 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Delivery Service: Epistemic limits of passive data collection in complex social systems
Nov 20, 2024Rapid model validation via the train-test paradigm has been a key driver for the breathtaking progress in machine learning and AI. However, modern AI systems often depend on a combination of tasks and data collection practices that violate all assumptions ensuring test validity. Yet, without rigorous model validation we cannot ensure the intended outcomes of deployed AI systems, including positive social impact, nor continue to advance AI research in a scientifically sound way. In this paper, I will show that for widely considered inference settings in complex social systems the train-test paradigm does not only lack a justification but is indeed invalid for any risk estimator, including counterfactual and causal estimators, with high probability. These formal impossibility results highlight a fundamental epistemic issue, i.e., that for key tasks in modern AI we cannot know whether models are valid under current data collection practices. Importantly, this includes variants of both recommender systems and reasoning via large language models, and neither na\"ive scaling nor limited benchmarks are suited to address this issue. I am illustrating these results via the widely used MovieLens benchmark and conclude by discussing the implications of these results for AI in social systems, including possible remedies such as participatory data curation and open science.
System-2 Recommenders: Disentangling Utility and Engagement in Recommendation Systems via Temporal Point-Processes
May 29, 2024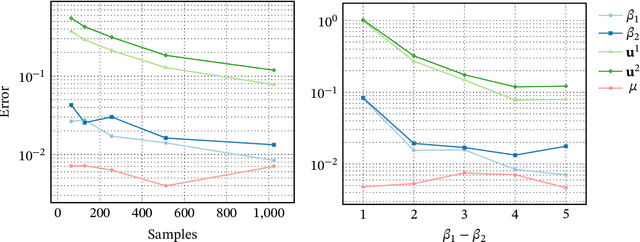
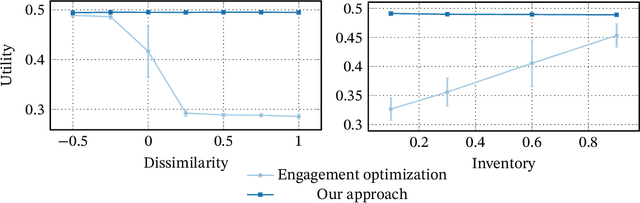
Recommender systems are an important part of the modern human experience whose influence ranges from the food we eat to the news we read. Yet, there is still debate as to what extent recommendation platforms are aligned with the user goals. A core issue fueling this debate is the challenge of inferring a user utility based on engagement signals such as likes, shares, watch time etc., which are the primary metric used by platforms to optimize content. This is because users utility-driven decision-processes (which we refer to as System-2), e.g., reading news that are relevant for them, are often confounded by their impulsive decision-processes (which we refer to as System-1), e.g., spend time on click-bait news. As a result, it is difficult to infer whether an observed engagement is utility-driven or impulse-driven. In this paper we explore a new approach to recommender systems where we infer user utility based on their return probability to the platform rather than engagement signals. Our intuition is that users tend to return to a platform in the long run if it creates utility for them, while pure engagement-driven interactions that do not add utility, may affect user return in the short term but will not have a lasting effect. We propose a generative model in which past content interactions impact the arrival rates of users based on a self-exciting Hawkes process. These arrival rates to the platform are a combination of both System-1 and System-2 decision processes. The System-2 arrival intensity depends on the utility and has a long lasting effect, while the System-1 intensity depends on the instantaneous gratification and tends to vanish rapidly. We show analytically that given samples it is possible to disentangle System-1 and System-2 and allow content optimization based on user utility. We conduct experiments on synthetic data to demonstrate the effectiveness of our approach.
