 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRADE: Benchmarking Discipline-Informed Reasoning in Image Editing
Mar 12, 2026Unified multimodal models target joint understanding, reasoning, and generation, but current image editing benchmarks are largely confined to natural images and shallow commonsense reasoning, offering limited assessment of this capability under structured, domain-specific constraints. In this work, we introduce GRADE, the first benchmark to assess discipline-informed knowledge and reasoning in image editing. GRADE comprises 520 carefully curated samples across 10 academic domains, spanning from natural science to social science. To support rigorous evaluation, we propose a multi-dimensional evaluation protocol that jointly assesses Discipline Reasoning, Visual Consistency, and Logical Readability. Extensive experiments on 20 state-of-the-art open-source and closed-source models reveal substantial limitations in current models under implicit, knowledge-intensive editing settings, leading to large performance gaps. Beyond quantitative scores, we conduct rigorous analyses and ablations to expose model shortcomings and identify the constraints within disciplinary editing. Together, GRADE pinpoints key directions for the future development of unified multimodal models, advancing the research on discipline-informed image editing and reasoning. Our benchmark and evaluation code are publicly released.
InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
Mar 10, 2026Unified multimodal models (UMMs) that integrate understanding, reasoning, generation, and editing face inherent trade-offs between maintaining strong semantic comprehension and acquiring powerful generation capabilities. In this report, we present InternVL-U, a lightweight 4B-parameter UMM that democratizes these capabilities within a unified framework. Guided by the principles of unified contextual modeling and modality-specific modular design with decoupled visual representations, InternVL-U integrates a state-of-the-art Multimodal Large Language Model (MLLM) with a specialized MMDiT-based visual generation head. To further bridge the gap between aesthetic generation and high-level intelligence, we construct a comprehensive data synthesis pipeline targeting high-semantic-density tasks, such as text rendering and scientific reasoning, under a reasoning-centric paradigm that leverages Chain-of-Thought (CoT) to better align abstract user intent with fine-grained visual generation details. Extensive experiments demonstrate that InternVL-U achieves a superior performance - efficiency balance. Despite using only 4B parameters, it consistently outperforms unified baseline models with over 3x larger scales such as BAGEL (14B) on various generation and editing tasks, while retaining strong multimodal understanding and reasoning capabilities.
