 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Hallucination-Free Music: A Reinforcement Learning Preference Optimization Framework for Reliable Song Generation
Aug 07, 2025Recent advances in audio-based generative language models have accelerated AI-driven lyric-to-song generation. However, these models frequently suffer from content hallucination, producing outputs misaligned with the input lyrics and undermining musical coherence. Current supervised fine-tuning (SFT) approaches, limited by passive label-fitting, exhibit constrained self-improvement and poor hallucination mitigation. To address this core challenge, we propose a novel reinforcement learning (RL) framework leveraging preference optimization for hallucination control. Our key contributions include: (1) Developing a robust hallucination preference dataset constructed via phoneme error rate (PER) computation and rule-based filtering to capture alignment with human expectations; (2) Implementing and evaluating three distinct preference optimization strategies within the RL framework: Direct Preference Optimization (DPO), Proximal Policy Optimization (PPO), and Group Relative Policy Optimization (GRPO). DPO operates off-policy to enhance positive token likelihood, achieving a significant 7.4% PER reduction. PPO and GRPO employ an on-policy approach, training a PER-based reward model to iteratively optimize sequences via reward maximization and KL-regularization, yielding PER reductions of 4.9% and 4.7%, respectively. Comprehensive objective and subjective evaluations confirm that our methods effectively suppress hallucinations while preserving musical quality. Crucially, this work presents a systematic, RL-based solution to hallucination control in lyric-to-song generation. The framework's transferability also unlocks potential for music style adherence and musicality enhancement, opening new avenues for future generative song research.
LeVo: High-Quality Song Generation with Multi-Preference Alignment
Jun 09, 2025



Recent advances in large language models (LLMs) and audio language models have significantly improved music generation, particularly in lyrics-to-song generation. However, existing approaches still struggle with the complex composition of songs and the scarcity of high-quality data, leading to limitations in sound quality, musicality, instruction following, and vocal-instrument harmony. To address these challenges, we introduce LeVo, an LM-based framework consisting of LeLM and a music codec. LeLM is capable of parallelly modeling two types of tokens: mixed tokens, which represent the combined audio of vocals and accompaniment to achieve vocal-instrument harmony, and dual-track tokens, which separately encode vocals and accompaniment for high-quality song generation. It employs two decoder-only transformers and a modular extension training strategy to prevent interference between different token types. To further enhance musicality and instruction following, we introduce a multi-preference alignment method based on Direct Preference Optimization (DPO). This method handles diverse human preferences through a semi-automatic data construction process and DPO post-training. Experimental results demonstrate that LeVo consistently outperforms existing methods on both objective and subjective metrics. Ablation studies further justify the effectiveness of our designs. Audio examples are available at https://levo-demo.github.io/.
SongBloom: Coherent Song Generation via Interleaved Autoregressive Sketching and Diffusion Refinement
Jun 09, 2025Generating music with coherent structure, harmonious instrumental and vocal elements remains a significant challenge in song generation. Existing language models and diffusion-based methods often struggle to balance global coherence with local fidelity, resulting in outputs that lack musicality or suffer from incoherent progression and mismatched lyrics. This paper introduces $\textbf{SongBloom}$, a novel framework for full-length song generation that leverages an interleaved paradigm of autoregressive sketching and diffusion-based refinement. SongBloom employs an autoregressive diffusion model that combines the high fidelity of diffusion models with the scalability of language models. Specifically, it gradually extends a musical sketch from short to long and refines the details from coarse to fine-grained. The interleaved generation paradigm effectively integrates prior semantic and acoustic context to guide the generation process. Experimental results demonstrate that SongBloom outperforms existing methods across both subjective and objective metrics and achieves performance comparable to the state-of-the-art commercial music generation platforms. Audio samples are available on our demo page: https://cypress-yang.github.io/SongBloom\_demo.
XMusic: Towards a Generalized and Controllable Symbolic Music Generation Framework
Jan 15, 2025



In recent years, remarkable advancements in artificial intelligence-generated content (AIGC) have been achieved in the fields of image synthesis and text generation, generating content comparable to that produced by humans. However, the quality of AI-generated music has not yet reached this standard, primarily due to the challenge of effectively controlling musical emotions and ensuring high-quality outputs. This paper presents a generalized symbolic music generation framework, XMusic, which supports flexible prompts (i.e., images, videos, texts, tags, and humming) to generate emotionally controllable and high-quality symbolic music. XMusic consists of two core components, XProjector and XComposer. XProjector parses the prompts of various modalities into symbolic music elements (i.e., emotions, genres, rhythms and notes) within the projection space to generate matching music. XComposer contains a Generator and a Selector. The Generator generates emotionally controllable and melodious music based on our innovative symbolic music representation, whereas the Selector identifies high-quality symbolic music by constructing a multi-task learning scheme involving quality assessment, emotion recognition, and genre recognition tasks. In addition, we build XMIDI, a large-scale symbolic music dataset that contains 108,023 MIDI files annotated with precise emotion and genre labels. Objective and subjective evaluations show that XMusic significantly outperforms the current state-of-the-art methods with impressive music quality. Our XMusic has been awarded as one of the nine Highlights of Collectibles at WAIC 2023. The project homepage of XMusic is https://xmusic-project.github.io.
MuQ: Self-Supervised Music Representation Learning with Mel Residual Vector Quantization
Jan 03, 2025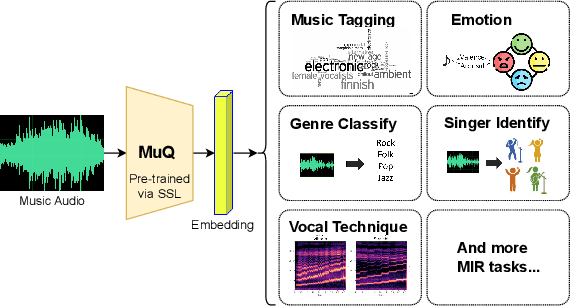