Assessing Neural Network Representations During Training Using Noise-Resilient Diffusion Spectral Entropy
Dec 04, 2023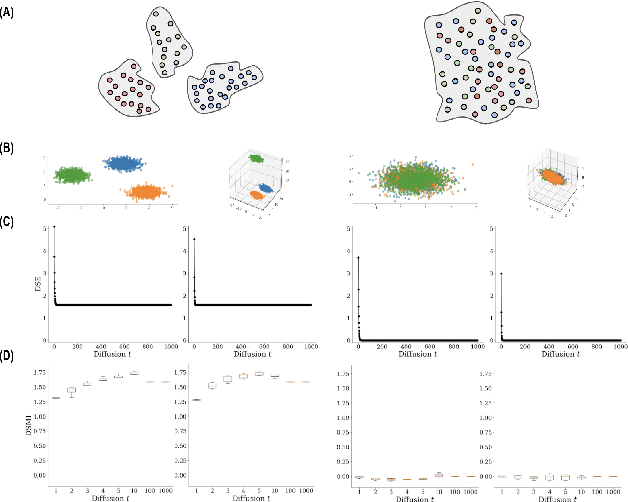

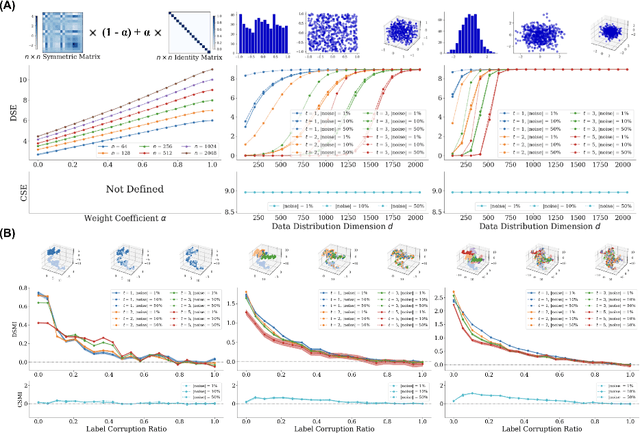

Entropy and mutual information in neural networks provide rich information on the learning process, but they have proven difficult to compute reliably in high dimensions. Indeed, in noisy and high-dimensional data, traditional estimates in ambient dimensions approach a fixed entropy and are prohibitively hard to compute. To address these issues, we leverage data geometry to access the underlying manifold and reliably compute these information-theoretic measures. Specifically, we define diffusion spectral entropy (DSE) in neural representations of a dataset as well as diffusion spectral mutual information (DSMI) between different variables representing data. First, we show that they form noise-resistant measures of intrinsic dimensionality and relationship strength in high-dimensional simulated data that outperform classic Shannon entropy, nonparametric estimation, and mutual information neural estimation (MINE). We then study the evolution of representations in classification networks with supervised learning, self-supervision, or overfitting. We observe that (1) DSE of neural representations increases during training; (2) DSMI with the class label increases during generalizable learning but stays stagnant during overfitting; (3) DSMI with the input signal shows differing trends: on MNIST it increases, while on CIFAR-10 and STL-10 it decreases. Finally, we show that DSE can be used to guide better network initialization and that DSMI can be used to predict downstream classification accuracy across 962 models on ImageNet. The official implementation is available at https://github.com/ChenLiu-1996/DiffusionSpectralEntropy.
Generalized Schrödinger Bridge Matching
Oct 03, 2023Modern distribution matching algorithms for training diffusion or flow models directly prescribe the time evolution of the marginal distributions between two boundary distributions. In this work, we consider a generalized distribution matching setup, where these marginals are only implicitly described as a solution to some task-specific objective function. The problem setup, known as the Generalized Schr\"odinger Bridge (GSB), appears prevalently in many scientific areas both within and without machine learning. We propose Generalized Schr\"odinger Bridge Matching (GSBM), a new matching algorithm inspired by recent advances, generalizing them beyond kinetic energy minimization and to account for task-specific state costs. We show that such a generalization can be cast as solving conditional stochastic optimal control, for which efficient variational approximations can be used, and further debiased with the aid of path integral theory. Compared to prior methods for solving GSB problems, our GSBM algorithm always preserves a feasible transport map between the boundary distributions throughout training, thereby enabling stable convergence and significantly improved scalability. We empirically validate our claims on an extensive suite of experimental setups, including crowd navigation, opinion depolarization, LiDAR manifolds, and image domain transfer. Our work brings new algorithmic opportunities for training diffusion models enhanced with task-specific optimality structures.
