 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
Jul 17, 2024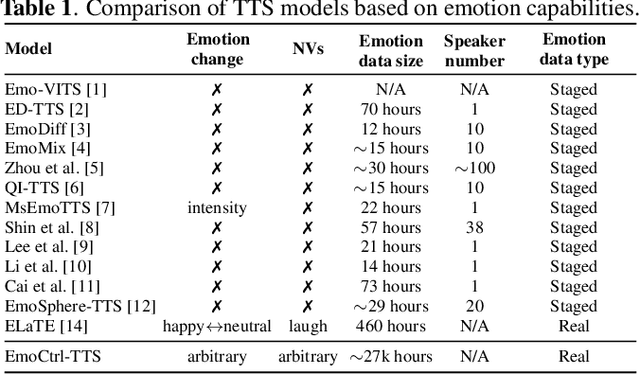
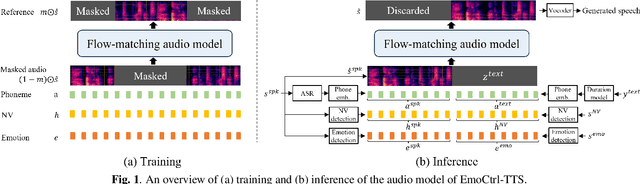
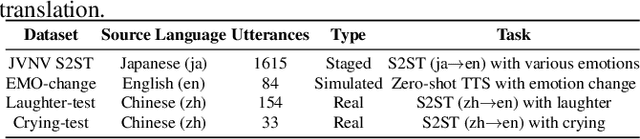
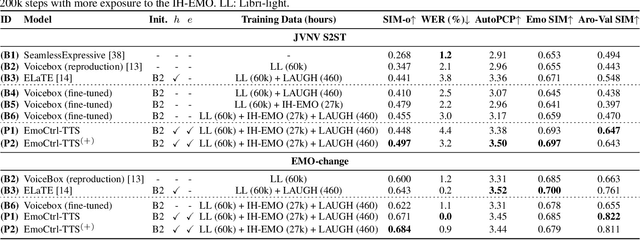
People change their tones of voice, often accompanied by nonverbal vocalizations (NVs) such as laughter and cries, to convey rich emotions. However, most text-to-speech (TTS) systems lack the capability to generate speech with rich emotions, including NVs. This paper introduces EmoCtrl-TTS, an emotion-controllable zero-shot TTS that can generate highly emotional speech with NVs for any speaker. EmoCtrl-TTS leverages arousal and valence values, as well as laughter embeddings, to condition the flow-matching-based zero-shot TTS. To achieve high-quality emotional speech generation, EmoCtrl-TTS is trained using more than 27,000 hours of expressive data curated based on pseudo-labeling. Comprehensive evaluations demonstrate that EmoCtrl-TTS excels in mimicking the emotions of audio prompts in speech-to-speech translation scenarios. We also show that EmoCtrl-TTS can capture emotion changes, express strong emotions, and generate various NVs in zero-shot TTS. See https://aka.ms/emoctrl-tts for demo samples.
