 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Streamable Generative Speech Restoration with Flow Matching
Dec 22, 2025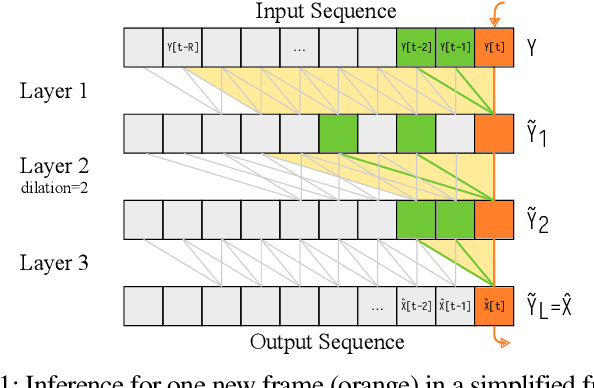
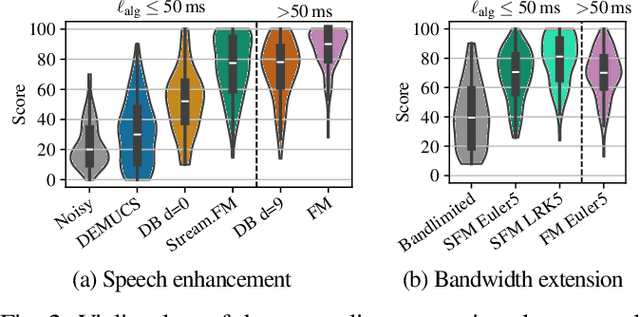

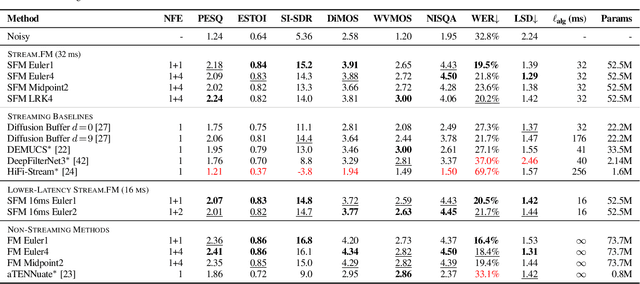
Diffusion-based generative models have greatly impacted the speech processing field in recent years, exhibiting high speech naturalness and spawning a new research direction. Their application in real-time communication is, however, still lagging behind due to their computation-heavy nature involving multiple calls of large DNNs. Here, we present Stream.FM, a frame-causal flow-based generative model with an algorithmic latency of 32 milliseconds (ms) and a total latency of 48 ms, paving the way for generative speech processing in real-time communication. We propose a buffered streaming inference scheme and an optimized DNN architecture, show how learned few-step numerical solvers can boost output quality at a fixed compute budget, explore model weight compression to find favorable points along a compute/quality tradeoff, and contribute a model variant with 24 ms total latency for the speech enhancement task. Our work looks beyond theoretical latencies, showing that high-quality streaming generative speech processing can be realized on consumer GPUs available today. Stream.FM can solve a variety of speech processing tasks in a streaming fashion: speech enhancement, dereverberation, codec post-filtering, bandwidth extension, STFT phase retrieval, and Mel vocoding. As we verify through comprehensive evaluations and a MUSHRA listening test, Stream.FM establishes a state-of-the-art for generative streaming speech restoration, exhibits only a reasonable reduction in quality compared to a non-streaming variant, and outperforms our recent work (Diffusion Buffer) on generative streaming speech enhancement while operating at a lower latency.