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
Jun 26, 2024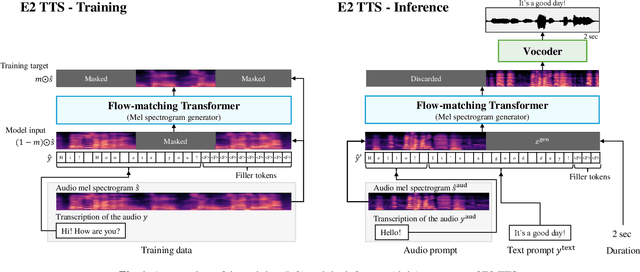
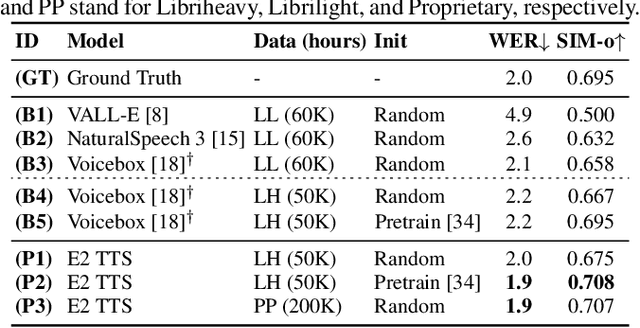
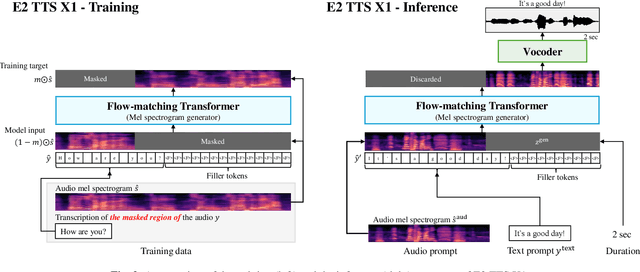
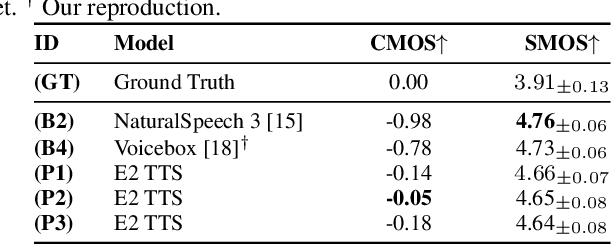
This paper introduces Embarrassingly Easy Text-to-Speech (E2 TTS), a fully non-autoregressive zero-shot text-to-speech system that offers human-level naturalness and state-of-the-art speaker similarity and intelligibility. In the E2 TTS framework, the text input is converted into a character sequence with filler tokens. The flow-matching-based mel spectrogram generator is then trained based on the audio infilling task. Unlike many previous works, it does not require additional components (e.g., duration model, grapheme-to-phoneme) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS capabilities that are comparable to or surpass previous works, including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in the input representation. We propose several variants of E2 TTS to improve usability during inference. See https://aka.ms/e2tts/ for demo samples.
An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS
Jun 09, 2024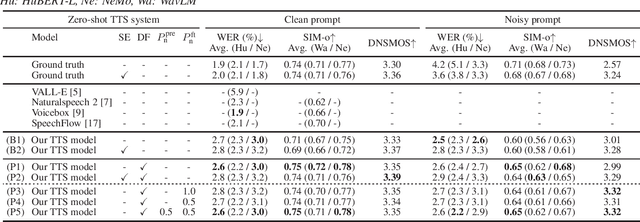
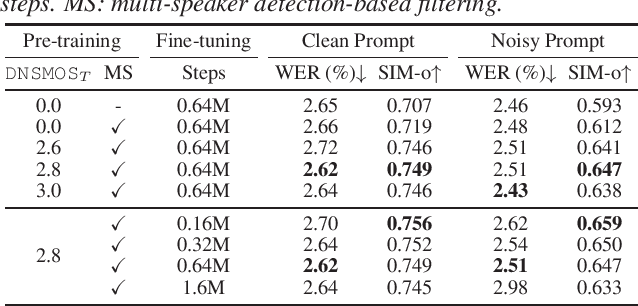
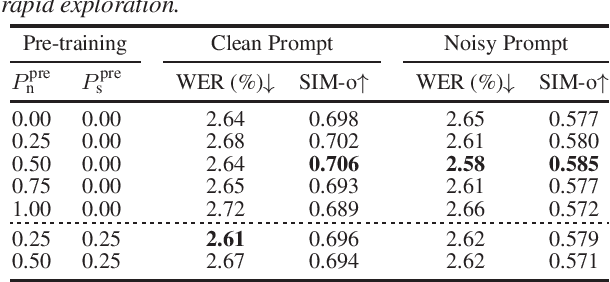
Recently, zero-shot text-to-speech (TTS) systems, capable of synthesizing any speaker's voice from a short audio prompt, have made rapid advancements. However, the quality of the generated speech significantly deteriorates when the audio prompt contains noise, and limited research has been conducted to address this issue. In this paper, we explored various strategies to enhance the quality of audio generated from noisy audio prompts within the context of flow-matching-based zero-shot TTS. Our investigation includes comprehensive training strategies: unsupervised pre-training with masked speech denoising, multi-speaker detection and DNSMOS-based data filtering on the pre-training data, and fine-tuning with random noise mixing. The results of our experiments demonstrate significant improvements in intelligibility, speaker similarity, and overall audio quality compared to the approach of applying speech enhancement to the audio prompt.
