 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOGICAL-COMMONSENSEQA: A Benchmark for Logical Commonsense Reasoning
Jan 23, 2026Commonsense reasoning often involves evaluating multiple plausible interpretations rather than selecting a single atomic answer, yet most benchmarks rely on single-label evaluation, obscuring whether statements are jointly plausible, mutually exclusive, or jointly implausible. We introduce LOGICAL-COMMONSENSEQA, a benchmark that re-frames commonsense reasoning as logical composition over pairs of atomic statements using plausibility-level operators (AND, OR, NEITHER/NOR). Evaluating instruction-tuned, reasoning-specialized, and fine-tuned models under zero-shot, few-shot, and chain-of-thought prompting, we find that while models perform reasonably on conjunctive and moderately on disjunctive reasoning, performance degrades sharply on negation-based questions. LOGICAL-COMMONSENSEQA exposes fundamental reasoning limitations and provides a controlled framework for advancing compositional commonsense reasoning.
How Do We Engage with Other Disciplines? A Framework to Study Meaningful Interdisciplinary Discourse in Scholarly Publications
Jan 15, 2026With the rising popularity of interdisciplinary work and increasing institutional incentives in this direction, there is a growing need to understand how resulting publications incorporate ideas from multiple disciplines. Existing computational approaches, such as affiliation diversity, keywords, and citation patterns, do not account for how individual citations are used to advance the citing work. Although, in line with addressing this gap, prior studies have proposed taxonomies to classify citation purpose, these frameworks are not well-suited to interdisciplinary research and do not provide quantitative measures of citation engagement quality. To address these limitations, we propose a framework for the evaluation of citation engagement in interdisciplinary Natural Language Processing (NLP) publications. Our approach introduces a citation purpose taxonomy tailored to interdisciplinary work, supported by an annotation study. We demonstrate the utility of this framework through a thorough analysis of publications at the intersection of NLP and Computational Social Science.
Mapping the Course for Prompt-based Structured Prediction
Aug 20, 2025LLMs have been shown to be useful for a variety of language tasks, without requiring task-specific fine-tuning. However, these models often struggle with hallucinations and complex reasoning problems due to their autoregressive nature. We propose to address some of these issues, specifically in the area of structured prediction, by combining LLMs with combinatorial inference in an attempt to marry the predictive power of LLMs with the structural consistency provided by inference methods. We perform exhaustive experiments in an effort to understand which prompting strategies can effectively estimate LLM confidence values for use with symbolic inference, and show that, regardless of the prompting strategy, the addition of symbolic inference on top of prompting alone leads to more consistent and accurate predictions. Additionally, we show that calibration and fine-tuning using structured prediction objectives leads to increased performance for challenging tasks, showing that structured learning is still valuable in the era of LLMs.
Explaining Hitori Puzzles: Neurosymbolic Proof Staging for Sequential Decisions
Aug 19, 2025We propose a neurosymbolic approach to the explanation of complex sequences of decisions that combines the strengths of decision procedures and Large Language Models (LLMs). We demonstrate this approach by producing explanations for the solutions of Hitori puzzles. The rules of Hitori include local constraints that are effectively explained by short resolution proofs. However, they also include a connectivity constraint that is more suitable for visual explanations. Hence, Hitori provides an excellent testing ground for a flexible combination of SAT solvers and LLMs. We have implemented a tool that assists humans in solving Hitori puzzles, and we present experimental evidence of its effectiveness.
Explaining Puzzle Solutions in Natural Language: An Exploratory Study on 6x6 Sudoku
May 21, 2025The success of Large Language Models (LLMs) in human-AI collaborative decision-making hinges on their ability to provide trustworthy, gradual, and tailored explanations. Solving complex puzzles, such as Sudoku, offers a canonical example of this collaboration, where clear and customized explanations often hold greater importance than the final solution. In this study, we evaluate the performance of five LLMs in solving and explaining \sixsix{} Sudoku puzzles. While one LLM demonstrates limited success in solving puzzles, none can explain the solution process in a manner that reflects strategic reasoning or intuitive problem-solving. These findings underscore significant challenges that must be addressed before LLMs can become effective partners in human-AI collaborative decision-making.