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
Jun 26, 2024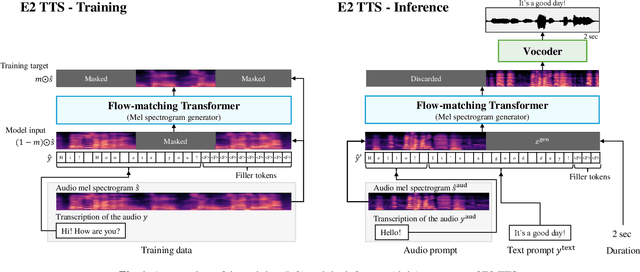
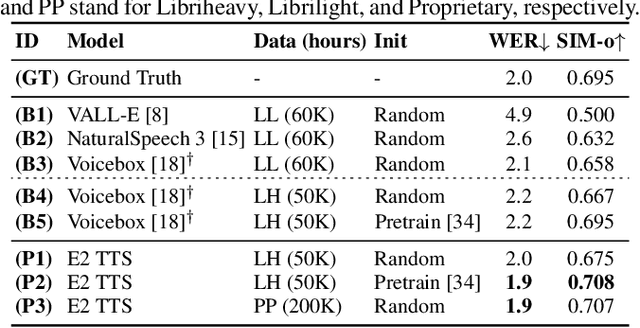
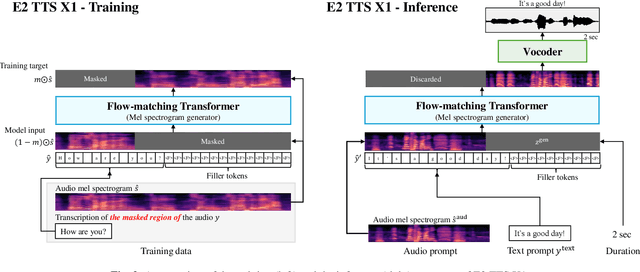
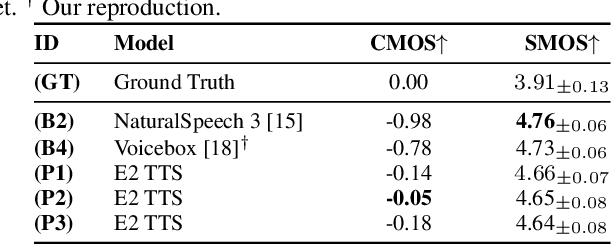
This paper introduces Embarrassingly Easy Text-to-Speech (E2 TTS), a fully non-autoregressive zero-shot text-to-speech system that offers human-level naturalness and state-of-the-art speaker similarity and intelligibility. In the E2 TTS framework, the text input is converted into a character sequence with filler tokens. The flow-matching-based mel spectrogram generator is then trained based on the audio infilling task. Unlike many previous works, it does not require additional components (e.g., duration model, grapheme-to-phoneme) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS capabilities that are comparable to or surpass previous works, including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in the input representation. We propose several variants of E2 TTS to improve usability during inference. See https://aka.ms/e2tts/ for demo samples.
An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS
Jun 09, 2024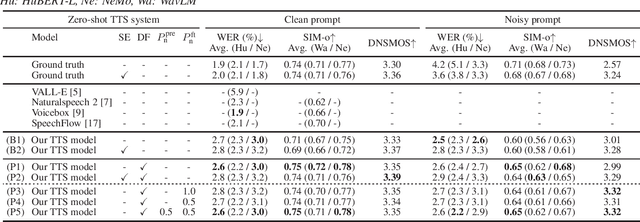
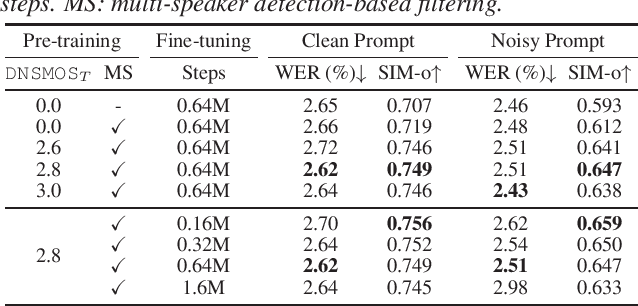
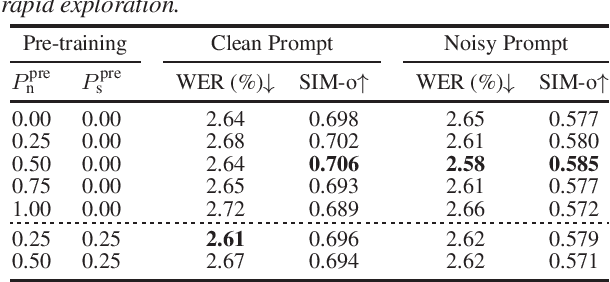
Recently, zero-shot text-to-speech (TTS) systems, capable of synthesizing any speaker's voice from a short audio prompt, have made rapid advancements. However, the quality of the generated speech significantly deteriorates when the audio prompt contains noise, and limited research has been conducted to address this issue. In this paper, we explored various strategies to enhance the quality of audio generated from noisy audio prompts within the context of flow-matching-based zero-shot TTS. Our investigation includes comprehensive training strategies: unsupervised pre-training with masked speech denoising, multi-speaker detection and DNSMOS-based data filtering on the pre-training data, and fine-tuning with random noise mixing. The results of our experiments demonstrate significant improvements in intelligibility, speaker similarity, and overall audio quality compared to the approach of applying speech enhancement to the audio prompt.