Total-Duration-Aware Duration Modeling for Text-to-Speech Systems
Jun 06, 2024



Accurate control of the total duration of generated speech by adjusting the speech rate is crucial for various text-to-speech (TTS) applications. However, the impact of adjusting the speech rate on speech quality, such as intelligibility and speaker characteristics, has been underexplored. In this work, we propose a novel total-duration-aware (TDA) duration model for TTS, where phoneme durations are predicted not only from the text input but also from an additional input of the total target duration. We also propose a MaskGIT-based duration model that enhances the diversity and quality of the predicted phoneme durations. Our results demonstrate that the proposed TDA duration models achieve better intelligibility and speaker similarity for various speech rate configurations compared to the baseline models. We also show that the proposed MaskGIT-based model can generate phoneme durations with higher quality and diversity compared to its regression or flow-matching counterparts.
Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like
Feb 12, 2024Laughter is one of the most expressive and natural aspects of human speech, conveying emotions, social cues, and humor. However, most text-to-speech (TTS) systems lack the ability to produce realistic and appropriate laughter sounds, limiting their applications and user experience. While there have been prior works to generate natural laughter, they fell short in terms of controlling the timing and variety of the laughter to be generated. In this work, we propose ELaTE, a zero-shot TTS that can generate natural laughing speech of any speaker based on a short audio prompt with precise control of laughter timing and expression. Specifically, ELaTE works on the audio prompt to mimic the voice characteristic, the text prompt to indicate the contents of the generated speech, and the input to control the laughter expression, which can be either the start and end times of laughter, or the additional audio prompt that contains laughter to be mimicked. We develop our model based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model. Through the evaluations, we show that ELaTE can generate laughing speech with significantly higher quality and controllability compared to conventional models. See https://aka.ms/elate/ for demo samples.
Real-Time Audio-Visual End-to-End Speech Enhancement
Mar 13, 2023


Audio-visual speech enhancement (AV-SE) methods utilize auxiliary visual cues to enhance speakers' voices. Therefore, technically they should be able to outperform the audio-only speech enhancement (SE) methods. However, there are few works in the literature on an AV-SE system that can work in real time on a CPU. In this paper, we propose a low-latency real-time audio-visual end-to-end enhancement (AV-E3Net) model based on the recently proposed end-to-end enhancement network (E3Net). Our main contribution includes two aspects: 1) We employ a dense connection module to solve the performance degradation caused by the deep model structure. This module significantly improves the model's performance on the AV-SE task. 2) We propose a multi-stage gating-and-summation (GS) fusion module to merge audio and visual cues. Our results show that the proposed model provides better perceptual quality and intelligibility than the baseline E3net model with a negligible computational cost increase.
