 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra-Low Latency Speech Enhancement - A Comprehensive Study
Sep 16, 2024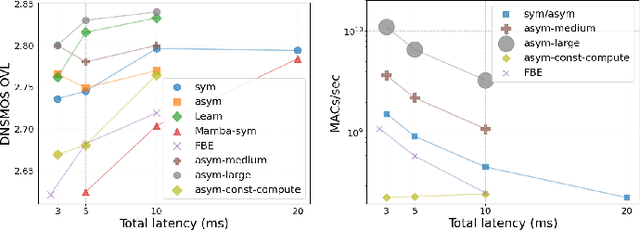


Speech enhancement models should meet very low latency requirements typically smaller than 5 ms for hearing assistive devices. While various low-latency techniques have been proposed, comparing these methods in a controlled setup using DNNs remains blank. Previous papers have variations in task, training data, scripts, and evaluation settings, which make fair comparison impossible. Moreover, all methods are tested on small, simulated datasets, making it difficult to fairly assess their performance in real-world conditions, which could impact the reliability of scientific findings. To address these issues, we comprehensively investigate various low-latency techniques using consistent training on large-scale data and evaluate with more relevant metrics on real-world data. Specifically, we explore the effectiveness of asymmetric windows, learnable windows, adaptive time domain filterbanks, and the future-frame prediction technique. Additionally, we examine whether increasing the model size can compensate for the reduced window size, as well as the novel Mamba architecture in low-latency environments.
Multi-label audio classification with a noisy zero-shot teacher
Jul 20, 2024



We propose a novel training scheme using self-label correction and data augmentation methods designed to deal with noisy labels and improve real-world accuracy on a polyphonic audio content detection task. The augmentation method reduces label noise by mixing multiple audio clips and joining their labels, while being compatible with multiple active labels. We additionally show that performance can be improved by a self-label correction method using the same pretrained model. Finally, we show that it is feasible to use a strong zero-shot model such as CLAP to generate labels for unlabeled data and improve the results using the proposed training and label enhancement methods. The resulting model performs similar to CLAP while being an efficient mobile device friendly architecture and can be quickly adapted to unlabeled sound classes.
