 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Music Mixing using a Generative Model of Effect Embeddings
Nov 11, 2025Music mixing involves combining individual tracks into a cohesive mixture, a task characterized by subjectivity where multiple valid solutions exist for the same input. Existing automatic mixing systems treat this task as a deterministic regression problem, thus ignoring this multiplicity of solutions. Here we introduce MEGAMI (Multitrack Embedding Generative Auto MIxing), a generative framework that models the conditional distribution of professional mixes given unprocessed tracks. MEGAMI uses a track-agnostic effects processor conditioned on per-track generated embeddings, handles arbitrary unlabeled tracks through a permutation-equivariant architecture, and enables training on both dry and wet recordings via domain adaptation. Our objective evaluation using distributional metrics shows consistent improvements over existing methods, while listening tests indicate performances approaching human-level quality across diverse musical genres.
Unsupervised Estimation of Nonlinear Audio Effects: Comparing Diffusion-Based and Adversarial approaches
Apr 07, 2025Accurately estimating nonlinear audio effects without access to paired input-output signals remains a challenging problem.This work studies unsupervised probabilistic approaches for solving this task. We introduce a method, novel for this application, based on diffusion generative models for blind system identification, enabling the estimation of unknown nonlinear effects using black- and gray-box models. This study compares this method with a previously proposed adversarial approach, analyzing the performance of both methods under different parameterizations of the effect operator and varying lengths of available effected recordings.Through experiments on guitar distortion effects, we show that the diffusion-based approach provides more stable results and is less sensitive to data availability, while the adversarial approach is superior at estimating more pronounced distortion effects. Our findings contribute to the robust unsupervised blind estimation of audio effects, demonstrating the potential of diffusion models for system identification in music technology.
Estimation and Restoration of Unknown Nonlinear Distortion using Diffusion
Jan 10, 2025The restoration of nonlinearly distorted audio signals, alongside the identification of the applied memoryless nonlinear operation, is studied. The paper focuses on the difficult but practically important case in which both the nonlinearity and the original input signal are unknown. The proposed method uses a generative diffusion model trained unconditionally on guitar or speech signals to jointly model and invert the nonlinear system at inference time. Both the memoryless nonlinear function model and the restored audio signal are obtained as output. Successful example case studies are presented including inversion of hard and soft clipping, digital quantization, half-wave rectification, and wavefolding nonlinearities. Our results suggest that, out of the nonlinear functions tested here, the cubic Catmull-Rom spline is best suited to approximating these nonlinearities. In the case of guitar recordings, comparisons with informed and supervised methods show that the proposed blind method is at least as good as they are in terms of objective metrics. Experiments on distorted speech show that the proposed blind method outperforms general-purpose speech enhancement techniques and restores the original voice quality. The proposed method can be applied to audio effects modeling, restoration of music and speech recordings, and characterization of analog recording media.