Total-Duration-Aware Duration Modeling for Text-to-Speech Systems
Jun 06, 2024



Accurate control of the total duration of generated speech by adjusting the speech rate is crucial for various text-to-speech (TTS) applications. However, the impact of adjusting the speech rate on speech quality, such as intelligibility and speaker characteristics, has been underexplored. In this work, we propose a novel total-duration-aware (TDA) duration model for TTS, where phoneme durations are predicted not only from the text input but also from an additional input of the total target duration. We also propose a MaskGIT-based duration model that enhances the diversity and quality of the predicted phoneme durations. Our results demonstrate that the proposed TDA duration models achieve better intelligibility and speaker similarity for various speech rate configurations compared to the baseline models. We also show that the proposed MaskGIT-based model can generate phoneme durations with higher quality and diversity compared to its regression or flow-matching counterparts.
Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like
Feb 12, 2024Laughter is one of the most expressive and natural aspects of human speech, conveying emotions, social cues, and humor. However, most text-to-speech (TTS) systems lack the ability to produce realistic and appropriate laughter sounds, limiting their applications and user experience. While there have been prior works to generate natural laughter, they fell short in terms of controlling the timing and variety of the laughter to be generated. In this work, we propose ELaTE, a zero-shot TTS that can generate natural laughing speech of any speaker based on a short audio prompt with precise control of laughter timing and expression. Specifically, ELaTE works on the audio prompt to mimic the voice characteristic, the text prompt to indicate the contents of the generated speech, and the input to control the laughter expression, which can be either the start and end times of laughter, or the additional audio prompt that contains laughter to be mimicked. We develop our model based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model. Through the evaluations, we show that ELaTE can generate laughing speech with significantly higher quality and controllability compared to conventional models. See https://aka.ms/elate/ for demo samples.
SpeechX: Neural Codec Language Model as a Versatile Speech Transformer
Aug 14, 2023Recent advancements in generative speech models based on audio-text prompts have enabled remarkable innovations like high-quality zero-shot text-to-speech. However, existing models still face limitations in handling diverse audio-text speech generation tasks involving transforming input speech and processing audio captured in adverse acoustic conditions. This paper introduces SpeechX, a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks, dealing with both clean and noisy signals. SpeechX combines neural codec language modeling with multi-task learning using task-dependent prompting, enabling unified and extensible modeling and providing a consistent way for leveraging textual input in speech enhancement and transformation tasks. Experimental results show SpeechX's efficacy in various tasks, including zero-shot TTS, noise suppression, target speaker extraction, speech removal, and speech editing with or without background noise, achieving comparable or superior performance to specialized models across tasks. See https://aka.ms/speechx for demo samples.