Can LLMs Interpret and Leverage Structured Linguistic Representations? A Case Study with AMRs
Apr 07, 2025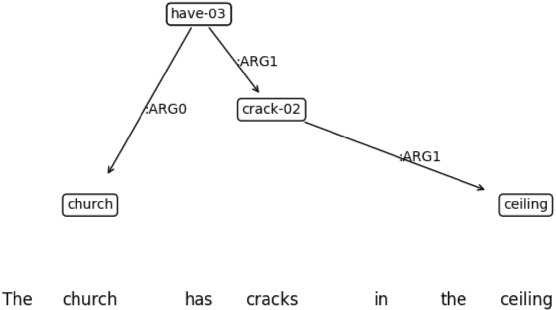
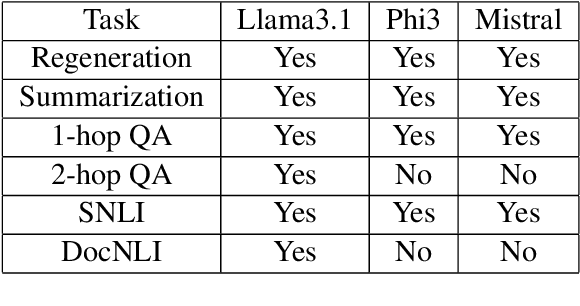
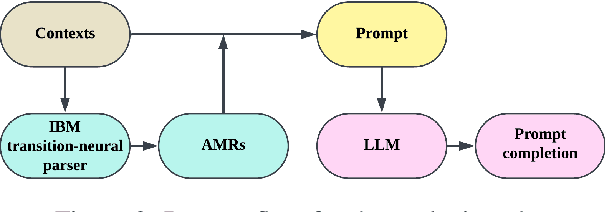
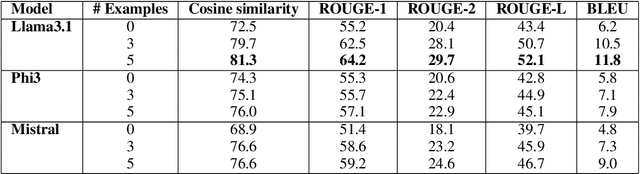
This paper evaluates the ability of Large Language Models (LLMs) to leverage contextual information in the form of structured linguistic representations. Specifically, we examine the impact of encoding both short and long contexts using Abstract Meaning Representation (AMR) structures across a diverse set of language tasks. We perform our analysis using 8-bit quantized and instruction-tuned versions of Llama 3.1 (8B), Phi-3, and Mistral 7B. Our results indicate that, for tasks involving short contexts, augmenting the prompt with the AMR of the original language context often degrades the performance of the underlying LLM. However, for tasks that involve long contexts, such as dialogue summarization in the SAMSum dataset, this enhancement improves LLM performance, for example, by increasing the zero-shot cosine similarity score of Llama 3.1 from 66.2% to 76%. This improvement is more evident in the newer and larger LLMs, but does not extend to the older or smaller ones. In addition, we observe that LLMs can effectively reconstruct the original text from a linearized AMR, achieving a cosine similarity of 81.3% in the best-case scenario.
All Entities are Not Created Equal: Examining the Long Tail for Fine-Grained Entity Typing
Oct 22, 2024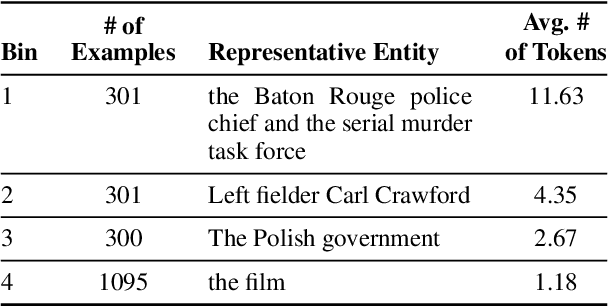
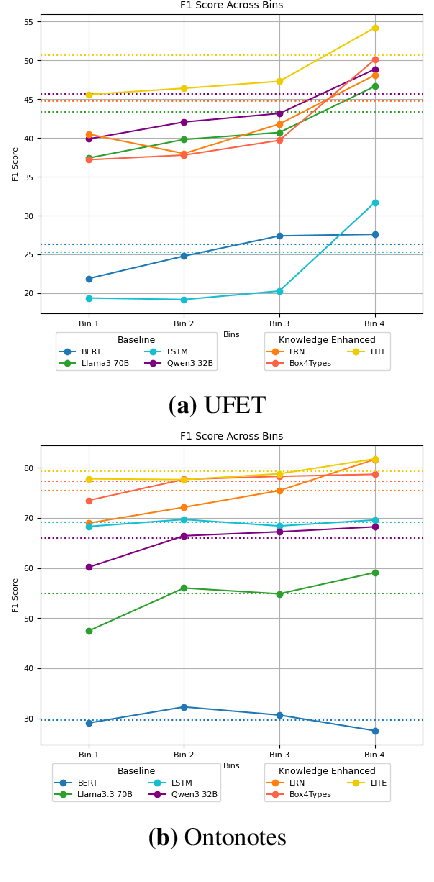
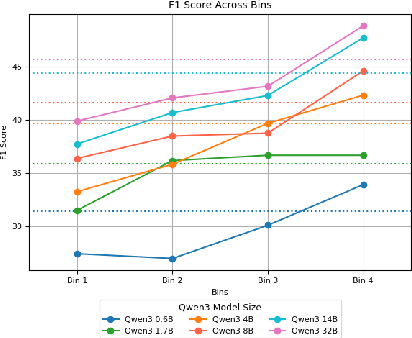
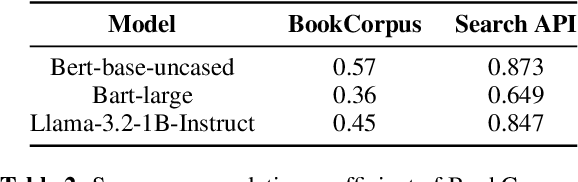
Pre-trained language models (PLMs) are trained on large amounts of data, which helps capture world knowledge alongside linguistic competence. Due to this, they are extensively used for ultra-fine entity typing tasks, where they provide the entity knowledge held in its parameter space. Given that PLMs learn from co-occurrence patterns, they likely contain more knowledge or less knowledge about entities depending on their how frequent they are in the pre-training data. In this work, we probe PLMs to elicit encoded entity probabilities and demonstrate that they highly correlate with their frequency in large-scale internet data. Then, we demonstrate that entity-typing approaches that rely on PLMs struggle with entities at the long tail on the distribution. Our findings suggests that we need to go beyond PLMs to produce solutions that perform well for rare, new or infrequent entities.