Gaussian Flow Bridges for Audio Domain Transfer with Unpaired Data
May 29, 2024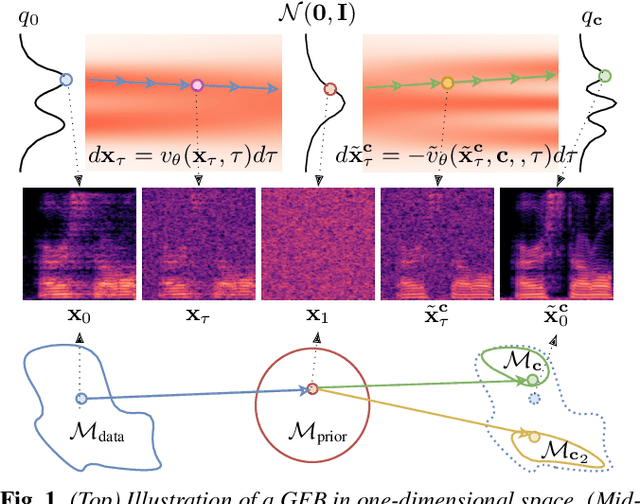
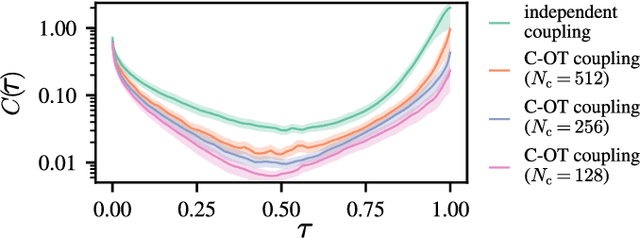
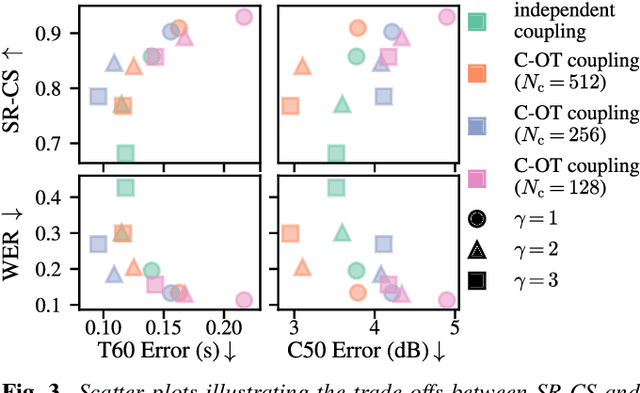
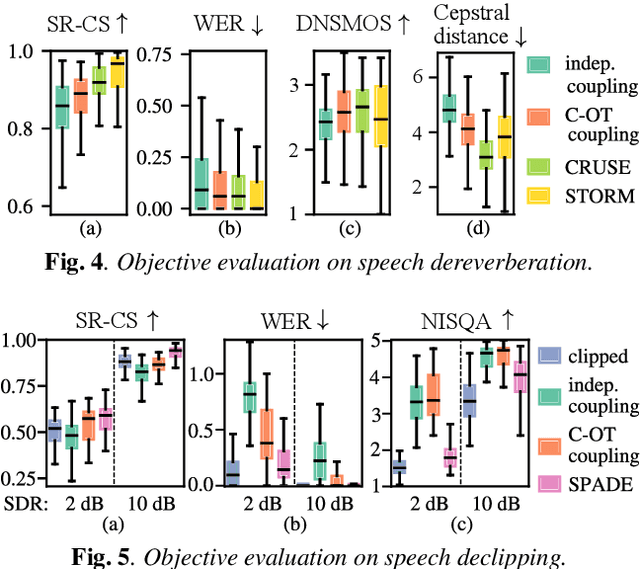
Audio domain transfer is the process of modifying audio signals to match characteristics of a different domain, while retaining the original content. This paper investigates the potential of Gaussian Flow Bridges, an emerging approach in generative modeling, for this problem. The presented framework addresses the transport problem across different distributions of audio signals through the implementation of a series of two deterministic probability flows. The proposed framework facilitates manipulation of the target distribution properties through a continuous control variable, which defines a certain aspect of the target domain. Notably, this approach does not rely on paired examples for training. To address identified challenges on maintaining the speech content consistent, we recommend a training strategy that incorporates chunk-based minibatch Optimal Transport couplings of data samples and noise. Comparing our unsupervised method with established baselines, we find competitive performance in tasks of reverberation and distortion manipulation. Despite encoutering limitations, the intriguing results obtained in this study underscore potential for further exploration.
ICASSP 2024 Speech Signal Improvement Challenge
Jan 25, 2024
The ICASSP 2024 Speech Signal Improvement Grand Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. This marks our second challenge, building upon the success from the previous ICASSP 2023 Grand Challenge. We enhance the competition by introducing a dataset synthesizer, enabling all participating teams to start at a higher baseline, an objective metric for our extended P.804 tests, transcripts for the 2023 test set, and we add Word Accuracy (WAcc) as a metric. We evaluate a total of 13 systems in the real-time track and 11 systems in the non-real-time track using both subjective P.804 and objective Word Accuracy metrics.