Graph topological property recovery with heat and wave dynamics-based features on graphs
Sep 19, 2023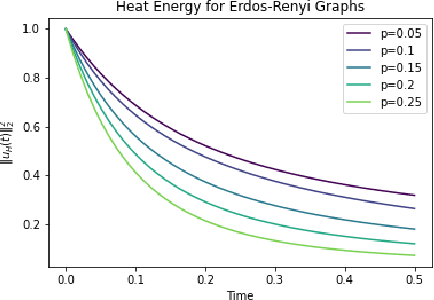
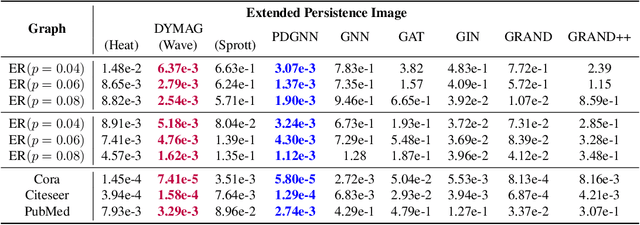
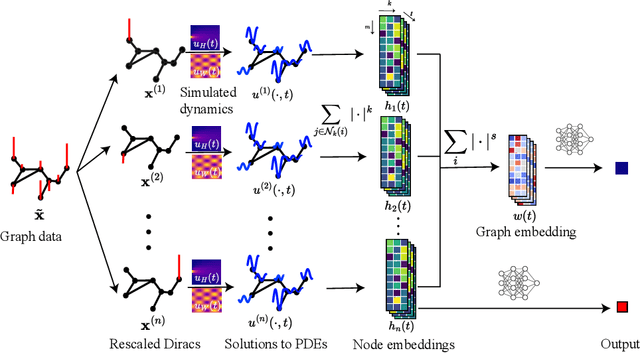
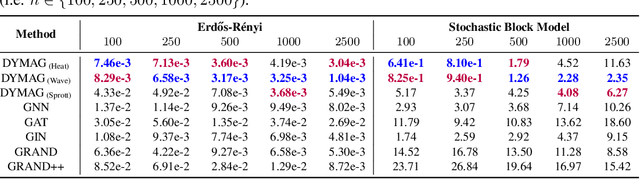
In this paper, we propose Graph Differential Equation Network (GDeNet), an approach that harnesses the expressive power of solutions to PDEs on a graph to obtain continuous node- and graph-level representations for various downstream tasks. We derive theoretical results connecting the dynamics of heat and wave equations to the spectral properties of the graph and to the behavior of continuous-time random walks on graphs. We demonstrate experimentally that these dynamics are able to capture salient aspects of graph geometry and topology by recovering generating parameters of random graphs, Ricci curvature, and persistent homology. Furthermore, we demonstrate the superior performance of GDeNet on real-world datasets including citation graphs, drug-like molecules, and proteins.
Weisfeiler and Lehman Go Measurement Modeling: Probing the Validity of the WL Test
Jul 11, 2023The expressive power of graph neural networks is usually measured by comparing how many pairs of graphs or nodes an architecture can possibly distinguish as non-isomorphic to those distinguishable by the $k$-dimensional Weisfeiler-Lehman ($k$-WL) test. In this paper, we uncover misalignments between practitioners' conceptualizations of expressive power and $k$-WL through a systematic analysis of the reliability and validity of $k$-WL. We further conduct a survey ($n = 18$) of practitioners to surface their conceptualizations of expressive power and their assumptions about $k$-WL. In contrast to practitioners' opinions, our analysis (which draws from graph theory and benchmark auditing) reveals that $k$-WL does not guarantee isometry, can be irrelevant to real-world graph tasks, and may not promote generalization or trustworthiness. We argue for extensional definitions and measurement of expressive power based on benchmarks; we further contribute guiding questions for constructing such benchmarks, which is critical for progress in graph machine learning.
Neural FIM for learning Fisher Information Metrics from point cloud data
Jun 12, 2023Although data diffusion embeddings are ubiquitous in unsupervised learning and have proven to be a viable technique for uncovering the underlying intrinsic geometry of data, diffusion embeddings are inherently limited due to their discrete nature. To this end, we propose neural FIM, a method for computing the Fisher information metric (FIM) from point cloud data - allowing for a continuous manifold model for the data. Neural FIM creates an extensible metric space from discrete point cloud data such that information from the metric can inform us of manifold characteristics such as volume and geodesics. We demonstrate Neural FIM's utility in selecting parameters for the PHATE visualization method as well as its ability to obtain information pertaining to local volume illuminating branching points and cluster centers embeddings of a toy dataset and two single-cell datasets of IPSC reprogramming and PBMCs (immune cells).
