 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowDec: A flow-based full-band general audio codec with high perceptual quality
Mar 03, 2025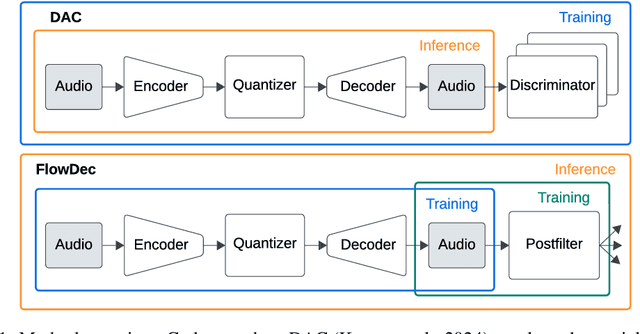

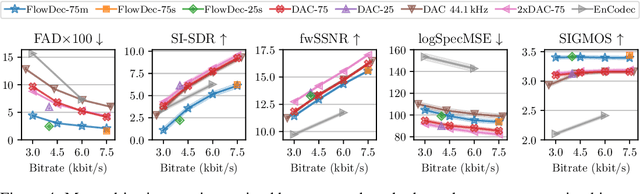
We propose FlowDec, a neural full-band audio codec for general audio sampled at 48 kHz that combines non-adversarial codec training with a stochastic postfilter based on a novel conditional flow matching method. Compared to the prior work ScoreDec which is based on score matching, we generalize from speech to general audio and move from 24 kbit/s to as low as 4 kbit/s, while improving output quality and reducing the required postfilter DNN evaluations from 60 to 6 without any fine-tuning or distillation techniques. We provide theoretical insights and geometric intuitions for our approach in comparison to ScoreDec as well as another recent work that uses flow matching, and conduct ablation studies on our proposed components. We show that FlowDec is a competitive alternative to the recent GAN-dominated stream of neural codecs, achieving FAD scores better than those of the established GAN-based codec DAC and listening test scores that are on par, and producing qualitatively more natural reconstructions for speech and harmonic structures in music.
Audiobox TTA-RAG: Improving Zero-Shot and Few-Shot Text-To-Audio with Retrieval-Augmented Generation
Nov 07, 2024Current leading Text-To-Audio (TTA) generation models suffer from degraded performance on zero-shot and few-shot settings. It is often challenging to generate high-quality audio for audio events that are unseen or uncommon in the training set. Inspired by the success of Retrieval-Augmented Generation (RAG) in Large Language Model (LLM)-based knowledge-intensive tasks, we extend the TTA process with additional conditioning contexts. We propose Audiobox TTA-RAG, a novel retrieval-augmented TTA approach based on Audiobox, a conditional flow-matching audio generation model. Unlike the vanilla Audiobox TTA solution which generates audio conditioned on text, we augmented the conditioning input with retrieved audio samples that provide additional acoustic information to generate the target audio. Our retrieval method does not require the external database to have labeled audio, offering more practical use cases. To evaluate our proposed method, we curated test sets in zero-shot and few-shot settings. Our empirical results show that the proposed model can effectively leverage the retrieved audio samples and significantly improve zero-shot and few-shot TTA performance, with large margins on multiple evaluation metrics, while maintaining the ability to generate semantically aligned audio for the in-domain setting. In addition, we investigate the effect of different retrieval methods and data sources.
Bespoke Non-Stationary Solvers for Fast Sampling of Diffusion and Flow Models
Mar 02, 2024This paper introduces Bespoke Non-Stationary (BNS) Solvers, a solver distillation approach to improve sample efficiency of Diffusion and Flow models. BNS solvers are based on a family of non-stationary solvers that provably subsumes existing numerical ODE solvers and consequently demonstrate considerable improvement in sample approximation (PSNR) over these baselines. Compared to model distillation, BNS solvers benefit from a tiny parameter space ($<$200 parameters), fast optimization (two orders of magnitude faster), maintain diversity of samples, and in contrast to previous solver distillation approaches nearly close the gap from standard distillation methods such as Progressive Distillation in the low-medium NFE regime. For example, BNS solver achieves 45 PSNR / 1.76 FID using 16 NFE in class-conditional ImageNet-64. We experimented with BNS solvers for conditional image generation, text-to-image generation, and text-2-audio generation showing significant improvement in sample approximation (PSNR) in all.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023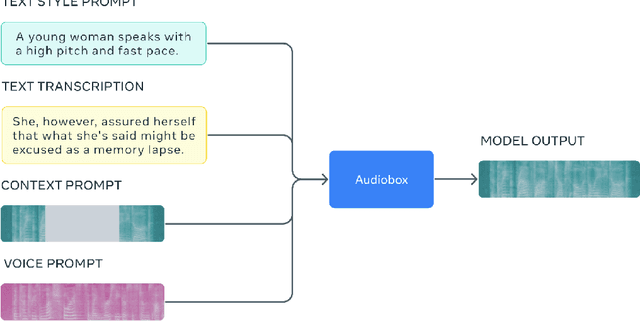