CMMD: Contrastive Multi-Modal Diffusion for Video-Audio Conditional Modeling
Dec 08, 2023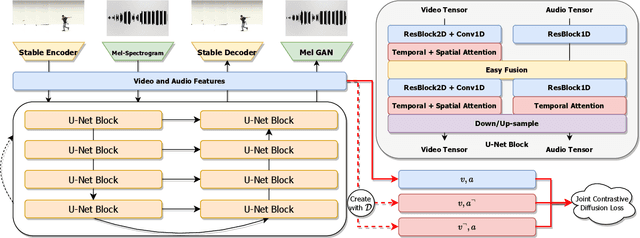
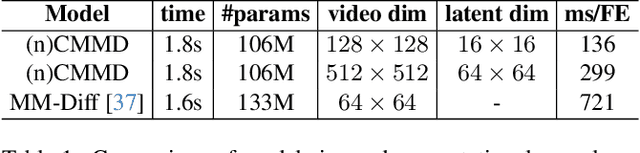
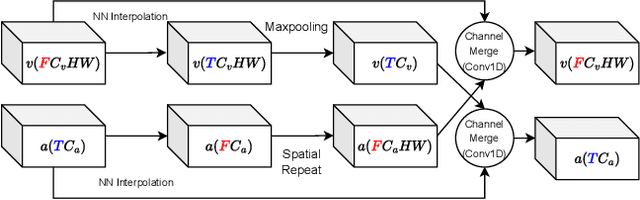
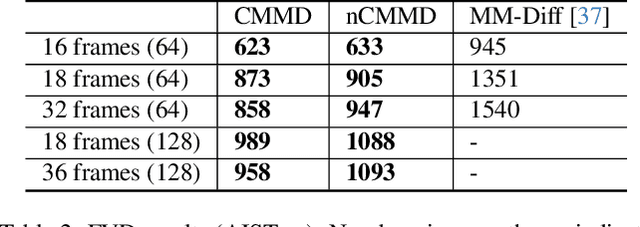
We introduce a multi-modal diffusion model tailored for the bi-directional conditional generation of video and audio. Recognizing the importance of accurate alignment between video and audio events in multi-modal generation tasks, we propose a joint contrastive training loss to enhance the synchronization between visual and auditory occurrences. Our research methodology involves conducting comprehensive experiments on multiple datasets to thoroughly evaluate the efficacy of our proposed model. The assessment of generation quality and alignment performance is carried out from various angles, encompassing both objective and subjective metrics. Our findings demonstrate that the proposed model outperforms the baseline, substantiating its effectiveness and efficiency. Notably, the incorporation of the contrastive loss results in improvements in audio-visual alignment, particularly in the high-correlation video-to-audio generation task. These results indicate the potential of our proposed model as a robust solution for improving the quality and alignment of multi-modal generation, thereby contributing to the advancement of video and audio conditional generation systems.
Adapting Frechet Audio Distance for Generative Music Evaluation
Nov 02, 2023The growing popularity of generative music models underlines the need for perceptually relevant, objective music quality metrics. The Frechet Audio Distance (FAD) is commonly used for this purpose even though its correlation with perceptual quality is understudied. We show that FAD performance may be hampered by sample size bias, poor choice of audio embeddings, or the use of biased or low-quality reference sets. We propose reducing sample size bias by extrapolating scores towards an infinite sample size. Through comparisons with MusicCaps labels and a listening test we identify audio embeddings and music reference sets that yield FAD scores well-correlated with acoustic and musical quality. Our results suggest that per-song FAD can be useful to identify outlier samples and predict perceptual quality for a range of music sets and generative models. Finally, we release a toolkit that allows adapting FAD for generative music evaluation.
ICASSP 2023 Acoustic Echo Cancellation Challenge
Sep 22, 2023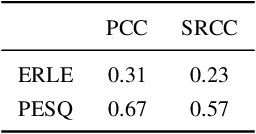

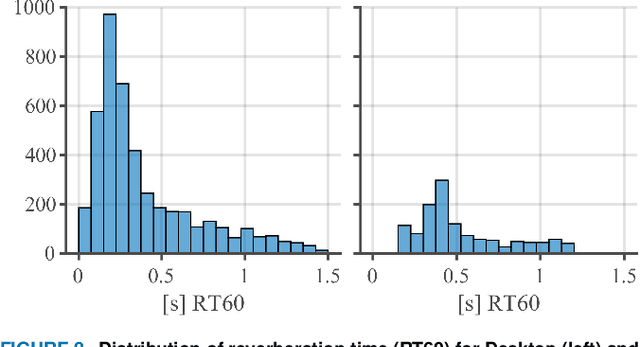
The ICASSP 2023 Acoustic Echo Cancellation Challenge is intended to stimulate research in acoustic echo cancellation (AEC), which is an important area of speech enhancement and is still a top issue in audio communication. This is the fourth AEC challenge and it is enhanced by adding a second track for personalized acoustic echo cancellation, reducing the algorithmic + buffering latency to 20ms, as well as including a full-band version of AECMOS. We open source two large datasets to train AEC models under both single talk and double talk scenarios. These datasets consist of recordings from more than 10,000 real audio devices and human speakers in real environments, as well as a synthetic dataset. We open source an online subjective test framework and provide an objective metric for researchers to quickly test their results. The winners of this challenge were selected based on the average mean opinion score (MOS) achieved across all scenarios and the word accuracy (WAcc) rate.