HRTF Estimation using a Score-based Prior
Oct 02, 2024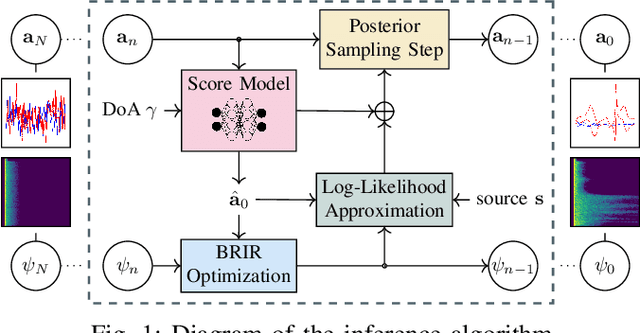
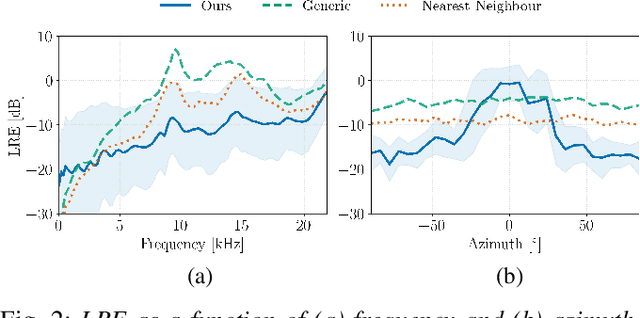
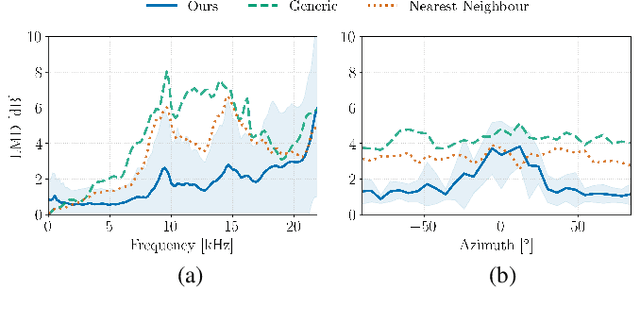

We present a head-related transfer function (HRTF) estimation method which relies on a data-driven prior given by a score-based diffusion model. The HRTF is estimated in reverberant environments using natural excitation signals, e.g. human speech. The impulse response of the room is estimated along with the HRTF by optimizing a parametric model of reverberation based on the statistical behaviour of room acoustics. The posterior distribution of HRTF given the reverberant measurement and excitation signal is modelled using the score-based HRTF prior and a log-likelihood approximation. We show that the resulting method outperforms several baselines, including an oracle recommender system that assigns the optimal HRTF in our training set based on the smallest distance to the true HRTF at the given direction of arrival. In particular, we show that the diffusion prior can account for the large variability of high-frequency content in HRTFs.
Unsupervised Blind Joint Dereverberation and Room Acoustics Estimation with Diffusion Models
Aug 14, 2024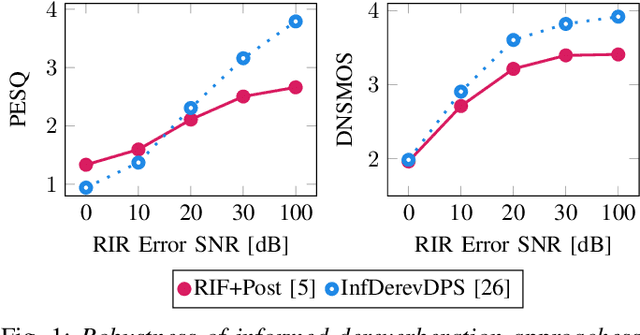
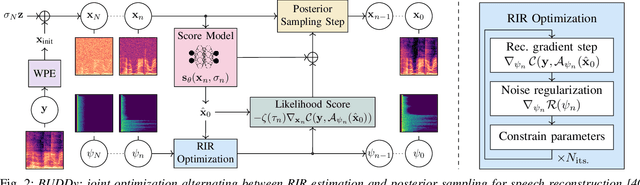
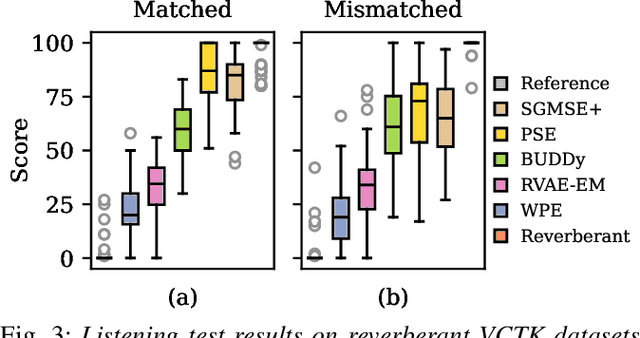
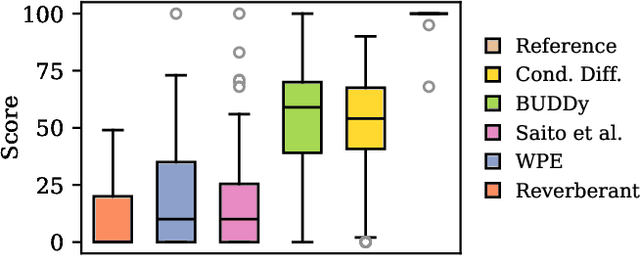
This paper presents an unsupervised method for single-channel blind dereverberation and room impulse response (RIR) estimation, called BUDDy. The algorithm is rooted in Bayesian posterior sampling: it combines a likelihood model enforcing fidelity to the reverberant measurement, and an anechoic speech prior implemented by an unconditional diffusion model. We design a parametric filter representing the RIR, with exponential decay for each frequency subband. Room acoustics estimation and speech dereverberation are jointly carried out, as the filter parameters are iteratively estimated and the speech utterance refined along the reverse diffusion trajectory. In a blind scenario where the room impulse response is unknown, BUDDy successfully performs speech dereverberation in various acoustic scenarios, significantly outperforming other blind unsupervised baselines. Unlike supervised methods, which often struggle to generalize, BUDDy seamlessly adapts to different acoustic conditions. This paper extends our previous work by offering new experimental results and insights into the algorithm's performance and versatility. We first investigate the robustness of informed dereverberation methods to RIR estimation errors, to motivate the joint acoustic estimation and dereverberation paradigm. Then, we demonstrate the adaptability of our method to high-resolution singing voice dereverberation, study its performance in RIR estimation, and conduct subjective evaluation experiments to validate the perceptual quality of the results, among other contributions. Audio samples and code can be found online.
