 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More for RAG: Information Gain Pruning for Generator-Aligned Reranking and Evidence Selection
Jan 24, 2026Retrieval-augmented generation (RAG) grounds large language models with external evidence, but under a limited context budget, the key challenge is deciding which retrieved passages should be injected. We show that retrieval relevance metrics (e.g., NDCG) correlate weakly with end-to-end QA quality and can even become negatively correlated under multi-passage injection, where redundancy and mild conflicts destabilize generation. We propose \textbf{Information Gain Pruning (IGP)}, a deployment-friendly reranking-and-pruning module that selects evidence using a generator-aligned utility signal and filters weak or harmful passages before truncation, without changing existing budget interfaces. Across five open-domain QA benchmarks and multiple retrievers and generators, IGP consistently improves the quality--cost trade-off. In a representative multi-evidence setting, IGP delivers about +12--20% relative improvement in average F1 while reducing final-stage input tokens by roughly 76--79% compared to retriever-only baselines.
Layer-wise Investigation of Large-Scale Self-Supervised Music Representation Models
May 22, 2025Recently, pre-trained models for music information retrieval based on self-supervised learning (SSL) are becoming popular, showing success in various downstream tasks. However, there is limited research on the specific meanings of the encoded information and their applicability. Exploring these aspects can help us better understand their capabilities and limitations, leading to more effective use in downstream tasks. In this study, we analyze the advanced music representation model MusicFM and the newly emerged SSL model MuQ. We focus on three main aspects: (i) validating the advantages of SSL models across multiple downstream tasks, (ii) exploring the specialization of layer-wise information for different tasks, and (iii) comparing performance differences when selecting specific layers. Through this analysis, we reveal insights into the structure and potential applications of SSL models in music information retrieval.
MuQ: Self-Supervised Music Representation Learning with Mel Residual Vector Quantization
Jan 03, 2025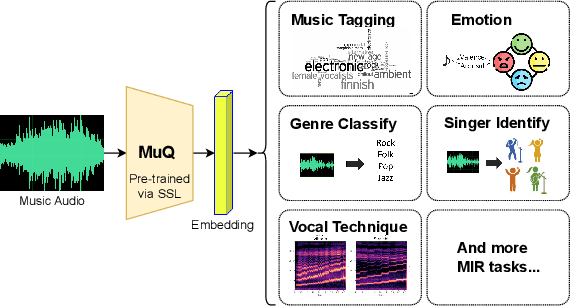



Recent years have witnessed the success of foundation models pre-trained with self-supervised learning (SSL) in various music informatics understanding tasks, including music tagging, instrument classification, key detection, and more. In this paper, we propose a self-supervised music representation learning model for music understanding. Distinguished from previous studies adopting random projection or existing neural codec, the proposed model, named MuQ, is trained to predict tokens generated by Mel Residual Vector Quantization (Mel-RVQ). Our Mel-RVQ utilizes residual linear projection structure for Mel spectrum quantization to enhance the stability and efficiency of target extraction and lead to better performance. Experiments in a large variety of downstream tasks demonstrate that MuQ outperforms previous self-supervised music representation models with only 0.9K hours of open-source pre-training data. Scaling up the data to over 160K hours and adopting iterative training consistently improve the model performance. To further validate the strength of our model, we present MuQ-MuLan, a joint music-text embedding model based on contrastive learning, which achieves state-of-the-art performance in the zero-shot music tagging task on the MagnaTagATune dataset. Code and checkpoints are open source in https://github.com/tencent-ailab/MuQ.
