 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Jan 27, 2026Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Improving Practical Aspects of End-to-End Multi-Talker Speech Recognition for Online and Offline Scenarios
Jun 17, 2025We extend the frameworks of Serialized Output Training (SOT) to address practical needs of both streaming and offline automatic speech recognition (ASR) applications. Our approach focuses on balancing latency and accuracy, catering to real-time captioning and summarization requirements. We propose several key improvements: (1) Leveraging Continuous Speech Separation (CSS) single-channel front-end with end-to-end (E2E) systems for highly overlapping scenarios, challenging the conventional wisdom of E2E versus cascaded setups. The CSS framework improves the accuracy of the ASR system by separating overlapped speech from multiple speakers. (2) Implementing dual models -- Conformer Transducer for streaming and Sequence-to-Sequence for offline -- or alternatively, a two-pass model based on cascaded encoders. (3) Exploring segment-based SOT (segSOT) which is better suited for offline scenarios while also enhancing readability of multi-talker transcriptions.
Streaming Speaker Change Detection and Gender Classification for Transducer-Based Multi-Talker Speech Translation
Feb 04, 2025



Streaming multi-talker speech translation is a task that involves not only generating accurate and fluent translations with low latency but also recognizing when a speaker change occurs and what the speaker's gender is. Speaker change information can be used to create audio prompts for a zero-shot text-to-speech system, and gender can help to select speaker profiles in a conventional text-to-speech model. We propose to tackle streaming speaker change detection and gender classification by incorporating speaker embeddings into a transducer-based streaming end-to-end speech translation model. Our experiments demonstrate that the proposed methods can achieve high accuracy for both speaker change detection and gender classification.
Summary of the NOTSOFAR-1 Challenge: Highlights and Learnings
Jan 28, 2025



The first Natural Office Talkers in Settings of Far-field Audio Recordings (NOTSOFAR-1) Challenge is a pivotal initiative that sets new benchmarks by offering datasets more representative of the needs of real-world business applications than those previously available. The challenge provides a unique combination of 280 recorded meetings across 30 diverse environments, capturing real-world acoustic conditions and conversational dynamics, and a 1000-hour simulated training dataset, synthesized with enhanced authenticity for real-world generalization, incorporating 15,000 real acoustic transfer functions. In this paper, we provide an overview of the systems submitted to the challenge and analyze the top-performing approaches, hypothesizing the factors behind their success. Additionally, we highlight promising directions left unexplored by participants. By presenting key findings and actionable insights, this work aims to drive further innovation and progress in DASR research and applications.
TS3-Codec: Transformer-Based Simple Streaming Single Codec
Nov 27, 2024



Neural audio codecs (NACs) have garnered significant attention as key technologies for audio compression as well as audio representation for speech language models. While mainstream NAC models are predominantly convolution-based, the performance of NACs with a purely transformer-based, and convolution-free architecture remains unexplored. This paper introduces TS3-Codec, a Transformer-Based Simple Streaming Single Codec. TS3-Codec consists of only a stack of transformer layers with a few linear layers, offering greater simplicity and expressiveness by fully eliminating convolution layers that require careful hyperparameter tuning and large computations. Under the streaming setup, the proposed TS3-Codec achieves comparable or superior performance compared to the codec with state-of-the-art convolution-based architecture while requiring only 12% of the computation and 77% of bitrate. Furthermore, it significantly outperforms the convolution-based codec when using similar computational resources.
Laugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
Jul 17, 2024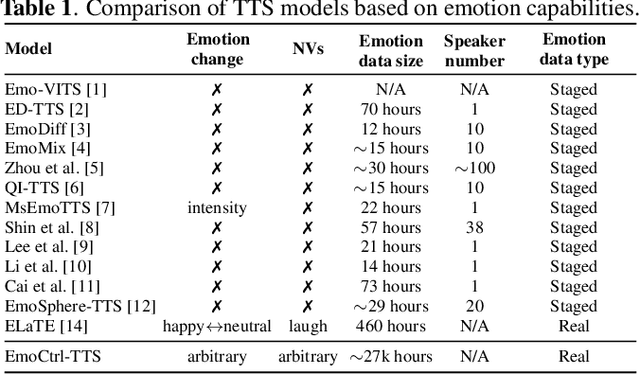
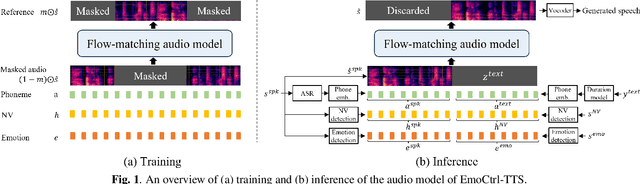
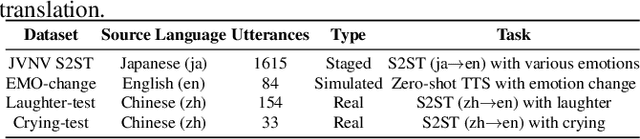
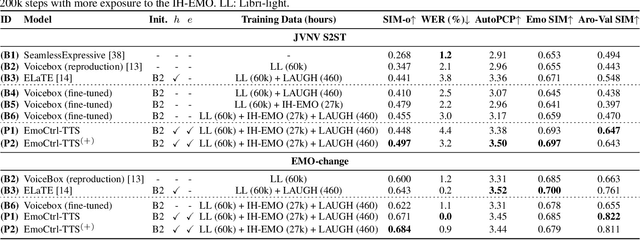
People change their tones of voice, often accompanied by nonverbal vocalizations (NVs) such as laughter and cries, to convey rich emotions. However, most text-to-speech (TTS) systems lack the capability to generate speech with rich emotions, including NVs. This paper introduces EmoCtrl-TTS, an emotion-controllable zero-shot TTS that can generate highly emotional speech with NVs for any speaker. EmoCtrl-TTS leverages arousal and valence values, as well as laughter embeddings, to condition the flow-matching-based zero-shot TTS. To achieve high-quality emotional speech generation, EmoCtrl-TTS is trained using more than 27,000 hours of expressive data curated based on pseudo-labeling. Comprehensive evaluations demonstrate that EmoCtrl-TTS excels in mimicking the emotions of audio prompts in speech-to-speech translation scenarios. We also show that EmoCtrl-TTS can capture emotion changes, express strong emotions, and generate various NVs in zero-shot TTS. See https://aka.ms/emoctrl-tts for demo samples.
E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
Jun 26, 2024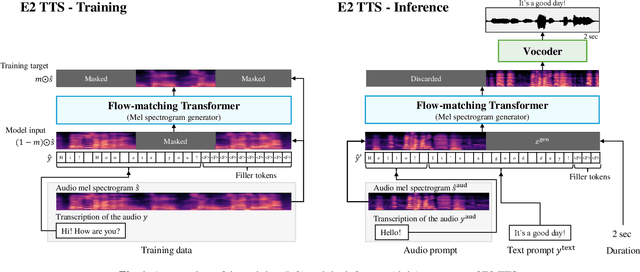
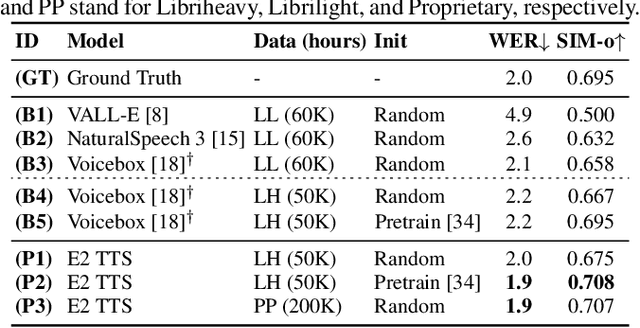
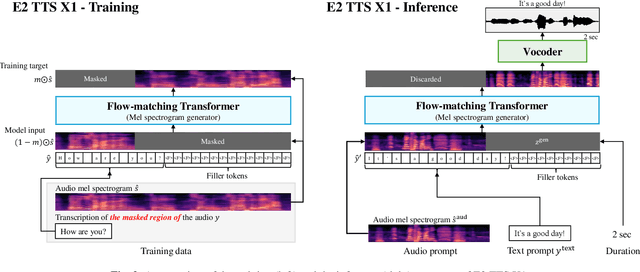
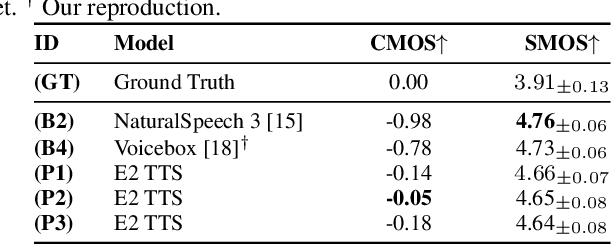
This paper introduces Embarrassingly Easy Text-to-Speech (E2 TTS), a fully non-autoregressive zero-shot text-to-speech system that offers human-level naturalness and state-of-the-art speaker similarity and intelligibility. In the E2 TTS framework, the text input is converted into a character sequence with filler tokens. The flow-matching-based mel spectrogram generator is then trained based on the audio infilling task. Unlike many previous works, it does not require additional components (e.g., duration model, grapheme-to-phoneme) or complex techniques (e.g., monotonic alignment search). Despite its simplicity, E2 TTS achieves state-of-the-art zero-shot TTS capabilities that are comparable to or surpass previous works, including Voicebox and NaturalSpeech 3. The simplicity of E2 TTS also allows for flexibility in the input representation. We propose several variants of E2 TTS to improve usability during inference. See https://aka.ms/e2tts/ for demo samples.