Gaussian Flow Bridges for Audio Domain Transfer with Unpaired Data
May 29, 2024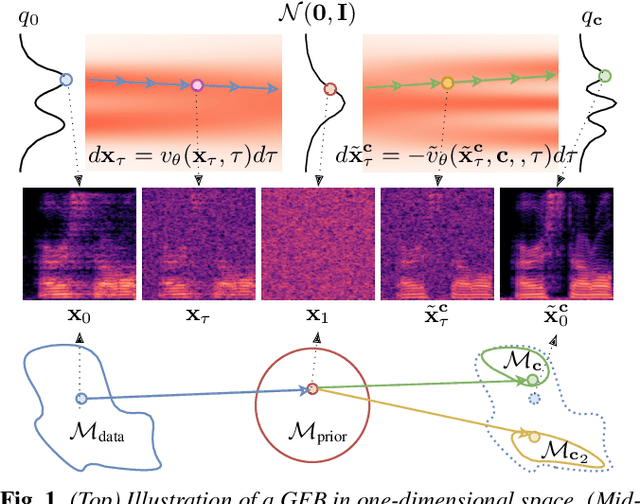
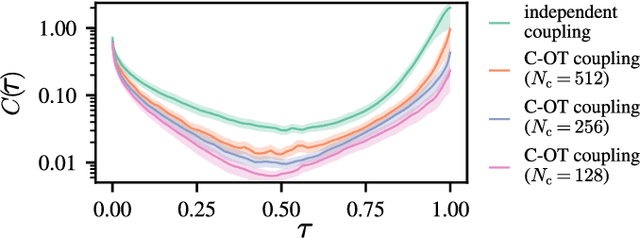
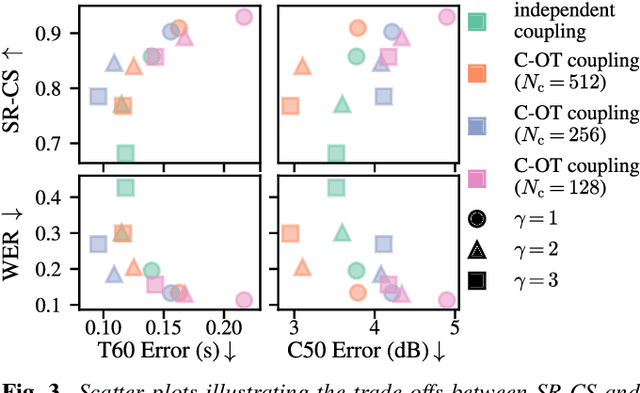
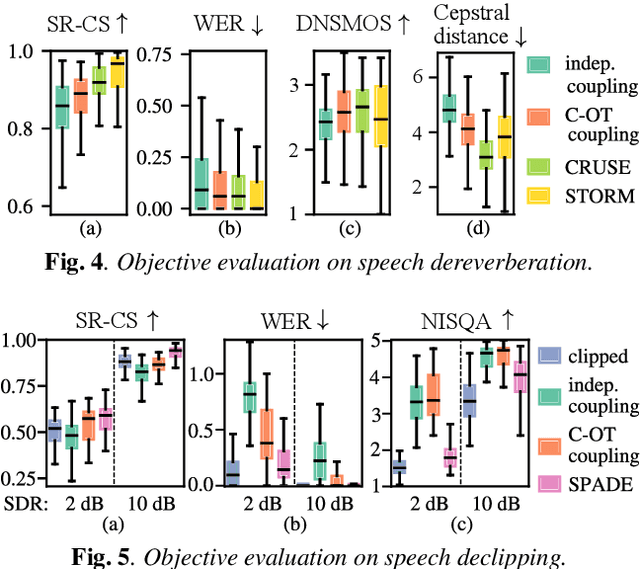
Audio domain transfer is the process of modifying audio signals to match characteristics of a different domain, while retaining the original content. This paper investigates the potential of Gaussian Flow Bridges, an emerging approach in generative modeling, for this problem. The presented framework addresses the transport problem across different distributions of audio signals through the implementation of a series of two deterministic probability flows. The proposed framework facilitates manipulation of the target distribution properties through a continuous control variable, which defines a certain aspect of the target domain. Notably, this approach does not rely on paired examples for training. To address identified challenges on maintaining the speech content consistent, we recommend a training strategy that incorporates chunk-based minibatch Optimal Transport couplings of data samples and noise. Comparing our unsupervised method with established baselines, we find competitive performance in tasks of reverberation and distortion manipulation. Despite encoutering limitations, the intriguing results obtained in this study underscore potential for further exploration.