Real-Time Streaming Mel Vocoding with Generative Flow Matching
Sep 18, 2025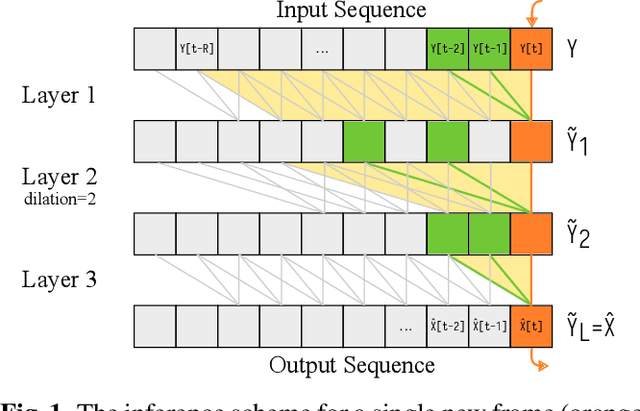
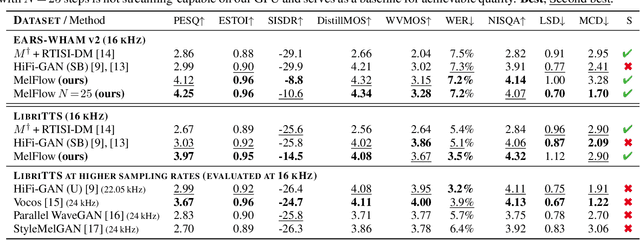
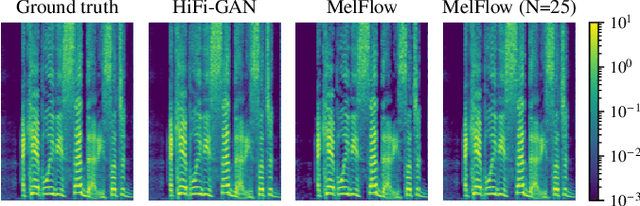
The task of Mel vocoding, i.e., the inversion of a Mel magnitude spectrogram to an audio waveform, is still a key component in many text-to-speech (TTS) systems today. Based on generative flow matching, our prior work on generative STFT phase retrieval (DiffPhase), and the pseudoinverse operator of the Mel filterbank, we develop MelFlow, a streaming-capable generative Mel vocoder for speech sampled at 16 kHz with an algorithmic latency of only 32 ms and a total latency of 48 ms. We show real-time streaming capability at this latency not only in theory, but in practice on a consumer laptop GPU. Furthermore, we show that our model achieves substantially better PESQ and SI-SDR values compared to well-established not streaming-capable baselines for Mel vocoding including HiFi-GAN.
FlowDec: A flow-based full-band general audio codec with high perceptual quality
Mar 03, 2025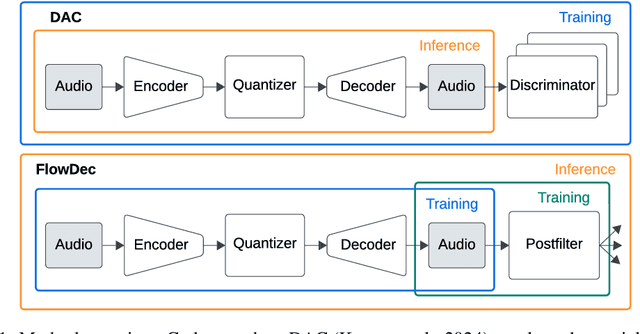

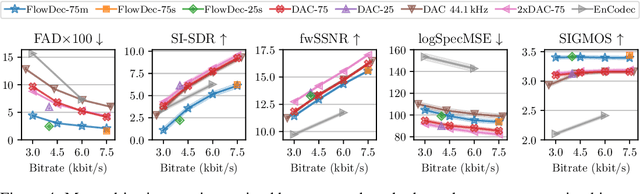
We propose FlowDec, a neural full-band audio codec for general audio sampled at 48 kHz that combines non-adversarial codec training with a stochastic postfilter based on a novel conditional flow matching method. Compared to the prior work ScoreDec which is based on score matching, we generalize from speech to general audio and move from 24 kbit/s to as low as 4 kbit/s, while improving output quality and reducing the required postfilter DNN evaluations from 60 to 6 without any fine-tuning or distillation techniques. We provide theoretical insights and geometric intuitions for our approach in comparison to ScoreDec as well as another recent work that uses flow matching, and conduct ablation studies on our proposed components. We show that FlowDec is a competitive alternative to the recent GAN-dominated stream of neural codecs, achieving FAD scores better than those of the established GAN-based codec DAC and listening test scores that are on par, and producing qualitatively more natural reconstructions for speech and harmonic structures in music.
