 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Geometry, Performance, and Training in Language Models
Feb 24, 2026Geometric properties of Transformer weights, particularly the unembedding matrix, have been widely useful in language model interpretability research. Yet, their utility for estimating downstream performance remains unclear. In this work, we systematically investigate the relationship between model performance and the unembedding matrix geometry, particularly its effective rank. Our experiments, involving a suite of 108 OLMo-style language models trained under controlled variation, reveal several key findings. While the best-performing models often exhibit a high effective rank, this trend is not universal across tasks and training setups. Contrary to prior work, we find that low effective rank does not cause late-stage performance degradation in small models, but instead co-occurs with it; we find adversarial cases where low-rank models do not exhibit saturation. Moreover, we show that effective rank is strongly influenced by pre-training hyperparameters, such as batch size and weight decay, which in-turn affect the model's performance. Lastly, extending our analysis to other geometric metrics and final-layer representation, we find that these metrics are largely aligned, but none can reliably predict downstream performance. Overall, our findings suggest that the model's geometry, as captured by existing metrics, primarily reflects training choices rather than performance.
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Agree to Disagree? A Meta-Evaluation of LLM Misgendering
Apr 23, 2025Numerous methods have been proposed to measure LLM misgendering, including probability-based evaluations (e.g., automatically with templatic sentences) and generation-based evaluations (e.g., with automatic heuristics or human validation). However, it has gone unexamined whether these evaluation methods have convergent validity, that is, whether their results align. Therefore, we conduct a systematic meta-evaluation of these methods across three existing datasets for LLM misgendering. We propose a method to transform each dataset to enable parallel probability- and generation-based evaluation. Then, by automatically evaluating a suite of 6 models from 3 families, we find that these methods can disagree with each other at the instance, dataset, and model levels, conflicting on 20.2% of evaluation instances. Finally, with a human evaluation of 2400 LLM generations, we show that misgendering behaviour is complex and goes far beyond pronouns, which automatic evaluations are not currently designed to capture, suggesting essential disagreement with human evaluations. Based on our findings, we provide recommendations for future evaluations of LLM misgendering. Our results are also more widely relevant, as they call into question broader methodological conventions in LLM evaluation, which often assume that different evaluation methods agree.
auto-fpt: Automating Free Probability Theory Calculations for Machine Learning Theory
Apr 14, 2025A large part of modern machine learning theory often involves computing the high-dimensional expected trace of a rational expression of large rectangular random matrices. To symbolically compute such quantities using free probability theory, we introduce auto-fpt, a lightweight Python and SymPy-based tool that can automatically produce a reduced system of fixed-point equations which can be solved for the quantities of interest, and effectively constitutes a theory. We overview the algorithmic ideas underlying auto-fpt and its applications to various interesting problems, such as the high-dimensional error of linearized feed-forward neural networks, recovering well-known results. We hope that auto-fpt streamlines the majority of calculations involved in high-dimensional analysis, while helping the machine learning community reproduce known and uncover new phenomena.