BUDDy: Single-Channel Blind Unsupervised Dereverberation with Diffusion Models
May 07, 2024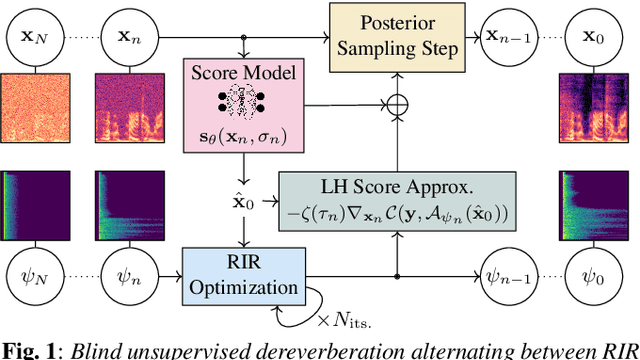
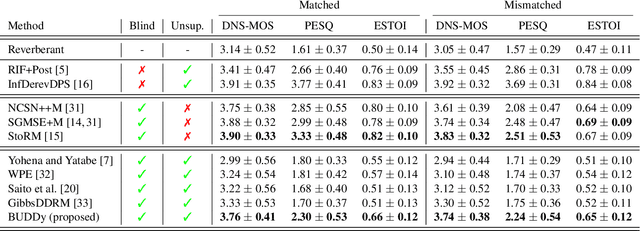
In this paper, we present an unsupervised single-channel method for joint blind dereverberation and room impulse response estimation, based on posterior sampling with diffusion models. We parameterize the reverberation operator using a filter with exponential decay for each frequency subband, and iteratively estimate the corresponding parameters as the speech utterance gets refined along the reverse diffusion trajectory. A measurement consistency criterion enforces the fidelity of the generated speech with the reverberant measurement, while an unconditional diffusion model implements a strong prior for clean speech generation. Without any knowledge of the room impulse response nor any coupled reverberant-anechoic data, we can successfully perform dereverberation in various acoustic scenarios. Our method significantly outperforms previous blind unsupervised baselines, and we demonstrate its increased robustness to unseen acoustic conditions in comparison to blind supervised methods. Audio samples and code are available online.