Non-intrusive Speech Quality Assessment with Diffusion Models Trained on Clean Speech
Oct 23, 2024



Diffusion models have found great success in generating high quality, natural samples of speech, but their potential for density estimation for speech has so far remained largely unexplored. In this work, we leverage an unconditional diffusion model trained only on clean speech for the assessment of speech quality. We show that the quality of a speech utterance can be assessed by estimating the likelihood of a corresponding sample in the terminating Gaussian distribution, obtained via a deterministic noising process. The resulting method is purely unsupervised, trained only on clean speech, and therefore does not rely on annotations. Our diffusion-based approach leverages clean speech priors to assess quality based on how the input relates to the learned distribution of clean data. Our proposed log-likelihoods show promising results, correlating well with intrusive speech quality metrics such as POLQA and SI-SDR.
Unsupervised Blind Joint Dereverberation and Room Acoustics Estimation with Diffusion Models
Aug 14, 2024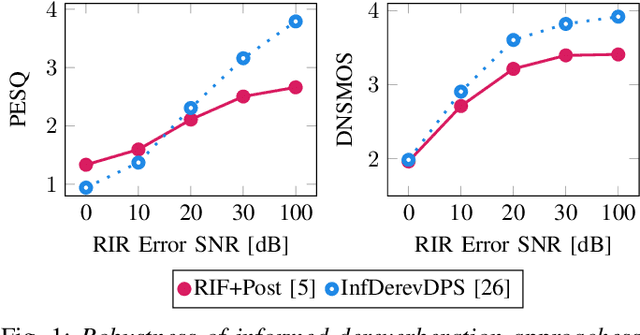
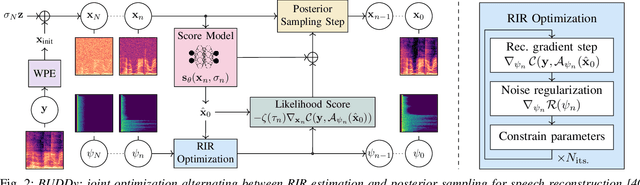
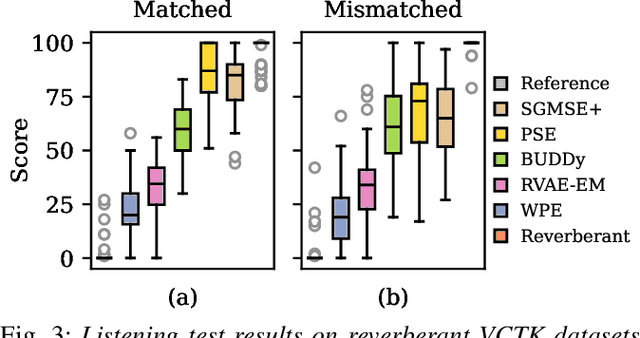
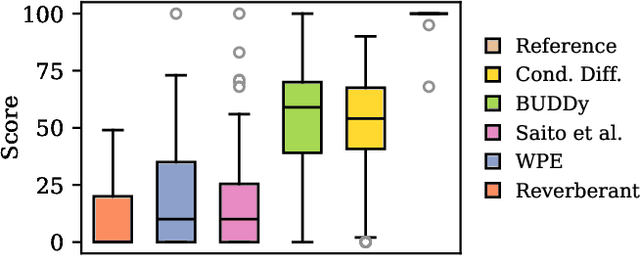
This paper presents an unsupervised method for single-channel blind dereverberation and room impulse response (RIR) estimation, called BUDDy. The algorithm is rooted in Bayesian posterior sampling: it combines a likelihood model enforcing fidelity to the reverberant measurement, and an anechoic speech prior implemented by an unconditional diffusion model. We design a parametric filter representing the RIR, with exponential decay for each frequency subband. Room acoustics estimation and speech dereverberation are jointly carried out, as the filter parameters are iteratively estimated and the speech utterance refined along the reverse diffusion trajectory. In a blind scenario where the room impulse response is unknown, BUDDy successfully performs speech dereverberation in various acoustic scenarios, significantly outperforming other blind unsupervised baselines. Unlike supervised methods, which often struggle to generalize, BUDDy seamlessly adapts to different acoustic conditions. This paper extends our previous work by offering new experimental results and insights into the algorithm's performance and versatility. We first investigate the robustness of informed dereverberation methods to RIR estimation errors, to motivate the joint acoustic estimation and dereverberation paradigm. Then, we demonstrate the adaptability of our method to high-resolution singing voice dereverberation, study its performance in RIR estimation, and conduct subjective evaluation experiments to validate the perceptual quality of the results, among other contributions. Audio samples and code can be found online.
EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation
Jun 11, 2024



We release the EARS (Expressive Anechoic Recordings of Speech) dataset, a high-quality speech dataset comprising 107 speakers from diverse backgrounds, totaling in 100 hours of clean, anechoic speech data. The dataset covers a large range of different speaking styles, including emotional speech, different reading styles, non-verbal sounds, and conversational freeform speech. We benchmark various methods for speech enhancement and dereverberation on the dataset and evaluate their performance through a set of instrumental metrics. In addition, we conduct a listening test with 20 participants for the speech enhancement task, where a generative method is preferred. We introduce a blind test set that allows for automatic online evaluation of uploaded data. Dataset download links and automatic evaluation server can be found online.
The PESQetarian: On the Relevance of Goodhart's Law for Speech Enhancement
Jun 05, 2024



To obtain improved speech enhancement models, researchers often focus on increasing performance according to specific instrumental metrics. However, when the same metric is used in a loss function to optimize models, it may be detrimental to aspects that the given metric does not see. The goal of this paper is to illustrate the risk of overfitting a speech enhancement model to the metric used for evaluation. For this, we introduce enhancement models that exploit the widely used PESQ measure. Our "PESQetarian" model achieves 3.82 PESQ on VB-DMD while scoring very poorly in a listening experiment. While the obtained PESQ value of 3.82 would imply "state-of-the-art" PESQ-performance on the VB-DMD benchmark, our examples show that when optimizing w.r.t. a metric, an isolated evaluation on the same metric may be misleading. Instead, other metrics should be included in the evaluation and the resulting performance predictions should be confirmed by listening.
BUDDy: Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
May 07, 2024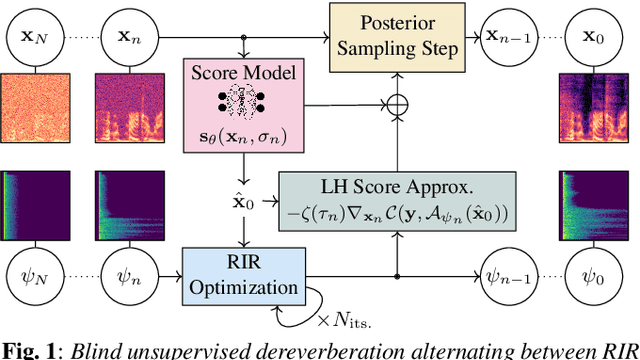
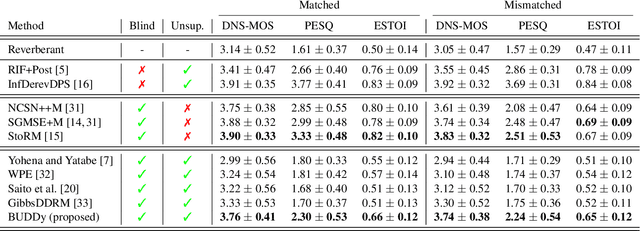
In this paper, we present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods. Audio samples and code are available online.