Pairwise Matching of Intermediate Representations for Fine-grained Explainability
Mar 28, 2025



The differences between images belonging to fine-grained categories are often subtle and highly localized, and existing explainability techniques for deep learning models are often too diffuse to provide useful and interpretable explanations. We propose a new explainability method (PAIR-X) that leverages both intermediate model activations and backpropagated relevance scores to generate fine-grained, highly-localized pairwise visual explanations. We use animal and building re-identification (re-ID) as a primary case study of our method, and we demonstrate qualitatively improved results over a diverse set of explainability baselines on 35 public re-ID datasets. In interviews, animal re-ID experts were in unanimous agreement that PAIR-X was an improvement over existing baselines for deep model explainability, and suggested that its visualizations would be directly applicable to their work. We also propose a novel quantitative evaluation metric for our method, and demonstrate that PAIR-X visualizations appear more plausible for correct image matches than incorrect ones even when the model similarity score for the pairs is the same. By improving interpretability, PAIR-X enables humans to better distinguish correct and incorrect matches. Our code is available at: https://github.com/pairx-explains/pairx
Understanding "Democratization" in NLP and ML Research
Jun 17, 2024
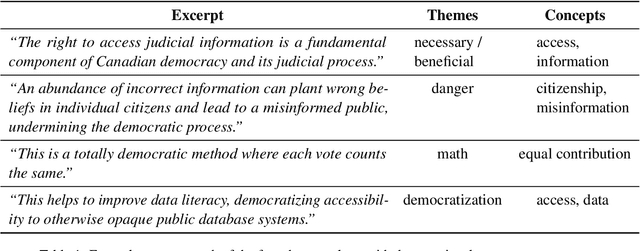
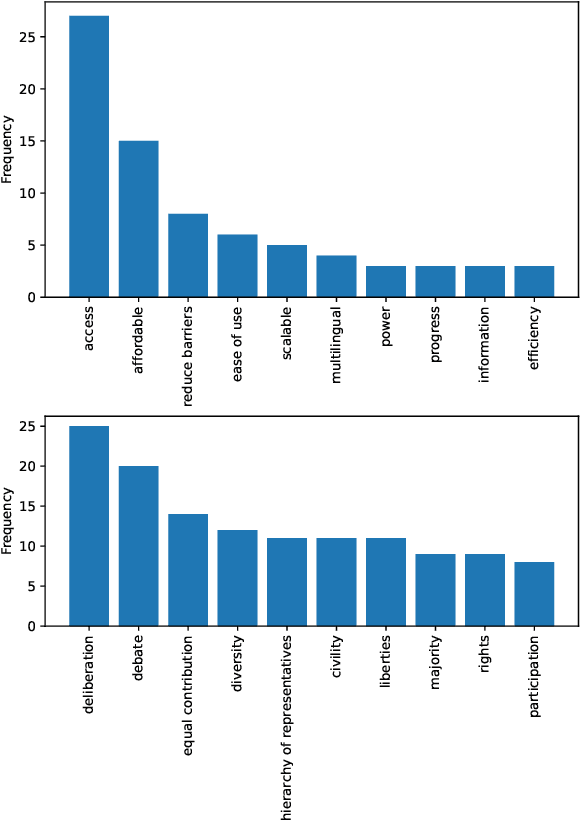
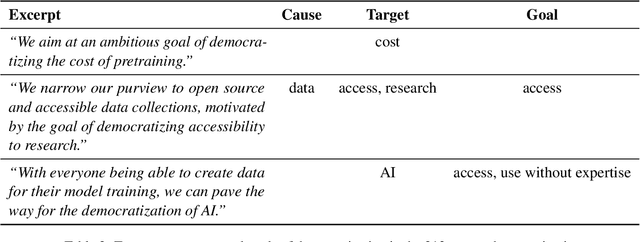
Recent improvements in natural language processing (NLP) and machine learning (ML) and increased mainstream adoption have led to researchers frequently discussing the "democratization" of artificial intelligence. In this paper, we seek to clarify how democratization is understood in NLP and ML publications, through large-scale mixed-methods analyses of papers using the keyword "democra*" published in NLP and adjacent venues. We find that democratization is most frequently used to convey (ease of) access to or use of technologies, without meaningfully engaging with theories of democratization, while research using other invocations of "democra*" tends to be grounded in theories of deliberation and debate. Based on our findings, we call for researchers to enrich their use of the term democratization with appropriate theory, towards democratic technologies beyond superficial access.
