 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM can Read Spectrogram: Encoder-free Speech-Language Modeling
Jun 08, 2026Recent speech-aware large language models (Speech-LLMs) rely on a pre-trained speech encoder to convert audio into semantic-rich representations consumable by LLM. In this work, instead, we explore: can an LLM learn to read Mel spectrogram directly without a dedicated speech encoder? We propose Mel-LLM, an encoder-free Speech-LLM that feeds lightly pre-processed Mel spectrogram patches directly into the LLM through a linear projection, allowing the LLM to learn speech-text alignment purely through its own parameters. We conduct extensive experiments on both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. For ASR, we evaluate on the OpenASR leaderboard public sets and production-level scaling experiments, demonstrating that the encoder-free solution achieves competitive performance with only limited degradation compared to encoder-initialized counterparts. We find that when data is limited, initialization from a multimodal checkpoint (Phi-4-MM) is crucial for maintaining performance. We also present ablation studies revealing which LLM layers are less relevant to speech encoding. For TTS, we show preliminary results with a next-token VAE approach. While TTS performance is not yet optimal, these results establish the feasibility of a fully unified encoder-free architecture for autoregressive speech-text modeling.
Partially Observable Adversarial Patch Attacks on Vision-Language-Action Models in Robotics
Jun 02, 2026Vision-language-action (VLA) models are gaining attention in robotics, yet their robustness to adversarial attacks remains largely unexplored. Existing work shows that adversarial patches can mislead VLA-based robots but assumes full access to the entire execution trajectory, an unrealistic requirement in practice. We address this limitation by formulating a partially observable threat model, where the adversary can exploit only a short prefix of the trajectory to generate a fixed patch applied to all subsequent frames. Under this setting, we propose a two-phase framework. First, we localize the patch using the model's attention maps to identify visually critical regions that correspond to the full instruction. Then, we optimize the patch to disrupt the semantic grounding of target objects and increase the curvature of action trajectories, thereby compounding failures in both perception and control. Extensive experiments in simulation and real-world robotic environments show that our method sustains adversarial effects under partial observability, inducing long-horizon disruptions and significantly reducing task success rates.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Rethinking Transferable Adversarial Attacks on Point Clouds from a Compact Subspace Perspective
Jan 30, 2026Transferable adversarial attacks on point clouds remain challenging, as existing methods often rely on model-specific gradients or heuristics that limit generalization to unseen architectures. In this paper, we rethink adversarial transferability from a compact subspace perspective and propose CoSA, a transferable attack framework that operates within a shared low-dimensional semantic space. Specifically, each point cloud is represented as a compact combination of class-specific prototypes that capture shared semantic structure, while adversarial perturbations are optimized within a low-rank subspace to induce coherent and architecture-agnostic variations. This design suppresses model-dependent noise and constrains perturbations to semantically meaningful directions, thereby improving cross-model transferability without relying on surrogate-specific artifacts. Extensive experiments on multiple datasets and network architectures demonstrate that CoSA consistently outperforms state-of-the-art transferable attacks, while maintaining competitive imperceptibility and robustness under common defense strategies. Codes will be made public upon paper acceptance.
Optimal Transport-Induced Samples against Out-of-Distribution Overconfidence
Jan 29, 2026Deep neural networks (DNNs) often produce overconfident predictions on out-of-distribution (OOD) inputs, undermining their reliability in open-world environments. Singularities in semi-discrete optimal transport (OT) mark regions of semantic ambiguity, where classifiers are particularly prone to unwarranted high-confidence predictions. Motivated by this observation, we propose a principled framework to mitigate OOD overconfidence by leveraging the geometry of OT-induced singular boundaries. Specifically, we formulate an OT problem between a continuous base distribution and the latent embeddings of training data, and identify the resulting singular boundaries. By sampling near these boundaries, we construct a class of OOD inputs, termed optimal transport-induced OOD samples (OTIS), which are geometrically grounded and inherently semantically ambiguous. During training, a confidence suppression loss is applied to OTIS to guide the model toward more calibrated predictions in structurally uncertain regions. Extensive experiments show that our method significantly alleviates OOD overconfidence and outperforms state-of-the-art methods.