A Diffusion-Based Generative Equalizer for Music Restoration
Mar 27, 2024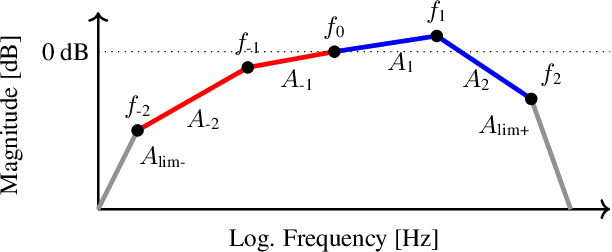
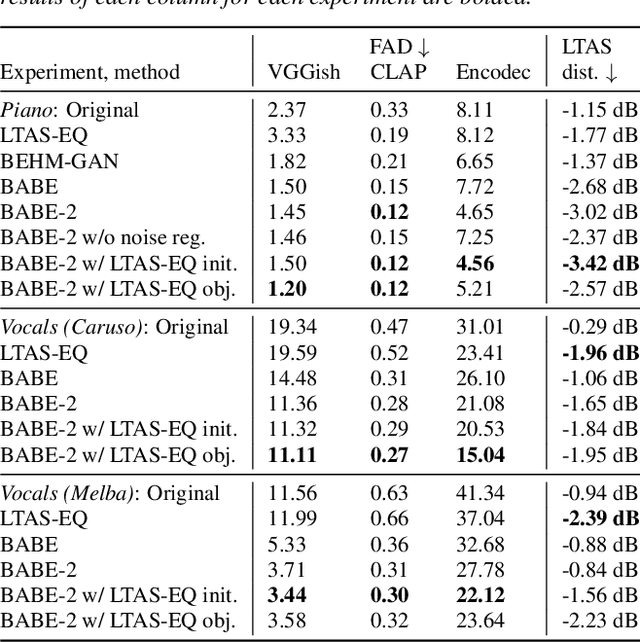

This paper presents a novel approach to audio restoration, focusing on the enhancement of low-quality music recordings, and in particular historical ones. Building upon a previous algorithm called BABE, or Blind Audio Bandwidth Extension, we introduce BABE-2, which presents a series of significant improvements. This research broadens the concept of bandwidth extension to \emph{generative equalization}, a novel task that, to the best of our knowledge, has not been explicitly addressed in previous studies. BABE-2 is built around an optimization algorithm utilizing priors from diffusion models, which are trained or fine-tuned using a curated set of high-quality music tracks. The algorithm simultaneously performs two critical tasks: estimation of the filter degradation magnitude response and hallucination of the restored audio. The proposed method is objectively evaluated on historical piano recordings, showing a marked enhancement over the prior version. The method yields similarly impressive results in rejuvenating the works of renowned vocalists Enrico Caruso and Nellie Melba. This research represents an advancement in the practical restoration of historical music.
Diffusion Models for Audio Restoration
Feb 15, 2024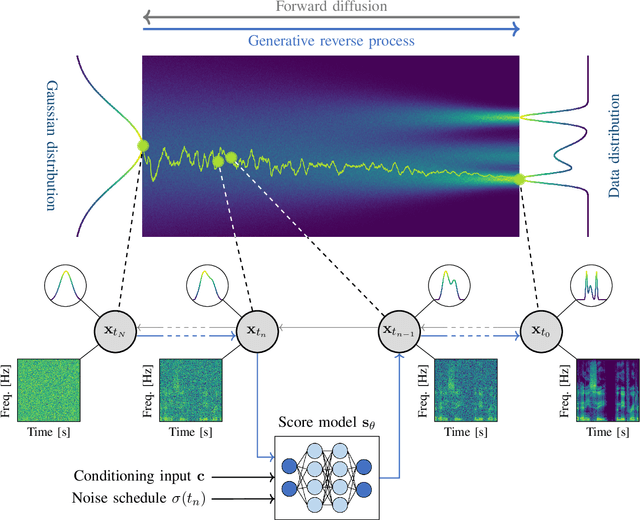
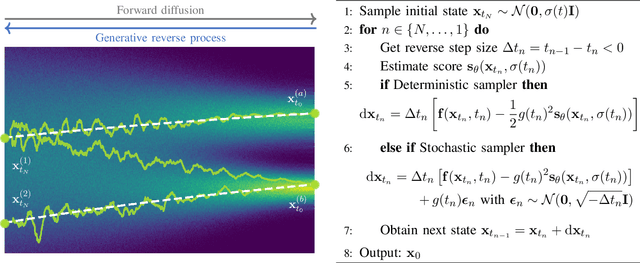
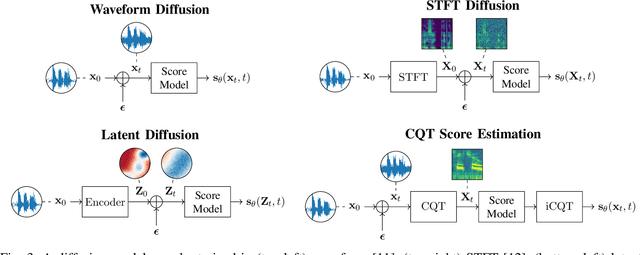
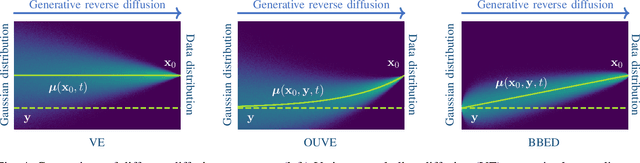
With the development of audio playback devices and fast data transmission, the demand for high sound quality is rising, for both entertainment and communications. In this quest for better sound quality, challenges emerge from distortions and interferences originating at the recording side or caused by an imperfect transmission pipeline. To address this problem, audio restoration methods aim to recover clean sound signals from the corrupted input data. We present here audio restoration algorithms based on diffusion models, with a focus on speech enhancement and music restoration tasks. Traditional approaches, often grounded in handcrafted rules and statistical heuristics, have shaped