Stop! In the Name of Flaws: Disentangling Personal Names and Sociodemographic Attributes in NLP
May 27, 2024

Personal names simultaneously differentiate individuals and categorize them in ways that are important in a given society. While the natural language processing community has thus associated personal names with sociodemographic characteristics in a variety of tasks, researchers have engaged to varying degrees with the established methodological problems in doing so. To guide future work, we present an interdisciplinary background on names and naming. We then survey the issues inherent to associating names with sociodemographic attributes, covering problems of validity (e.g., systematic error, construct validity), as well as ethical concerns (e.g., harms, differential impact, cultural insensitivity). Finally, we provide guiding questions along with normative recommendations to avoid validity and ethical pitfalls when dealing with names and sociodemographic characteristics in natural language processing.
Theoretical and Empirical Insights into the Origins of Degree Bias in Graph Neural Networks
Apr 04, 2024Graph Neural Networks (GNNs) often perform better for high-degree nodes than low-degree nodes on node classification tasks. This degree bias can reinforce social marginalization by, e.g., sidelining authors of lowly-cited papers when predicting paper topics in citation networks. While researchers have proposed numerous hypotheses for why GNN degree bias occurs, we find via a survey of 38 degree bias papers that these hypotheses are often not rigorously validated, and can even be contradictory. Thus, we provide an analysis of the origins of degree bias in message-passing GNNs with different graph filters. We prove that high-degree test nodes tend to have a lower probability of misclassification regardless of how GNNs are trained. Moreover, we show that degree bias arises from a variety of factors that are associated with a node's degree (e.g., homophily of neighbors, diversity of neighbors). Furthermore, we show that during training, some GNNs may adjust their loss on low-degree nodes more slowly than on high-degree nodes; however, with sufficiently many epochs of training, message-passing GNNs can achieve their maximum possible training accuracy, which is not significantly limited by their expressive power. Throughout our analysis, we connect our findings to previously-proposed hypotheses for the origins of degree bias, supporting and unifying some while drawing doubt to others. We validate our theoretical findings on 8 common real-world networks, and based on our theoretical and empirical insights, describe a roadmap to alleviate degree bias.
Survey of Bias In Text-to-Image Generation: Definition, Evaluation, and Mitigation
Apr 02, 2024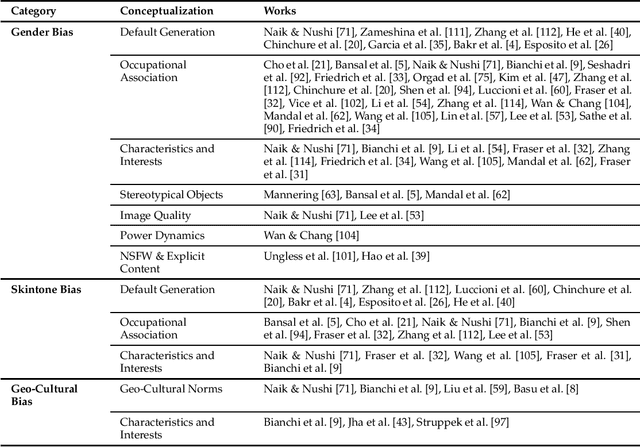

The recent advancement of large and powerful models with Text-to-Image (T2I) generation abilities -- such as OpenAI's DALLE-3 and Google's Gemini -- enables users to generate high-quality images from textual prompts. However, it has become increasingly evident that even simple prompts could cause T2I models to exhibit conspicuous social bias in generated images. Such bias might lead to both allocational and representational harms in society, further marginalizing minority groups. Noting this problem, a large body of recent works has been dedicated to investigating different dimensions of bias in T2I systems. However, an extensive review of these studies is lacking, hindering a systematic understanding of current progress and research gaps. We present the first extensive survey on bias in T2I generative models. In this survey, we review prior studies on dimensions of bias: Gender, Skintone, and Geo-Culture. Specifically, we discuss how these works define, evaluate, and mitigate different aspects of bias. We found that: (1) while gender and skintone biases are widely studied, geo-cultural bias remains under-explored; (2) most works on gender and skintone bias investigated occupational association, while other aspects are less frequently studied; (3) almost all gender bias works overlook non-binary identities in their studies; (4) evaluation datasets and metrics are scattered, with no unified framework for measuring biases; and (5) current mitigation methods fail to resolve biases comprehensively. Based on current limitations, we point out future research directions that contribute to human-centric definitions, evaluations, and mitigation of biases. We hope to highlight the importance of studying biases in T2I systems, as well as encourage future efforts to holistically understand and tackle biases, building fair and trustworthy T2I technologies for everyone.