ProImage-Bench: Rubric-Based Evaluation for Professional Image Generation
Dec 13, 2025We study professional image generation, where a model must synthesize information-dense, scientifically precise illustrations from technical descriptions rather than merely produce visually plausible pictures. To quantify the progress, we introduce ProImage-Bench, a rubric-based benchmark that targets biology schematics, engineering/patent drawings, and general scientific diagrams. For 654 figures collected from real textbooks and technical reports, we construct detailed image instructions and a hierarchy of rubrics that decompose correctness into 6,076 criteria and 44,131 binary checks. Rubrics are derived from surrounding text and reference figures using large multimodal models, and are evaluated by an automated LMM-based judge with a principled penalty scheme that aggregates sub-question outcomes into interpretable criterion scores. We benchmark several representative text-to-image models on ProImage-Bench and find that, despite strong open-domain performance, the best base model reaches only 0.791 rubric accuracy and 0.553 criterion score overall, revealing substantial gaps in fine-grained scientific fidelity. Finally, we show that the same rubrics provide actionable supervision: feeding failed checks back into an editing model for iterative refinement boosts a strong generator from 0.653 to 0.865 in rubric accuracy and from 0.388 to 0.697 in criterion score. ProImage-Bench thus offers both a rigorous diagnostic for professional image generation and a scalable signal for improving specification-faithful scientific illustrations.
ScaleDL: Towards Scalable and Efficient Runtime Prediction for Distributed Deep Learning Workloads
Nov 13, 2025Deep neural networks (DNNs) form the cornerstone of modern AI services, supporting a wide range of applications, including autonomous driving, chatbots, and recommendation systems. As models increase in size and complexity, DNN workloads such as training and inference tasks impose unprecedented demands on distributed computing resources, making accurate runtime prediction essential for optimizing development and resource allocation. Traditional methods rely on additive computational unit models, limiting their accuracy and generalizability. In contrast, graph-enhanced modeling improves performance but significantly increases data collection costs. Therefore, there is a critical need for a method that strikes a balance between accuracy, generalizability, and data collection costs. To address these challenges, we propose ScaleDL, a novel runtime prediction framework that combines nonlinear layer-wise modeling with graph neural network (GNN)-based cross-layer interaction mechanism, enabling accurate DNN runtime prediction and hierarchical generalizability across different network architectures. Additionally, we employ the D-optimal method to reduce data collection costs. Experiments on the workloads of five popular DNN models demonstrate that ScaleDL enhances runtime prediction accuracy and generalizability, achieving 6 times lower MRE and 5 times lower RMSE compared to baseline models.
SHANKS: Simultaneous Hearing and Thinking for Spoken Language Models
Oct 08, 2025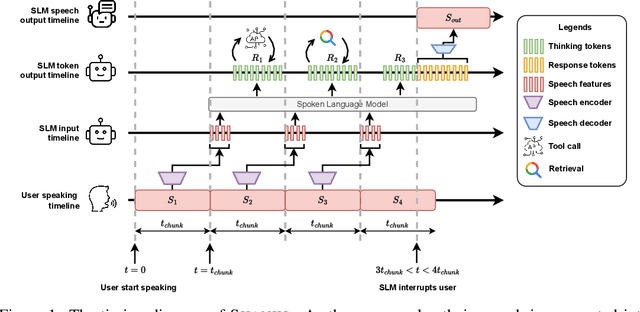
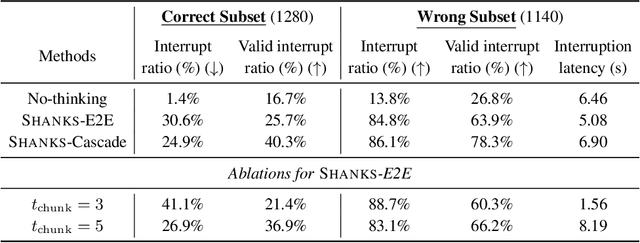

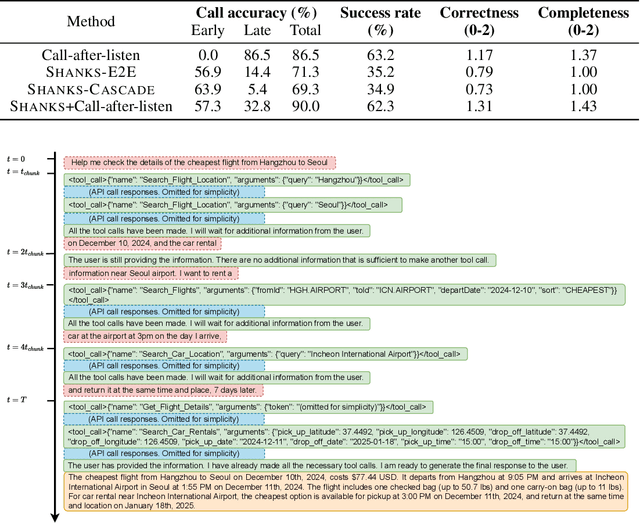
