 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICASSP 2023 Deep Speech Enhancement Challenge
Mar 21, 2023
Deep Speech Enhancement Challenge is the 5th edition of deep noise suppression (DNS) challenges organized at ICASSP 2023 Signal Processing Grand Challenges. DNS challenges were organized during 2019-2023 to stimulate research in deep speech enhancement (DSE). Previous DNS challenges were organized at INTERSPEECH 2020, ICASSP 2021, INTERSPEECH 2021, and ICASSP 2022. From prior editions, we learnt that improving signal quality (SIG) is challenging particularly in presence of simultaneously active interfering talkers and noise. This challenge aims to develop models for joint denosing, dereverberation and suppression of interfering talkers. When primary talker wears a headphone, certain acoustic properties of their speech such as direct-to-reverberation (DRR), signal to noise ratio (SNR) etc. make it possible to suppress neighboring talkers even without enrollment data for primary talker. This motivated us to create two tracks for this challenge: (i) Track-1 Headset; (ii) Track-2 Speakerphone. Both tracks has fullband (48kHz) training data and testset, and each testclips has a corresponding enrollment data (10-30s duration) for primary talker. Each track invited submissions of personalized and non-personalized models all of which are evaluated through same subjective evaluation. Most models submitted to challenge were personalized models, same team is winner in both tracks where the best models has improvement of 0.145 and 0.141 in challenge's Score as compared to noisy blind testset.
ICASSP 2022 Deep Noise Suppression Challenge
Feb 27, 2022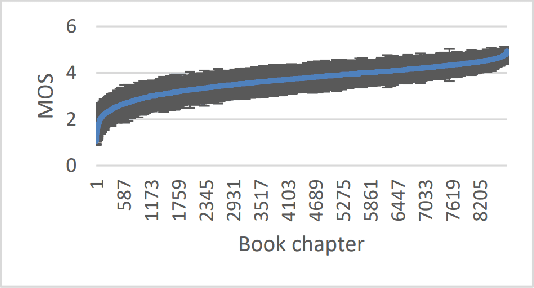
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. This is the 4th DNS challenge, with the previous editions held at INTERSPEECH 2020, ICASSP 2021, and INTERSPEECH 2021. We open-source datasets and test sets for researchers to train their deep noise suppression models, as well as a subjective evaluation framework based on ITU-T P.835 to rate and rank-order the challenge entries. We provide access to DNSMOS P.835 and word accuracy (WAcc) APIs to challenge participants to help with iterative model improvements. In this challenge, we introduced the following changes: (i) Included mobile device scenarios in the blind test set; (ii) Included a personalized noise suppression track with baseline; (iii) Added WAcc as an objective metric; (iv) Included DNSMOS P.835; (v) Made the training datasets and test sets fullband (48 kHz). We use an average of WAcc and subjective scores P.835 SIG, BAK, and OVRL to get the final score for ranking the DNS models. We believe that as a research community, we still have a long way to go in achieving excellent speech quality in challenging noisy real-world scenarios.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020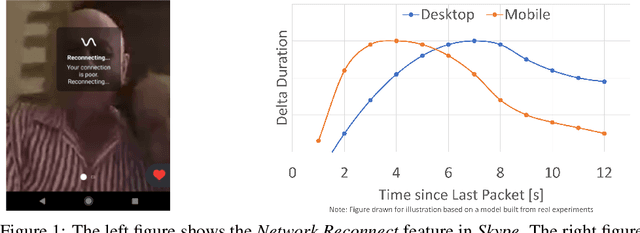


