full documents, trained using a large question-answering dataset DCQA annotated in a manner consistent with the QUD framework. Importantly, data collection is easily crowdsourced using DCQA's paradigm. We show that this leads to a parser attaining strong performance according to human evaluation. We illustrate how our QUD structure is distinct from RST trees, and demonstrate the utility of QUD analysis in the context of document simplification. Our findings show that QUD parsing is an appealing alternative for automatic discourse processing.