Networked Inequality: Preferential Attachment Bias in Graph Neural Network Link Prediction
Sep 29, 2023
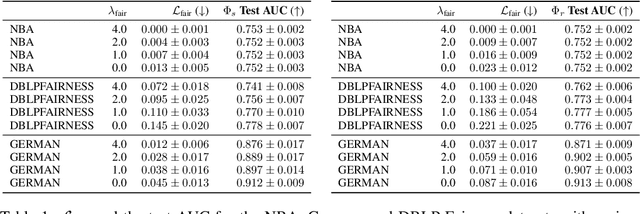
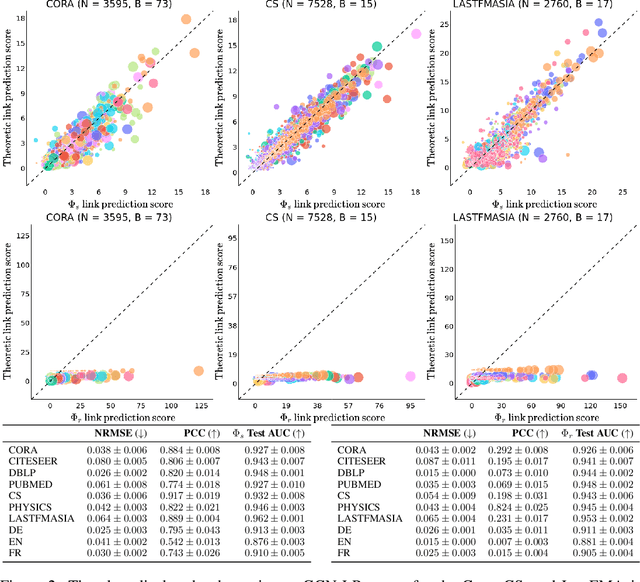
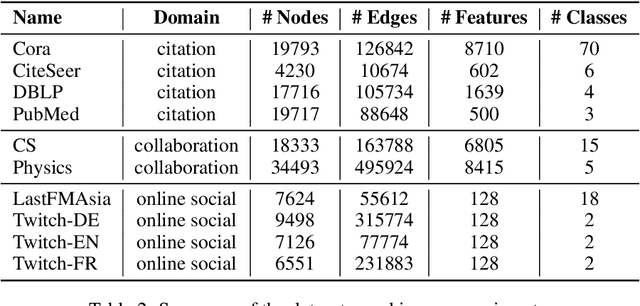
Graph neural network (GNN) link prediction is increasingly deployed in citation, collaboration, and online social networks to recommend academic literature, collaborators, and friends. While prior research has investigated the dyadic fairness of GNN link prediction, the within-group fairness and ``rich get richer'' dynamics of link prediction remain underexplored. However, these aspects have significant consequences for degree and power imbalances in networks. In this paper, we shed light on how degree bias in networks affects Graph Convolutional Network (GCN) link prediction. In particular, we theoretically uncover that GCNs with a symmetric normalized graph filter have a within-group preferential attachment bias. We validate our theoretical analysis on real-world citation, collaboration, and online social networks. We further bridge GCN's preferential attachment bias with unfairness in link prediction and propose a new within-group fairness metric. This metric quantifies disparities in link prediction scores between social groups, towards combating the amplification of degree and power disparities. Finally, we propose a simple training-time strategy to alleviate within-group unfairness, and we show that it is effective on citation, online social, and credit networks.