 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio ControlNet for Fine-Grained Audio Generation and Editing
Feb 04, 2026We study the fine-grained text-to-audio (T2A) generation task. While recent models can synthesize high-quality audio from text descriptions, they often lack precise control over attributes such as loudness, pitch, and sound events. Unlike prior approaches that retrain models for specific control types, we propose to train ControlNet models on top of pre-trained T2A backbones to achieve controllable generation over loudness, pitch, and event roll. We introduce two designs, T2A-ControlNet and T2A-Adapter, and show that the T2A-Adapter model offers a more efficient structure with strong control ability. With only 38M additional parameters, T2A-Adapter achieves state-of-the-art performance on the AudioSet-Strong in both event-level and segment-level F1 scores. We further extend this framework to audio editing, proposing T2A-Editor for removing and inserting audio events at time locations specified by instructions. Models, code, dataset pipelines, and benchmarks will be released to support future research on controllable audio generation and editing.
VIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
A Unified Neural Codec Language Model for Selective Editable Text to Speech Generation
Jan 18, 2026Neural codec language models achieve impressive zero-shot Text-to-Speech (TTS) by fully imitating the acoustic characteristics of a short speech prompt, including timbre, prosody, and paralinguistic information. However, such holistic imitation limits their ability to isolate and control individual attributes. In this paper, we present a unified codec language model SpeechEdit that extends zero-shot TTS with a selective control mechanism. By default, SpeechEdit reproduces the complete acoustic profile inferred from the speech prompt, but it selectively overrides only the attributes specified by explicit control instructions. To enable controllable modeling, SpeechEdit is trained on our newly constructed LibriEdit dataset, which provides delta (difference-aware) training pairs derived from LibriHeavy. Experimental results show that our approach maintains naturalness and robustness while offering flexible and localized control over desired attributes. Audio samples are available at https://speech-editing.github.io/speech-editing/.
VibeVoice Technical Report
Aug 26, 2025This report presents VibeVoice, a novel model designed to synthesize long-form speech with multiple speakers by employing next-token diffusion, which is a unified method for modeling continuous data by autoregressively generating latent vectors via diffusion. To enable this, we introduce a novel continuous speech tokenizer that, when compared to the popular Encodec model, improves data compression by 80 times while maintaining comparable performance. The tokenizer effectively preserves audio fidelity while significantly boosting computational efficiency for processing long sequences. Thus, VibeVoice can synthesize long-form speech for up to 90 minutes (in a 64K context window length) with a maximum of 4 speakers, capturing the authentic conversational ``vibe'' and surpassing open-source and proprietary dialogue models.
LeVo: High-Quality Song Generation with Multi-Preference Alignment
Jun 09, 2025



Recent advances in large language models (LLMs) and audio language models have significantly improved music generation, particularly in lyrics-to-song generation. However, existing approaches still struggle with the complex composition of songs and the scarcity of high-quality data, leading to limitations in sound quality, musicality, instruction following, and vocal-instrument harmony. To address these challenges, we introduce LeVo, an LM-based framework consisting of LeLM and a music codec. LeLM is capable of parallelly modeling two types of tokens: mixed tokens, which represent the combined audio of vocals and accompaniment to achieve vocal-instrument harmony, and dual-track tokens, which separately encode vocals and accompaniment for high-quality song generation. It employs two decoder-only transformers and a modular extension training strategy to prevent interference between different token types. To further enhance musicality and instruction following, we introduce a multi-preference alignment method based on Direct Preference Optimization (DPO). This method handles diverse human preferences through a semi-automatic data construction process and DPO post-training. Experimental results demonstrate that LeVo consistently outperforms existing methods on both objective and subjective metrics. Ablation studies further justify the effectiveness of our designs. Audio examples are available at https://levo-demo.github.io/.