our understanding of audio signals. In the past decades, there has been a notable shift towards data-driven methods that exploit the modeling capabilities of deep neural networks (DNNs). Deep generative models, and among them diffusion models, have emerged as powerful techniques for learning complex data distributions. However, relying solely on DNN-based learning approaches carries the risk of reducing interpretability, particularly when employing end-to-end models. Nonetheless, data-driven approaches allow more flexibility in comparison to statistical model-based frameworks whose performance depends on distributional and statistical assumptions that can be difficult to guarantee. Here, we aim to show that diffusion models can combine the best of both worlds and offer the opportunity to design audio restoration algorithms with a good degree of interpretability and a remarkable performance in terms of sound quality.
Noise Morphing for Audio Time Stretching
Dec 22, 2023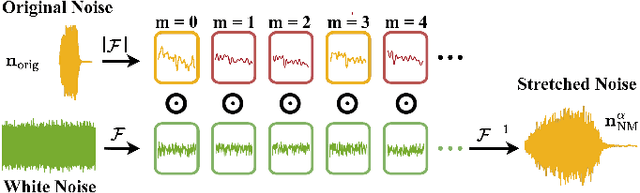
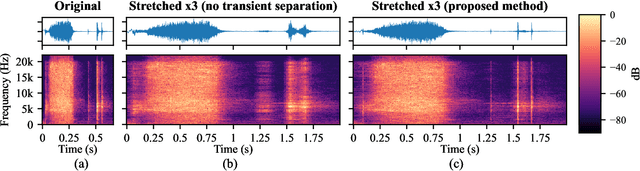
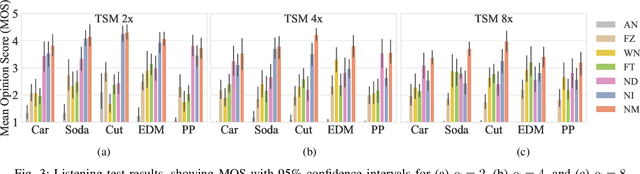

This letter introduces an innovative method to enhance the quality of audio time stretching by precisely decomposing a sound into sines, transients, and noise and by improving the processing of the latter component. While there are established methods for time-stretching sines and transients with high quality, the manipulation of noise or residual components has lacked robust solutions in prior research. The proposed method combines sound decomposition with previous techniques for audio spectral resynthesis. The time-stretched noise component is achieved by morphing its time-interpolated spectral magnitude with a white-noise excitation signal. This method stands out for its simplicity, efficiency, and audio quality. The results of a subjective experiment affirm the superiority of this approach over current state-of-the-art methods across all evaluated stretch factors. The proposed technique notably excels in extreme stretching scenarios, signifying a substantial elevation in performance. The proposed method holds promise for a wide range of applications in slow-motion media content, such as music or sports video production.