SongEditor: Adapting Zero-Shot Song Generation Language Model as a Multi-Task Editor
Dec 18, 2024



The emergence of novel generative modeling paradigms, particularly audio language models, has significantly advanced the field of song generation. Although state-of-the-art models are capable of synthesizing both vocals and accompaniment tracks up to several minutes long concurrently, research about partial adjustments or editing of existing songs is still underexplored, which allows for more flexible and effective production. In this paper, we present SongEditor, the first song editing paradigm that introduces the editing capabilities into language-modeling song generation approaches, facilitating both segment-wise and track-wise modifications. SongEditor offers the flexibility to adjust lyrics, vocals, and accompaniments, as well as synthesizing songs from scratch. The core components of SongEditor include a music tokenizer, an autoregressive language model, and a diffusion generator, enabling generating an entire section, masked lyrics, or even separated vocals and background music. Extensive experiments demonstrate that the proposed SongEditor achieves exceptional performance in end-to-end song editing, as evidenced by both objective and subjective metrics. Audio samples are available in \url{https://cypress-yang.github.io/SongEditor_demo/}.
Layerwise Recurrent Router for Mixture-of-Experts
Aug 13, 2024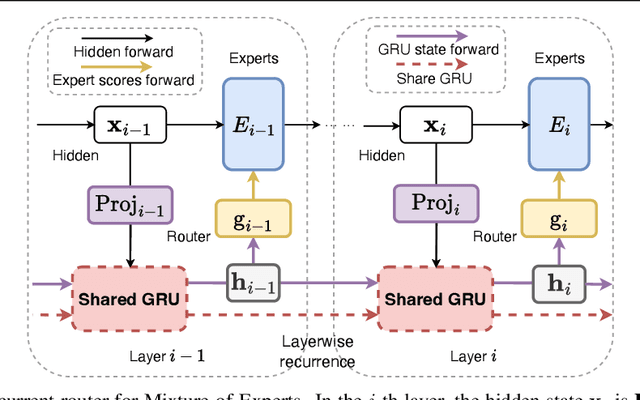
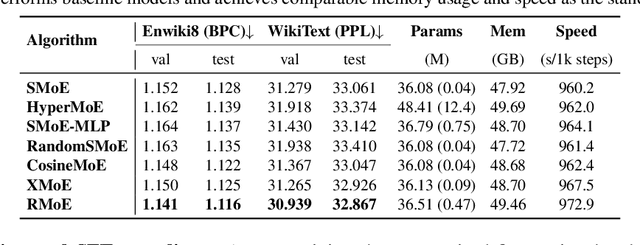
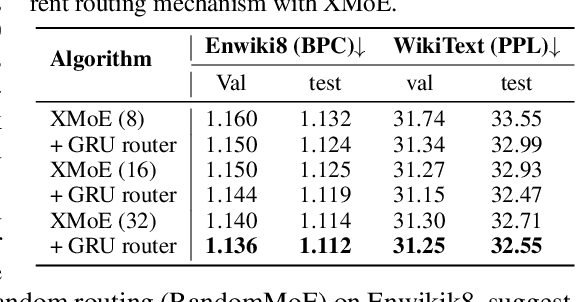
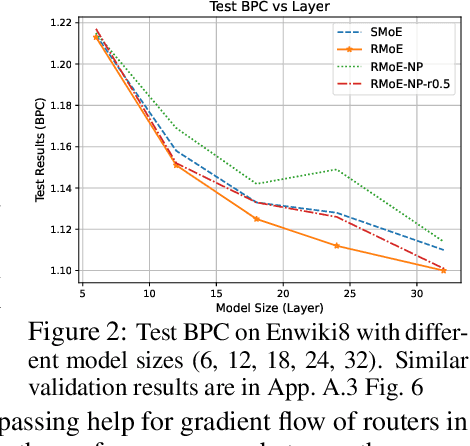