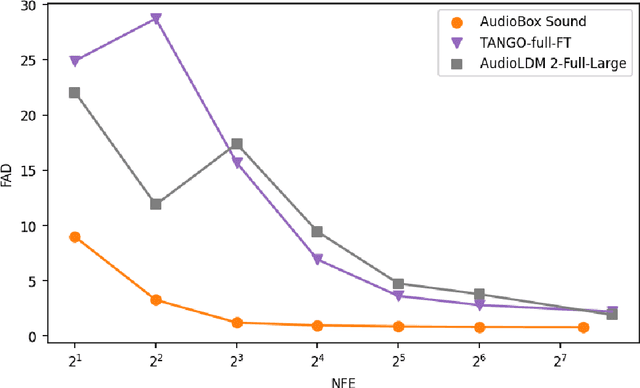
Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
Jun 23, 2023Large-scale generative models such as GPT and DALL-E have revolutionized natural language processing and computer vision research. These models not only generate high fidelity text or image outputs, but are also generalists which can solve tasks not explicitly taught. In contrast, speech generative models are still primitive in terms of scale and task generalization. In this paper, we present Voicebox, the most versatile text-guided generative model for speech at scale. Voicebox is a non-autoregressive flow-matching model trained to infill speech, given audio context and text, trained on over 50K hours of speech that are neither filtered nor enhanced. Similar to GPT, Voicebox can perform many different tasks through in-context learning, but is more flexible as it can also condition on future context. Voicebox can be used for mono or cross-lingual zero-shot text-to-speech synthesis, noise removal, content editing, style conversion, and diverse sample generation. In particular, Voicebox outperforms the state-of-the-art zero-shot TTS model VALL-E on both intelligibility (5.9% vs 1.9% word error rates) and audio similarity (0.580 vs 0.681) while being up to 20 times faster. See voicebox.metademolab.com for a demo of the model.
Latent Discretization for Continuous-time Sequence Compression
Dec 28, 2022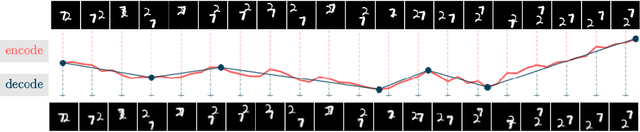

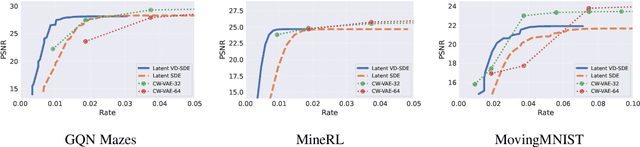
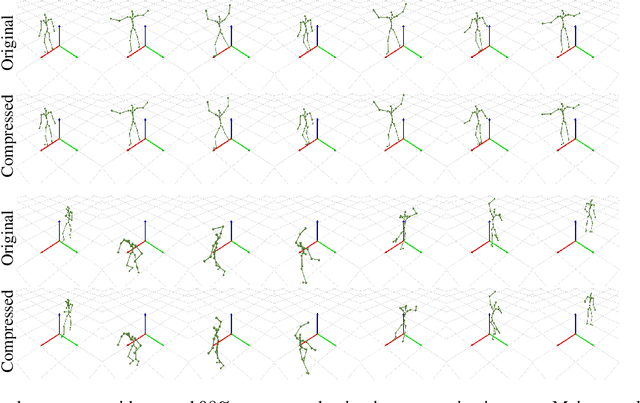
Neural compression offers a domain-agnostic approach to creating codecs for lossy or lossless compression via deep generative models. For sequence compression, however, most deep sequence models have costs that scale with the sequence length rather than the sequence complexity. In this work, we instead treat data sequences as observations from an underlying continuous-time process and learn how to efficiently discretize while retaining information about the full sequence. As a consequence of decoupling sequential information from its temporal discretization, our approach allows for greater compression rates and smaller computational complexity. Moreover, the continuous-time approach naturally allows us to decode at different time intervals. We empirically verify our approach on multiple domains involving compression of video and motion capture sequences, showing that our approaches can automatically achieve reductions in bit rates by learning how to discretize.
Learning Multivariate Hawkes Processes at Scale
Feb 28, 2020



Multivariate Hawkes Processes (MHPs) are an important class of temporal point processes that have enabled key advances in understanding and predicting social information systems. However, due to their complex modeling of temporal dependencies, MHPs have proven to be notoriously difficult to scale, what has limited their applications to relatively small domains. In this work, we propose a novel model and computational approach to overcome this important limitation. By exploiting a characteristic sparsity pattern in real-world diffusion processes, we show that our approach allows to compute the exact likelihood and gradients of an MHP -- independently of the ambient dimensions of the underlying network. We show on synthetic and real-world datasets that our model does not only achieve state-of-the-art predictive results, but also improves runtime performance by multiple orders of magnitude compared to standard methods on sparse event sequences. In combination with easily interpretable latent variables and influence structures, this allows us to analyze diffusion processes at previously unattainable scale.