ICASSP 2023 Speech Signal Improvement Challenge
Apr 02, 2023The ICASSP 2023 Speech Signal Improvement Challenge is intended to stimulate research in the area of improving the speech signal quality in communication systems. The speech signal quality can be measured with SIG in ITU-T P.835 and is still a top issue in audio communication and conferencing systems. For example, in the ICASSP 2022 Deep Noise Suppression challenge, the improvement in the background and overall quality is impressive, but the improvement in the speech signal is statistically zero. To improve the speech signal the following speech impairment areas must be addressed: coloration, discontinuity, loudness, and reverberation. A dataset and test set were provided for the challenge, and the winners were determined using an extended crowdsourced implementation of ITU-T P.80's listening phase . The results show significant improvement was made across all measured dimensions of speech quality.
ICASSP 2023 Deep Speech Enhancement Challenge
Mar 21, 2023
Deep Speech Enhancement Challenge is the 5th edition of deep noise suppression (DNS) challenges organized at ICASSP 2023 Signal Processing Grand Challenges. DNS challenges were organized during 2019-2023 to stimulate research in deep speech enhancement (DSE). Previous DNS challenges were organized at INTERSPEECH 2020, ICASSP 2021, INTERSPEECH 2021, and ICASSP 2022. From prior editions, we learnt that improving signal quality (SIG) is challenging particularly in presence of simultaneously active interfering talkers and noise. This challenge aims to develop models for joint denosing, dereverberation and suppression of interfering talkers. When primary talker wears a headphone, certain acoustic properties of their speech such as direct-to-reverberation (DRR), signal to noise ratio (SNR) etc. make it possible to suppress neighboring talkers even without enrollment data for primary talker. This motivated us to create two tracks for this challenge: (i) Track-1 Headset; (ii) Track-2 Speakerphone. Both tracks has fullband (48kHz) training data and testset, and each testclips has a corresponding enrollment data (10-30s duration) for primary talker. Each track invited submissions of personalized and non-personalized models all of which are evaluated through same subjective evaluation. Most models submitted to challenge were personalized models, same team is winner in both tracks where the best models has improvement of 0.145 and 0.141 in challenge's Score as compared to noisy blind testset.
Towards Real-Time Single-Channel Speech Separation in Noisy and Reverberant Environments
Mar 14, 2023



Real-time single-channel speech separation aims to unmix an audio stream captured from a single microphone that contains multiple people talking at once, environmental noise, and reverberation into multiple de-reverberated and noise-free speech tracks, each track containing only one talker. While large state-of-the-art DNNs can achieve excellent separation from anechoic mixtures of speech, the main challenge is to create compact and causal models that can separate reverberant mixtures at inference time. In this paper, we explore low-complexity, resource-efficient, causal DNN architectures for real-time separation of two or more simultaneous speakers. A cascade of three neural network modules are trained to sequentially perform noise-suppression, separation, and de-reverberation. For comparison, a larger end-to-end model is trained to output two anechoic speech signals directly from noisy reverberant speech mixtures. We propose an efficient single-decoder architecture with subtractive separation for real-time recursive speech separation for two or more speakers. Evaluation on real monophonic recordings of speech mixtures, according to speech separation measures like SI-SDR, perceptual measures like DNS-MOS, and a novel proposed channel separation metric, show that these compact causal models can separate speech mixtures with low latency, and perform on par with large offline state-of-the-art models like SepFormer.