Diffusion Models for Audio Restoration
Feb 15, 2024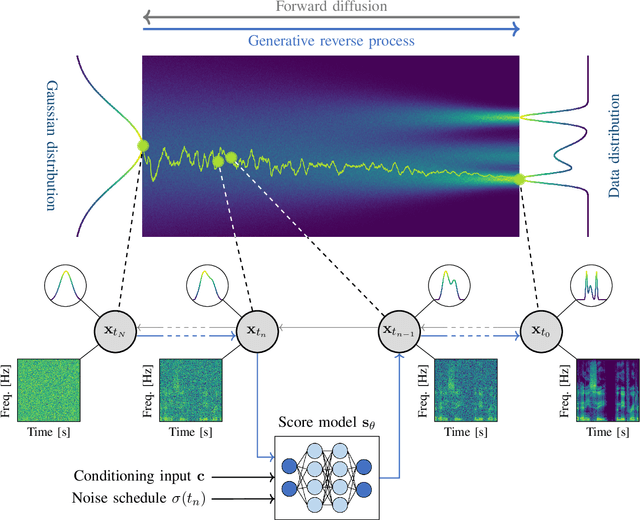
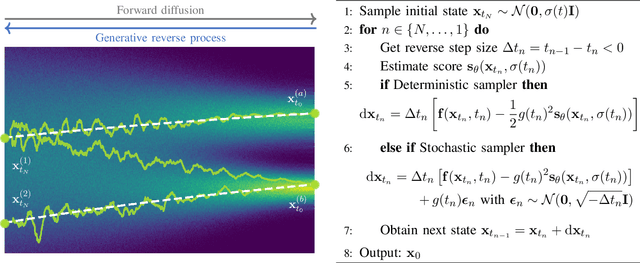
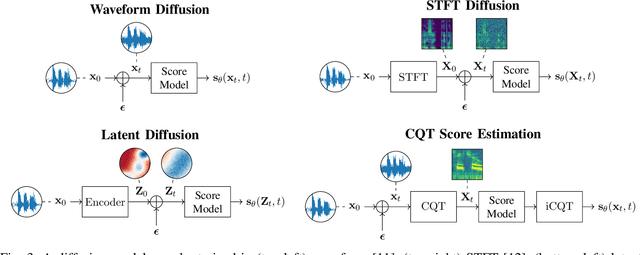
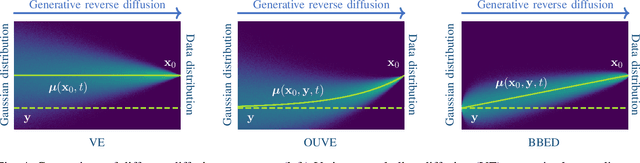
With the development of audio playback devices and fast data transmission, the demand for high sound quality is rising, for both entertainment and communications. In this quest for better sound quality, challenges emerge from distortions and interferences originating at the recording side or caused by an imperfect transmission pipeline. To address this problem, audio restoration methods aim to recover clean sound signals from the corrupted input data. We present here audio restoration algorithms based on diffusion models, with a focus on speech enhancement and music restoration tasks. Traditional approaches, often grounded in handcrafted rules and statistical heuristics, have shaped our understanding of audio signals. In the past decades, there has been a notable shift towards data-driven methods that exploit the modeling capabilities of deep neural networks (DNNs). Deep generative models, and among them diffusion models, have emerged as powerful techniques for learning complex data distributions. However, relying solely on DNN-based learning approaches carries the risk of reducing interpretability, particularly when employing end-to-end models. Nonetheless, data-driven approaches allow more flexibility in comparison to statistical model-based frameworks whose performance depends on distributional and statistical assumptions that can be difficult to guarantee. Here, we aim to show that diffusion models can combine the best of both worlds and offer the opportunity to design audio restoration algorithms with a good degree of interpretability and a remarkable performance in terms of sound quality.
Live Iterative Ptychography with projection-based algorithms
Sep 19, 2023In this work, we demonstrate that the ptychographic phase problem can be solved in a live fashion during scanning, while data is still being collected. We propose a generally applicable modification of the widespread projection-based algorithms such as Error Reduction (ER) and Difference Map (DM). This novel variant of ptychographic phase retrieval enables immediate visual feedback during experiments, reconstruction of arbitrary-sized objects with a fixed amount of computational resources, and adaptive scanning. By building upon the Real-Time Iterative Spectrogram Inversion (RTISI) family of algorithms from the audio processing literature, we show that live variants of projection-based methods such as DM can be derived naturally and may even achieve higher-quality reconstructions than their classic non-live counterparts with comparable effective computational load.