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments
Lumos: A Library for Diagnosing Metric Regressions in Web-Scale Applications
Jun 23, 2020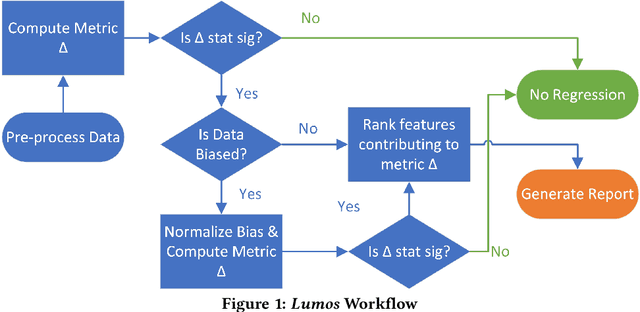
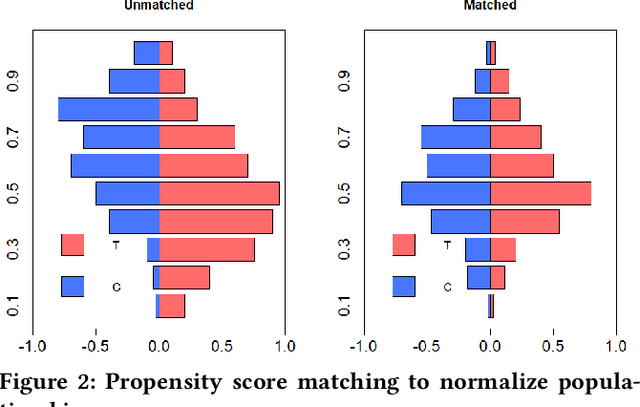
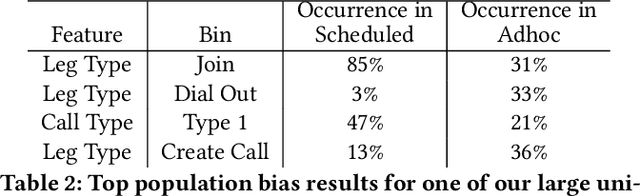
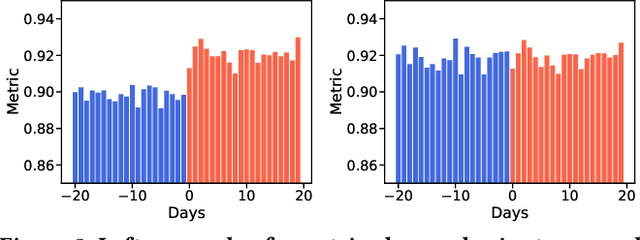
Web-scale applications can ship code on a daily to weekly cadence. These applications rely on online metrics to monitor the health of new releases. Regressions in metric values need to be detected and diagnosed as early as possible to reduce the disruption to users and product owners. Regressions in metrics can surface due to a variety of reasons: genuine product regressions, changes in user population, and bias due to telemetry loss (or processing) are among the common causes. Diagnosing the cause of these metric regressions is costly for engineering teams as they need to invest time in finding the root cause of the issue as soon as possible. We present Lumos, a Python library built using the principles of AB testing to systematically diagnose metric regressions to automate such analysis. Lumos has been deployed across the component teams in Microsoft's Real-Time Communication applications Skype and Microsoft Teams. It has enabled engineering teams to detect 100s of real changes in metrics and reject 1000s of false alarms detected by anomaly detectors. The application of Lumos has resulted in freeing up as much as 95% of the time allocated to metric-based investigations. In this work, we open source Lumos and present our results from applying it to two different components within the RTC group over millions of sessions. This general library can be coupled with any production system to manage the volume of alerting efficiently.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results
May 29, 2020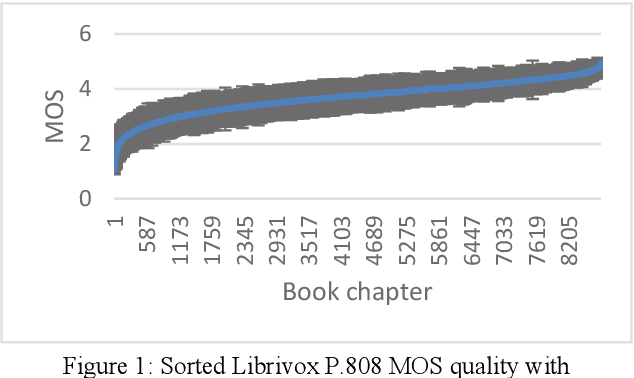

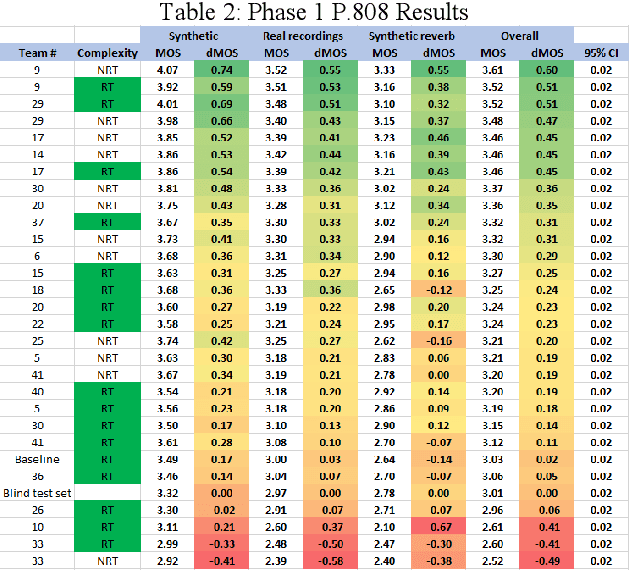
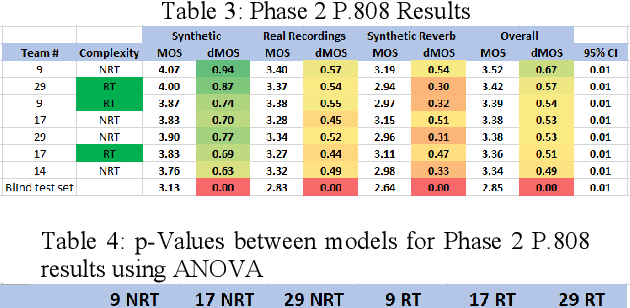
The INTERSPEECH 2020 Deep Noise Suppression (DNS) Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. While the performance is good on the synthetic test set, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-sourced a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open-sourced an online subjective test framework based on ITU-T P.808 for researchers to reliably test their developments. We evaluated the results using P.808 on a blind test set. The results and the key learnings from the challenge are discussed. The datasets and scripts can be found here for quick access https://github.com/microsoft/DNS-Challenge.
The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Speech Quality and Testing Framework
Jan 23, 2020

The INTERSPEECH 2020 Deep Noise Suppression Challenge is intended to promote collaborative research in real-time single-channel Speech Enhancement aimed to maximize the subjective (perceptual) quality of the enhanced speech. A typical approach to evaluate the noise suppression methods is to use objective metrics on the test set obtained by splitting the original dataset. Many publications report reasonable performance on the synthetic test set drawn from the same distribution as that of the training set. However, often the model performance degrades significantly on real recordings. Also, most of the conventional objective metrics do not correlate well with subjective tests and lab subjective tests are not scalable for a large test set. In this challenge, we open-source a large clean speech and noise corpus for training the noise suppression models and a representative test set to real-world scenarios consisting of both synthetic and real recordings. We also open source an online subjective test framework based on ITU-T P.808 for researchers to quickly test their developments. The winners of this challenge will be selected based on subjective evaluation on a representative test set using P.808 framework.