SongBloom: Coherent Song Generation via Interleaved Autoregressive Sketching and Diffusion Refinement
Jun 09, 2025Generating music with coherent structure, harmonious instrumental and vocal elements remains a significant challenge in song generation. Existing language models and diffusion-based methods often struggle to balance global coherence with local fidelity, resulting in outputs that lack musicality or suffer from incoherent progression and mismatched lyrics. This paper introduces $\textbf{SongBloom}$, a novel framework for full-length song generation that leverages an interleaved paradigm of autoregressive sketching and diffusion-based refinement. SongBloom employs an autoregressive diffusion model that combines the high fidelity of diffusion models with the scalability of language models. Specifically, it gradually extends a musical sketch from short to long and refines the details from coarse to fine-grained. The interleaved generation paradigm effectively integrates prior semantic and acoustic context to guide the generation process. Experimental results demonstrate that SongBloom outperforms existing methods across both subjective and objective metrics and achieves performance comparable to the state-of-the-art commercial music generation platforms. Audio samples are available on our demo page: https://cypress-yang.github.io/SongBloom\_demo.
WAKE: Watermarking Audio with Key Enrichment
Jun 06, 2025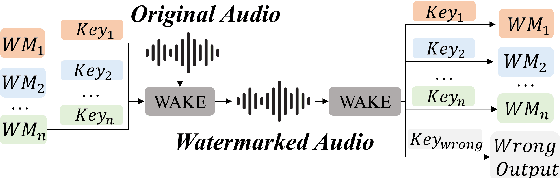

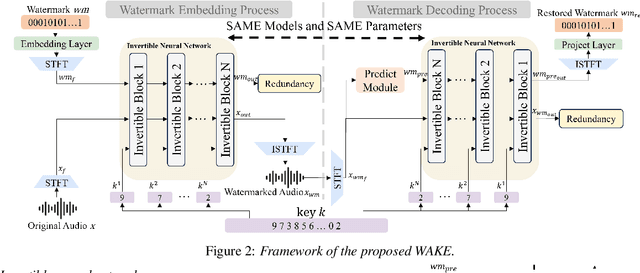
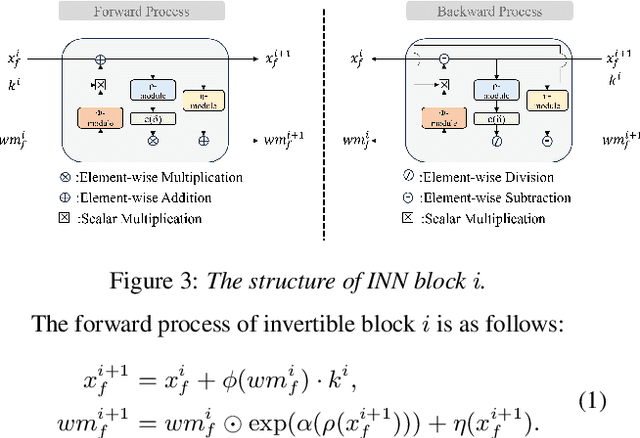
As deep learning advances in audio generation, challenges in audio security and copyright protection highlight the need for robust audio watermarking. Recent neural network-based methods have made progress but still face three main issues: preventing unauthorized access, decoding initial watermarks after multiple embeddings, and embedding varying lengths of watermarks. To address these issues, we propose WAKE, the first key-controllable audio watermark framework. WAKE embeds watermarks using specific keys and recovers them with corresponding keys, enhancing security by making incorrect key decoding impossible. It also resolves the overwriting issue by allowing watermark decoding after multiple embeddings and supports variable-length watermark insertion. WAKE outperforms existing models in both watermarked audio quality and watermark detection accuracy. Code, more results, and demo page: https://thuhcsi.github.io/WAKE.
