 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Structured Meaning Representations with Aspect Classification
Mar 25, 2026To fully capture the meaning of a sentence, semantic representations should encode aspect, which describes the internal temporal structure of events. In graph-based meaning representation frameworks such as Uniform Meaning Representations (UMR), aspect lets one know how events unfold over time, including distinctions such as states, activities, and completed events. Despite its importance, aspect remains sparsely annotated across semantic meaning representation frameworks. This has, in turn, hindered not only current manual annotation, but also the development of automatic systems capable of predicting aspectual information. In this paper, we introduce a new dataset of English sentences annotated with UMR aspect labels over Abstract Meaning Representation (AMR) graphs that lack the feature. We describe the annotation scheme and guidelines used to label eventive predicates according to the UMR aspect lattice, as well as the annotation pipeline used to ensure consistency and quality across annotators through a multi-step adjudication process. To demonstrate the utility of our dataset for future automation, we present baseline experiments using three modeling approaches. Our results establish initial benchmarks for automatic UMR aspect prediction and provide a foundation for integrating aspect into semantic meaning representations more broadly.
Studying the Effects of Collaboration in Interactive Theme Discovery Systems
Aug 16, 2024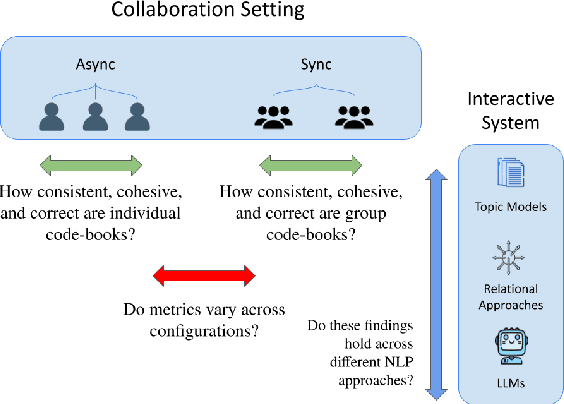

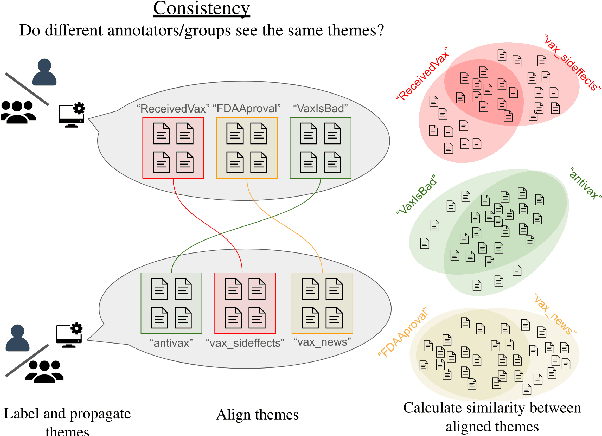
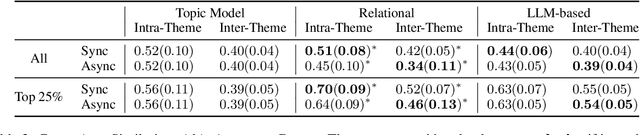
NLP-assisted solutions have gained considerable traction to support qualitative data analysis. However, there does not exist a unified evaluation framework that can account for the many different settings in which qualitative researchers may employ them. In this paper, we take a first step in this direction by proposing an evaluation framework to study the way in which different tools may result in different outcomes depending on the collaboration strategy employed. Specifically, we study the impact of synchronous vs. asynchronous collaboration using two different NLP-assisted qualitative research tools and present a comprehensive analysis of significant differences in the consistency, cohesiveness, and correctness of their outputs.
Mothman at SemEval-2024 Task 9: An Iterative System for Chain-of-Thought Prompt Optimization
May 03, 2024Extensive research exists on the performance of large language models on logic-based tasks, whereas relatively little has been done on their ability to generate creative solutions on lateral thinking tasks. The BrainTeaser shared task tests lateral thinking and uses adversarial datasets to prevent memorization, resulting in poor performance for out-of-the-box models. We propose a system for iterative, chain-of-thought prompt engineering which optimizes prompts using human evaluation. Using this shared task, we demonstrate our system's ability to significantly improve model performance by optimizing prompts and evaluate the input dataset.