Media Framing through the Lens of Event-Centric Narratives
Oct 04, 2024



From a communications perspective, a frame defines the packaging of the language used in such a way as to encourage certain interpretations and to discourage others. For example, a news article can frame immigration as either a boost or a drain on the economy, and thus communicate very different interpretations of the same phenomenon. In this work, we argue that to explain framing devices we have to look at the way narratives are constructed. As a first step in this direction, we propose a framework that extracts events and their relations to other events, and groups them into high-level narratives that help explain frames in news articles. We show that our framework can be used to analyze framing in U.S. news for two different domains: immigration and gun control.
Studying the Effects of Collaboration in Interactive Theme Discovery Systems
Aug 16, 2024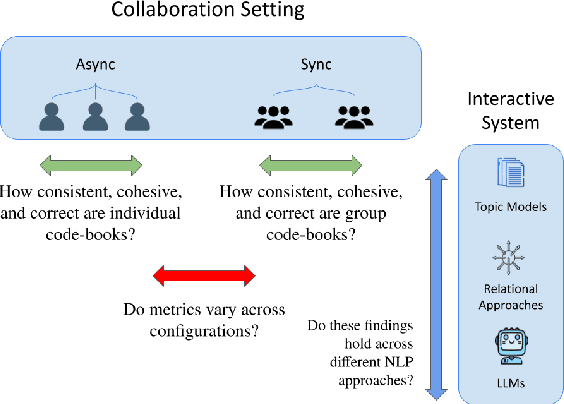

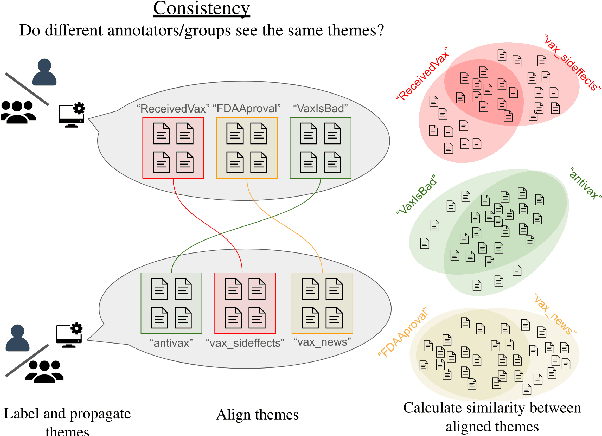
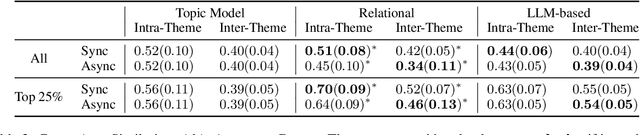
NLP-assisted solutions have gained considerable traction to support qualitative data analysis. However, there does not exist a unified evaluation framework that can account for the many different settings in which qualitative researchers may employ them. In this paper, we take a first step in this direction by proposing an evaluation framework to study the way in which different tools may result in different outcomes depending on the collaboration strategy employed. Specifically, we study the impact of synchronous vs. asynchronous collaboration using two different NLP-assisted qualitative research tools and present a comprehensive analysis of significant differences in the consistency, cohesiveness, and correctness of their outputs.
Framing in the Presence of Supporting Data: A Case Study in U.S. Economic News
Feb 23, 2024The mainstream media has much leeway in what it chooses to cover and how it covers it. These choices have real-world consequences on what people know and their subsequent behaviors. However, the lack of objective measures to evaluate editorial choices makes research in this area particularly difficult. In this paper, we argue that there are newsworthy topics where objective measures exist in the form of supporting data and propose a computational framework to analyze editorial choices in this setup. We focus on the economy because the reporting of economic indicators presents us with a relatively easy way to determine both the selection and framing of various publications. Their values provide a ground truth of how the economy is doing relative to how the publications choose to cover it. To do this, we define frame prediction as a set of interdependent tasks. At the article level, we learn to identify the reported stance towards the general state of the economy. Then, for every numerical quantity reported in the article, we learn to identify whether it corresponds to an economic indicator and whether it is being reported in a positive or negative way. To perform our analysis, we track six American publishers and each article that appeared in the top 10 slots of their landing page between 2015 and 2023.