Current large language models (LLMs) and spoken language models (SLMs) begin thinking and taking actions only after the user has finished their turn. This prevents the model from interacting during the user's turn and can lead to high response latency while it waits to think. Consequently, thinking after receiving the full input is not suitable for speech-to-speech interaction, where real-time, low-latency exchange is important. We address this by noting that humans naturally "think while listening." In this paper, we propose SHANKS, a general inference framework that enables SLMs to generate unspoken chain-of-thought reasoning while listening to the user input. SHANKS streams the input speech in fixed-duration chunks and, as soon as a chunk is received, generates unspoken reasoning based on all previous speech and reasoning, while the user continues speaking. SHANKS uses this unspoken reasoning to decide whether to interrupt the user and to make tool calls to complete the task. We demonstrate that SHANKS enhances real-time user-SLM interaction in two scenarios: (1) when the user is presenting a step-by-step solution to a math problem, SHANKS can listen, reason, and interrupt when the user makes a mistake, achieving 37.1% higher interruption accuracy than a baseline that interrupts without thinking; and (2) in a tool-augmented dialogue, SHANKS can complete 56.9% of the tool calls before the user finishes their turn. Overall, SHANKS moves toward models that keep thinking throughout the conversation, not only after a turn ends. Animated illustrations of Shanks can be found at https://d223302.github.io/SHANKS/
Improving Practical Aspects of End-to-End Multi-Talker Speech Recognition for Online and Offline Scenarios
Jun 17, 2025We extend the frameworks of Serialized Output Training (SOT) to address practical needs of both streaming and offline automatic speech recognition (ASR) applications. Our approach focuses on balancing latency and accuracy, catering to real-time captioning and summarization requirements. We propose several key improvements: (1) Leveraging Continuous Speech Separation (CSS) single-channel front-end with end-to-end (E2E) systems for highly overlapping scenarios, challenging the conventional wisdom of E2E versus cascaded setups. The CSS framework improves the accuracy of the ASR system by separating overlapped speech from multiple speakers. (2) Implementing dual models -- Conformer Transducer for streaming and Sequence-to-Sequence for offline -- or alternatively, a two-pass model based on cascaded encoders. (3) Exploring segment-based SOT (segSOT) which is better suited for offline scenarios while also enhancing readability of multi-talker transcriptions.
MetaEformer: Unveiling and Leveraging Meta-patterns for Complex and Dynamic Systems Load Forecasting
Jun 15, 2025Time series forecasting is a critical and practical problem in many real-world applications, especially for industrial scenarios, where load forecasting underpins the intelligent operation of modern systems like clouds, power grids and traffic networks.However, the inherent complexity and dynamics of these systems present significant challenges. Despite advances in methods such as pattern recognition and anti-non-stationarity have led to performance gains, current methods fail to consistently ensure effectiveness across various system scenarios due to the intertwined issues of complex patterns, concept-drift, and few-shot problems. To address these challenges simultaneously, we introduce a novel scheme centered on fundamental waveform, a.k.a., meta-pattern. Specifically, we develop a unique Meta-pattern Pooling mechanism to purify and maintain meta-patterns, capturing the nuanced nature of system loads. Complementing this, the proposed Echo mechanism adaptively leverages the meta-patterns, enabling a flexible and precise pattern reconstruction. Our Meta-pattern Echo transformer (MetaEformer) seamlessly incorporates these mechanisms with the transformer-based predictor, offering end-to-end efficiency and interpretability of core processes. Demonstrating superior performance across eight benchmarks under three system scenarios, MetaEformer marks a significant advantage in accuracy, with a 37% relative improvement on fifteen state-of-the-art baselines.