Towards Efficient Speech-Text Jointly Decoding within One Speech Language Model
Jun 04, 2025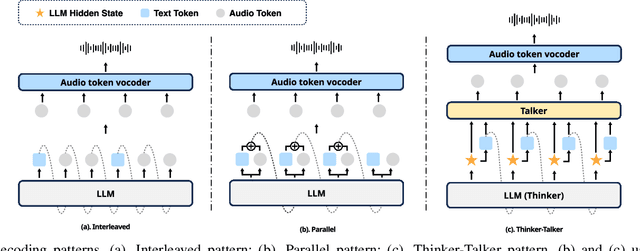
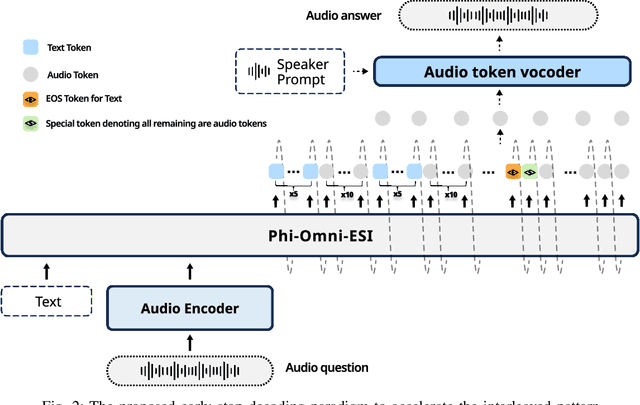


Speech language models (Speech LMs) enable end-to-end speech-text modelling within a single model, offering a promising direction for spoken dialogue systems. The choice of speech-text jointly decoding paradigm plays a critical role in performance, efficiency, and alignment quality. In this work, we systematically compare representative joint speech-text decoding strategies-including the interleaved, and parallel generation paradigms-under a controlled experimental setup using the same base language model, speech tokenizer and training data. Our results show that the interleaved approach achieves the best alignment. However it suffers from slow inference due to long token sequence length. To address this, we propose a novel early-stop interleaved (ESI) pattern that not only significantly accelerates decoding but also yields slightly better performance. Additionally, we curate high-quality question answering (QA) datasets to further improve speech QA performance.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025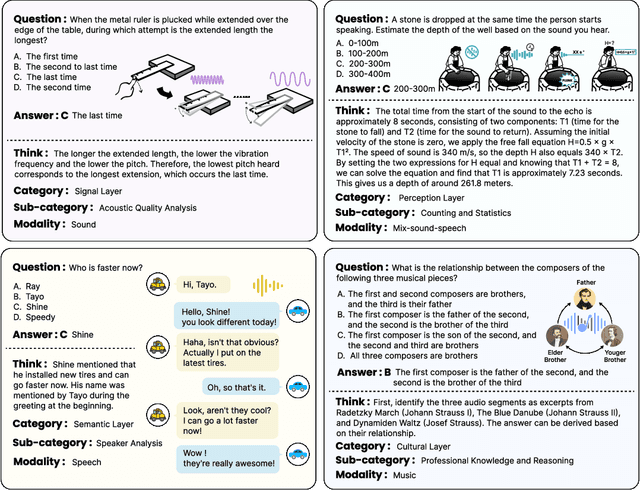

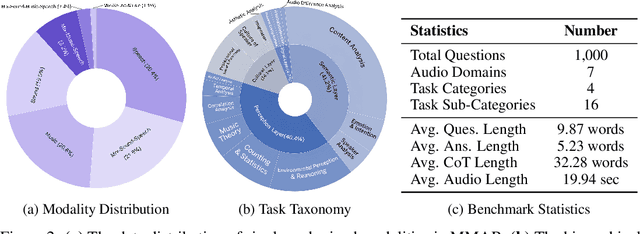
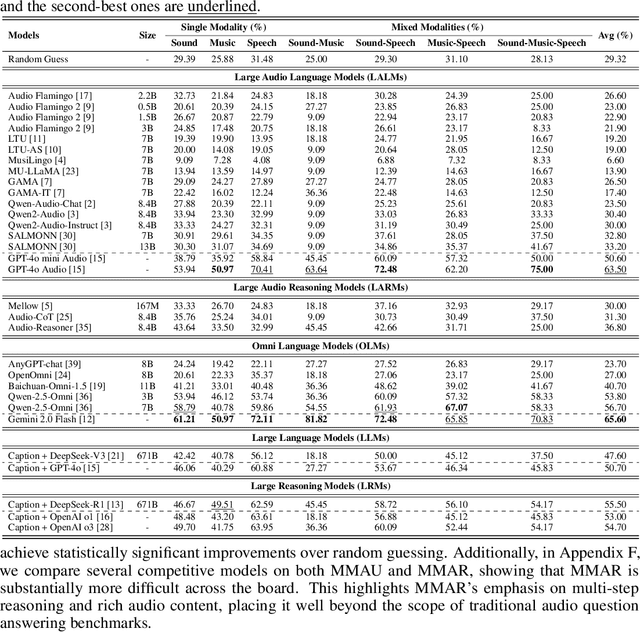
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.