VarArray: Array-Geometry-Agnostic Continuous Speech Separation
Oct 26, 2021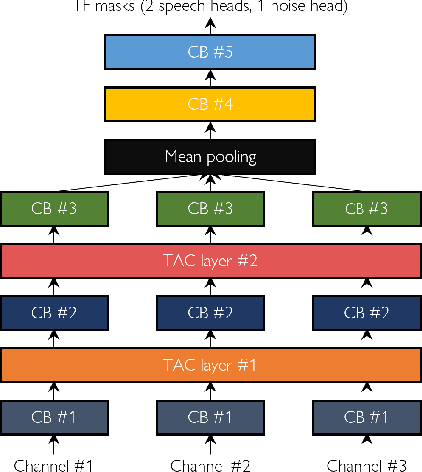
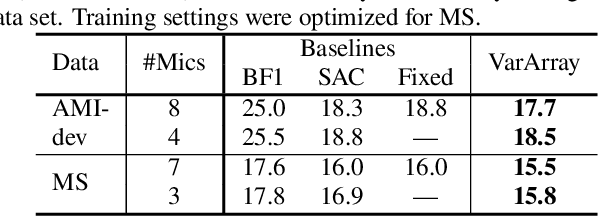
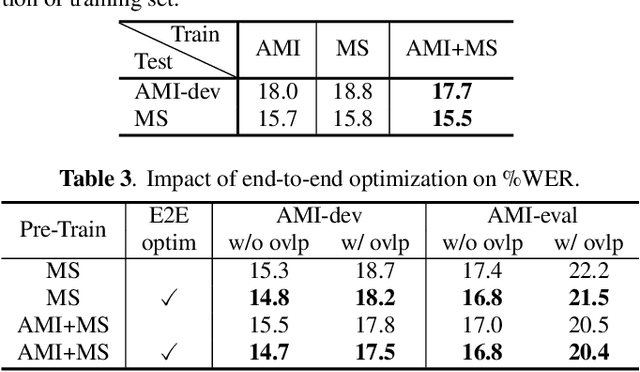
Continuous speech separation using a microphone array was shown to be promising in dealing with the speech overlap problem in natural conversation transcription. This paper proposes VarArray, an array-geometry-agnostic speech separation neural network model. The proposed model is applicable to any number of microphones without retraining while leveraging the nonlinear correlation between the input channels. The proposed method adapts different elements that were proposed before separately, including transform-average-concatenate, conformer speech separation, and inter-channel phase differences, and combines them in an efficient and cohesive way. Large-scale evaluation was performed with two real meeting transcription tasks by using a fully developed transcription system requiring no prior knowledge such as reference segmentations, which allowed us to measure the impact that the continuous speech separation system could have in realistic settings. The proposed model outperformed a previous approach to array-geometry-agnostic modeling for all of the geometry configurations considered, achieving asclite-based speaker-agnostic word error rates of 17.5% and 20.4% for the AMI development and evaluation sets, respectively, in the end-to-end setting using no ground-truth segmentations.
Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement
Jun 05, 2021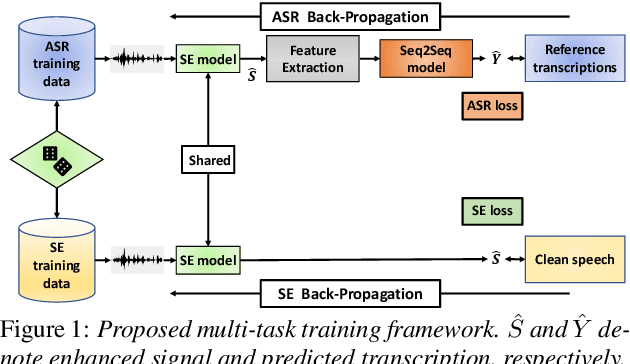
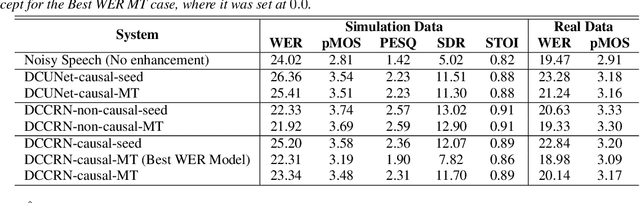
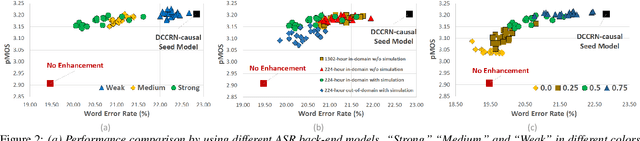
With the surge of online meetings, it has become more critical than ever to provide high-quality speech audio and live captioning under various noise conditions. However, most monaural speech enhancement (SE) models introduce processing artifacts and thus degrade the performance of downstream tasks, including automatic speech recognition (ASR). This paper proposes a multi-task training framework to make the SE models unharmful to ASR. Because most ASR training samples do not have corresponding clean signal references, we alternately perform two model update steps called SE-step and ASR-step. The SE-step uses clean and noisy signal pairs and a signal-based loss function. The ASR-step applies a pre-trained ASR model to training signals enhanced with the SE model. A cross-entropy loss between the ASR output and reference transcriptions is calculated to update the SE model parameters. Experimental results with realistic large-scale settings using ASR models trained on 75,000-hour data show that the proposed framework improves the word error rate for the SE output by 11.82% with little compromise in the SE quality. Performance analysis is also carried out by changing the ASR model, the data used for the ASR-step, and the schedule of the two update steps.