An Investigation of Noise Robustness for Flow-Matching-Based Zero-Shot TTS
Jun 09, 2024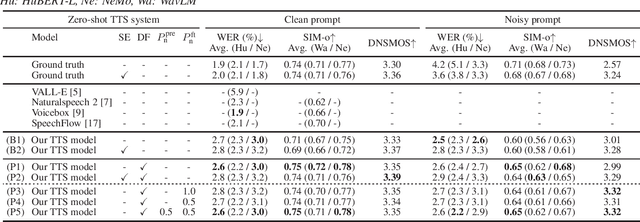
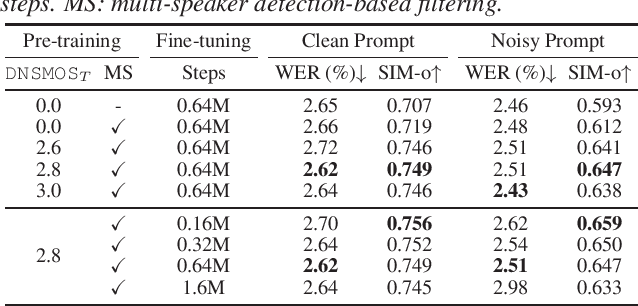
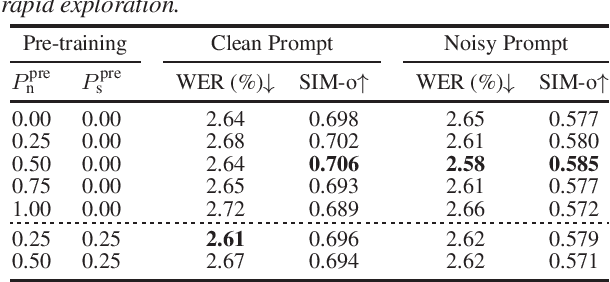
Recently, zero-shot text-to-speech (TTS) systems, capable of synthesizing any speaker's voice from a short audio prompt, have made rapid advancements. However, the quality of the generated speech significantly deteriorates when the audio prompt contains noise, and limited research has been conducted to address this issue. In this paper, we explored various strategies to enhance the quality of audio generated from noisy audio prompts within the context of flow-matching-based zero-shot TTS. Our investigation includes comprehensive training strategies: unsupervised pre-training with masked speech denoising, multi-speaker detection and DNSMOS-based data filtering on the pre-training data, and fine-tuning with random noise mixing. The results of our experiments demonstrate significant improvements in intelligibility, speaker similarity, and overall audio quality compared to the approach of applying speech enhancement to the audio prompt.
Total-Duration-Aware Duration Modeling for Text-to-Speech Systems
Jun 06, 2024



Accurate control of the total duration of generated speech by adjusting the speech rate is crucial for various text-to-speech (TTS) applications. However, the impact of adjusting the speech rate on speech quality, such as intelligibility and speaker characteristics, has been underexplored. In this work, we propose a novel total-duration-aware (TDA) duration model for TTS, where phoneme durations are predicted not only from the text input but also from an additional input of the total target duration. We also propose a MaskGIT-based duration model that enhances the diversity and quality of the predicted phoneme durations. Our results demonstrate that the proposed TDA duration models achieve better intelligibility and speaker similarity for various speech rate configurations compared to the baseline models. We also show that the proposed MaskGIT-based model can generate phoneme durations with higher quality and diversity compared to its regression or flow-matching counterparts.