Recent years have witnessed the success of foundation models pre-trained with self-supervised learning (SSL) in various music informatics understanding tasks, including music tagging, instrument classification, key detection, and more. In this paper, we propose a self-supervised music representation learning model for music understanding. Distinguished from previous studies adopting random projection or existing neural codec, the proposed model, named MuQ, is trained to predict tokens generated by Mel Residual Vector Quantization (Mel-RVQ). Our Mel-RVQ utilizes residual linear projection structure for Mel spectrum quantization to enhance the stability and efficiency of target extraction and lead to better performance. Experiments in a large variety of downstream tasks demonstrate that MuQ outperforms previous self-supervised music representation models with only 0.9K hours of open-source pre-training data. Scaling up the data to over 160K hours and adopting iterative training consistently improve the model performance. To further validate the strength of our model, we present MuQ-MuLan, a joint music-text embedding model based on contrastive learning, which achieves state-of-the-art performance in the zero-shot music tagging task on the MagnaTagATune dataset. Code and checkpoints are open source in https://github.com/tencent-ailab/MuQ.
SongEditor: Adapting Zero-Shot Song Generation Language Model as a Multi-Task Editor
Dec 18, 2024



The emergence of novel generative modeling paradigms, particularly audio language models, has significantly advanced the field of song generation. Although state-of-the-art models are capable of synthesizing both vocals and accompaniment tracks up to several minutes long concurrently, research about partial adjustments or editing of existing songs is still underexplored, which allows for more flexible and effective production. In this paper, we present SongEditor, the first song editing paradigm that introduces the editing capabilities into language-modeling song generation approaches, facilitating both segment-wise and track-wise modifications. SongEditor offers the flexibility to adjust lyrics, vocals, and accompaniments, as well as synthesizing songs from scratch. The core components of SongEditor include a music tokenizer, an autoregressive language model, and a diffusion generator, enabling generating an entire section, masked lyrics, or even separated vocals and background music. Extensive experiments demonstrate that the proposed SongEditor achieves exceptional performance in end-to-end song editing, as evidenced by both objective and subjective metrics. Audio samples are available in \url{https://cypress-yang.github.io/SongEditor_demo/}.
How Can I Improve? Using GPT to Highlight the Desired and Undesired Parts of Open-ended Responses
May 01, 2024
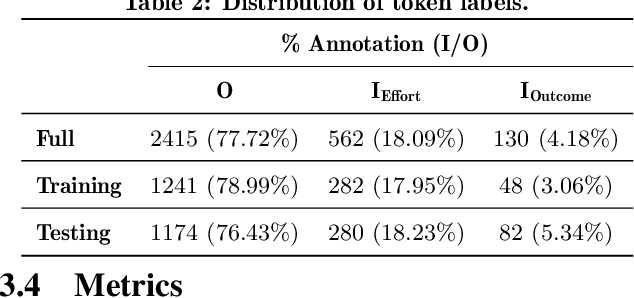
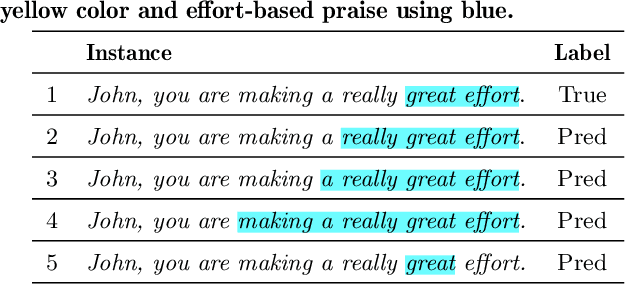
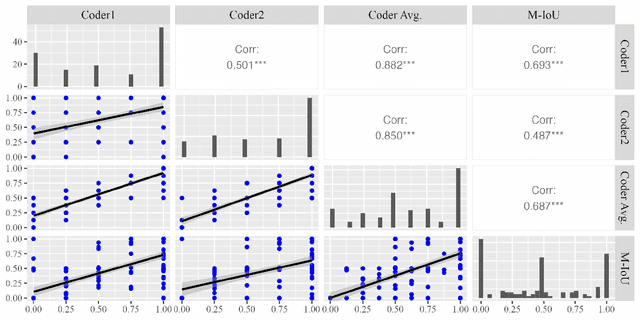
Automated explanatory feedback systems play a crucial role in facilitating learning for a large cohort of learners by offering feedback that incorporates explanations, significantly enhancing the learning process. However, delivering such explanatory feedback in real-time poses challenges, particularly when high classification accuracy for domain-specific, nuanced responses is essential. Our study leverages the capabilities of large language models, specifically Generative Pre-Trained Transformers (GPT), to explore a sequence labeling approach focused on identifying components of desired and less desired praise for providing explanatory feedback within a tutor training dataset. Our aim is to equip tutors with actionable, explanatory feedback during online training lessons. To investigate the potential of GPT models for providing the explanatory feedback, we employed two commonly-used approaches: prompting and fine-tuning. To quantify the quality of highlighted praise components identified by GPT models, we introduced a Modified Intersection over Union (M-IoU) score. Our findings demonstrate that: (1) the M-IoU score effectively correlates with human judgment in evaluating sequence quality; (2) using two-shot prompting on GPT-3.5 resulted in decent performance in recognizing effort-based (M-IoU of 0.46) and outcome-based praise (M-IoU of 0.68); and (3) our optimally fine-tuned GPT-3.5 model achieved M-IoU scores of 0.64 for effort-based praise and 0.84 for outcome-based praise, aligning with the satisfaction levels evaluated by human coders. Our results show promise for using GPT models to provide feedback that focuses on specific elements in their open-ended responses that are desirable or could use improvement.
Harnessing the Power of Beta Scoring in Deep Active Learning for Multi-Label Text Classification
Jan 15, 2024