On Kinetic Optimal Probability Paths for Generative Models
Jun 11, 2023Recent successful generative models are trained by fitting a neural network to an a-priori defined tractable probability density path taking noise to training examples. In this paper we investigate the space of Gaussian probability paths, which includes diffusion paths as an instance, and look for an optimal member in some useful sense. In particular, minimizing the Kinetic Energy (KE) of a path is known to make particles' trajectories simple, hence easier to sample, and empirically improve performance in terms of likelihood of unseen data and sample generation quality. We investigate Kinetic Optimal (KO) Gaussian paths and offer the following observations: (i) We show the KE takes a simplified form on the space of Gaussian paths, where the data is incorporated only through a single, one dimensional scalar function, called the \emph{data separation function}. (ii) We characterize the KO solutions with a one dimensional ODE. (iii) We approximate data-dependent KO paths by approximating the data separation function and minimizing the KE. (iv) We prove that the data separation function converges to $1$ in the general case of arbitrary normalized dataset consisting of $n$ samples in $d$ dimension as $n/\sqrt{d}\rightarrow 0$. A consequence of this result is that the Conditional Optimal Transport (Cond-OT) path becomes \emph{kinetic optimal} as $n/\sqrt{d}\rightarrow 0$. We further support this theory with empirical experiments on ImageNet.
Hyperbolic Image-Text Representations
Apr 18, 2023Visual and linguistic concepts naturally organize themselves in a hierarchy, where a textual concept ``dog'' entails all images that contain dogs. Despite being intuitive, current large-scale vision and language models such as CLIP do not explicitly capture such hierarchy. We propose MERU, a contrastive model that yields hyperbolic representations of images and text. Hyperbolic spaces have suitable geometric properties to embed tree-like data, so MERU can better capture the underlying hierarchy in image-text data. Our results show that MERU learns a highly interpretable representation space while being competitive with CLIP's performance on multi-modal tasks like image classification and image-text retrieval.
Latent Discretization for Continuous-time Sequence Compression
Dec 28, 2022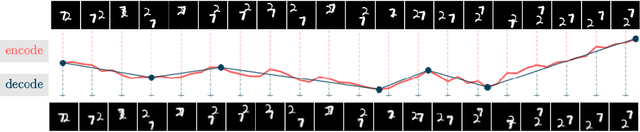

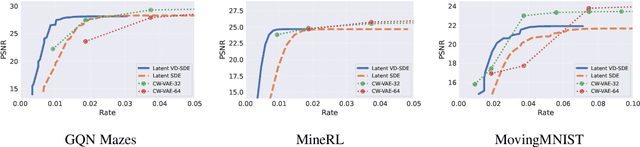
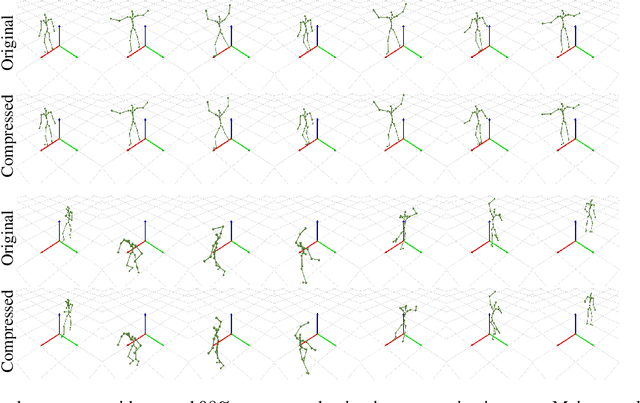
Neural compression offers a domain-agnostic approach to creating codecs for lossy or lossless compression via deep generative models. For sequence compression, however, most deep sequence models have costs that scale with the sequence length rather than the sequence complexity. In this work, we instead treat data sequences as observations from an underlying continuous-time process and learn how to efficiently discretize while retaining information about the full sequence. As a consequence of decoupling sequential information from its temporal discretization, our approach allows for greater compression rates and smaller computational complexity. Moreover, the continuous-time approach naturally allows us to decode at different time intervals. We empirically verify our approach on multiple domains involving compression of video and motion capture sequences, showing that our approaches can automatically achieve reductions in bit rates by learning how to discretize.