Fast Real-time Personalized Speech Enhancement: End-to-End Enhancement Network (E3Net) and Knowledge Distillation
Apr 02, 2022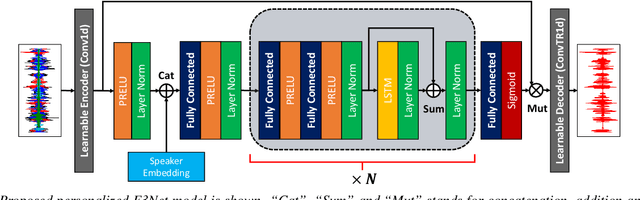
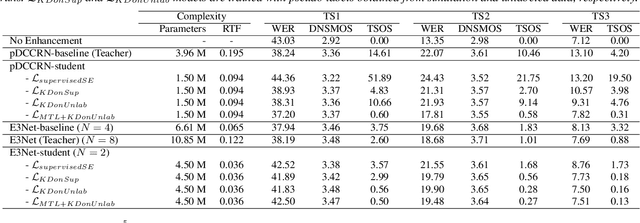
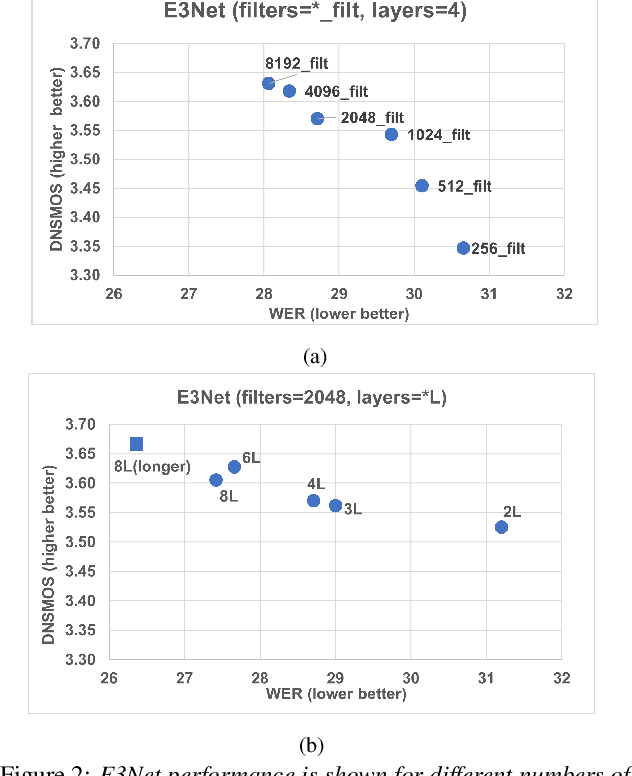
This paper investigates how to improve the runtime speed of personalized speech enhancement (PSE) networks while maintaining the model quality. Our approach includes two aspects: architecture and knowledge distillation (KD). We propose an end-to-end enhancement (E3Net) model architecture, which is $3\times$ faster than a baseline STFT-based model. Besides, we use KD techniques to develop compressed student models without significantly degrading quality. In addition, we investigate using noisy data without reference clean signals for training the student models, where we combine KD with multi-task learning (MTL) using automatic speech recognition (ASR) loss. Our results show that E3Net provides better speech and transcription quality with a lower target speaker over-suppression (TSOS) rate than the baseline model. Furthermore, we show that the KD methods can yield student models that are $2-4\times$ faster than the teacher and provides reasonable quality. Combining KD and MTL improves the ASR and TSOS metrics without degrading the speech quality.
ICASSP 2022 Deep Noise Suppression Challenge
Feb 27, 2022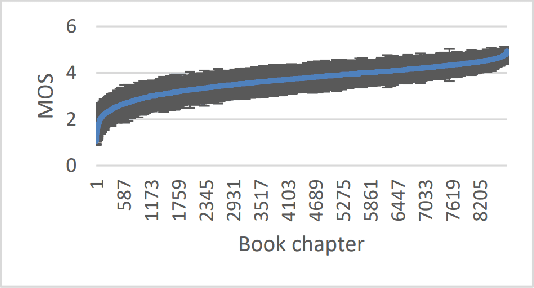
The Deep Noise Suppression (DNS) challenge is designed to foster innovation in the area of noise suppression to achieve superior perceptual speech quality. This is the 4th DNS challenge, with the previous editions held at INTERSPEECH 2020, ICASSP 2021, and INTERSPEECH 2021. We open-source datasets and test sets for researchers to train their deep noise suppression models, as well as a subjective evaluation framework based on ITU-T P.835 to rate and rank-order the challenge entries. We provide access to DNSMOS P.835 and word accuracy (WAcc) APIs to challenge participants to help with iterative model improvements. In this challenge, we introduced the following changes: (i) Included mobile device scenarios in the blind test set; (ii) Included a personalized noise suppression track with baseline; (iii) Added WAcc as an objective metric; (iv) Included DNSMOS P.835; (v) Made the training datasets and test sets fullband (48 kHz). We use an average of WAcc and subjective scores P.835 SIG, BAK, and OVRL to get the final score for ranking the DNS models. We believe that as a research community, we still have a long way to go in achieving excellent speech quality in challenging noisy real-world scenarios.