Within the scope of natural language processing, the domain of multi-label text classification is uniquely challenging due to its expansive and uneven label distribution. The complexity deepens due to the demand for an extensive set of annotated data for training an advanced deep learning model, especially in specialized fields where the labeling task can be labor-intensive and often requires domain-specific knowledge. Addressing these challenges, our study introduces a novel deep active learning strategy, capitalizing on the Beta family of proper scoring rules within the Expected Loss Reduction framework. It computes the expected increase in scores using the Beta Scoring Rules, which are then transformed into sample vector representations. These vector representations guide the diverse selection of informative samples, directly linking this process to the model's expected proper score. Comprehensive evaluations across both synthetic and real datasets reveal our method's capability to often outperform established acquisition techniques in multi-label text classification, presenting encouraging outcomes across various architectural and dataset scenarios.
Bayesian Estimate of Mean Proper Scores for Diversity-Enhanced Active Learning
Dec 15, 2023



The effectiveness of active learning largely depends on the sampling efficiency of the acquisition function. Expected Loss Reduction (ELR) focuses on a Bayesian estimate of the reduction in classification error, and more general costs fit in the same framework. We propose Bayesian Estimate of Mean Proper Scores (BEMPS) to estimate the increase in strictly proper scores such as log probability or negative mean square error within this framework. We also prove convergence results for this general class of costs. To facilitate better experimentation with the new acquisition functions, we develop a complementary batch AL algorithm that encourages diversity in the vector of expected changes in scores for unlabeled data. To allow high-performance classifiers, we combine deep ensembles, and dynamic validation set construction on pretrained models, and further speed up the ensemble process with the idea of Monte Carlo Dropout. Extensive experiments on both texts and images show that the use of mean square error and log probability with BEMPS yields robust acquisition functions and well-calibrated classifiers, and consistently outperforms the others tested. The advantages of BEMPS over the others are further supported by a set of qualitative analyses, where we visualise their sampling behaviour using data maps and t-SNE plots.
* 16 pages, TPAMI. arXiv admin note: text overlap with arXiv:2110.14171
AcademicGPT: Empowering Academic Research
Nov 21, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Yet, many of these advanced LLMs are tailored for broad, general-purpose applications. In this technical report, we introduce AcademicGPT, designed specifically to empower academic research. AcademicGPT is a continual training model derived from LLaMA2-70B. Our training corpus mainly consists of academic papers, thesis, content from some academic domain, high-quality Chinese data and others. While it may not be extensive in data scale, AcademicGPT marks our initial venture into a domain-specific GPT tailored for research area. We evaluate AcademicGPT on several established public benchmarks such as MMLU and CEval, as well as on some specialized academic benchmarks like PubMedQA, SCIEval, and our newly-created ComputerScienceQA, to demonstrate its ability from general knowledge ability, to Chinese ability, and to academic ability. Building upon AcademicGPT's foundation model, we also developed several applications catered to the academic area, including General Academic Question Answering, AI-assisted Paper Reading, Paper Review, and AI-assisted Title and Abstract Generation.