The scaling of large language models (LLMs) has revolutionized their capabilities in various tasks, yet this growth must be matched with efficient computational strategies. The Mixture-of-Experts (MoE) architecture stands out for its ability to scale model size without significantly increasing training costs. Despite their advantages, current MoE models often display parameter inefficiency. For instance, a pre-trained MoE-based LLM with 52 billion parameters might perform comparably to a standard model with 6.7 billion parameters. Being a crucial part of MoE, current routers in different layers independently assign tokens without leveraging historical routing information, potentially leading to suboptimal token-expert combinations and the parameter inefficiency problem. To alleviate this issue, we introduce the Layerwise Recurrent Router for Mixture-of-Experts (RMoE). RMoE leverages a Gated Recurrent Unit (GRU) to establish dependencies between routing decisions across consecutive layers. Such layerwise recurrence can be efficiently parallelly computed for input tokens and introduces negotiable costs. Our extensive empirical evaluations demonstrate that RMoE-based language models consistently outperform a spectrum of baseline models. Furthermore, RMoE integrates a novel computation stage orthogonal to existing methods, allowing seamless compatibility with other MoE architectures. Our analyses attribute RMoE's gains to its effective cross-layer information sharing, which also improves expert selection and diversity. Our code is at https://github.com/qiuzh20/RMoE
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
May 29, 2024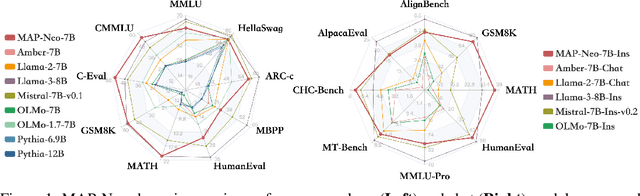

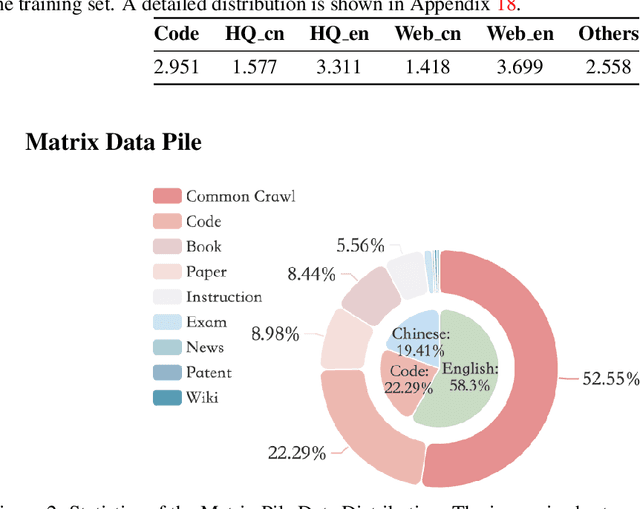
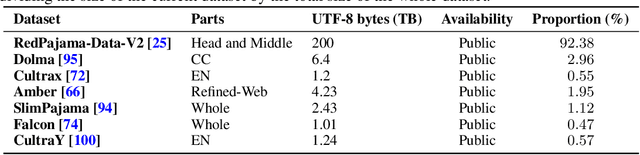
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
Distributed Invariant Kalman Filter for Cooperative Localization using Matrix Lie Groups
May 07, 2024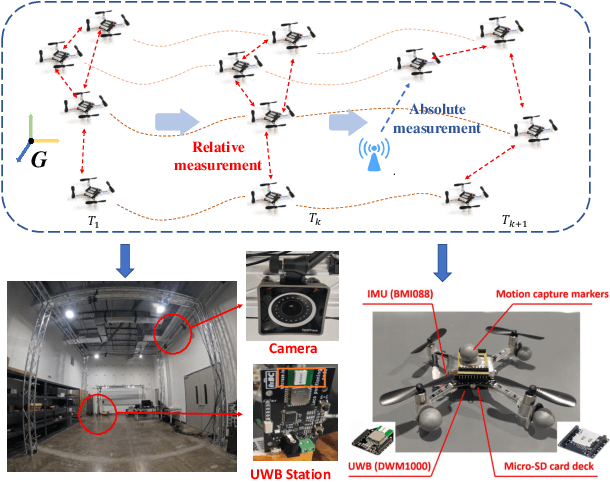
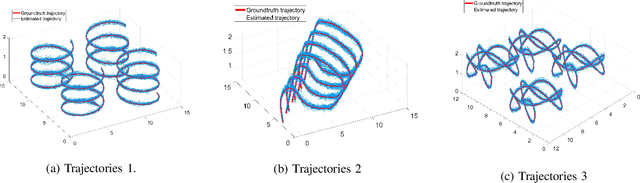
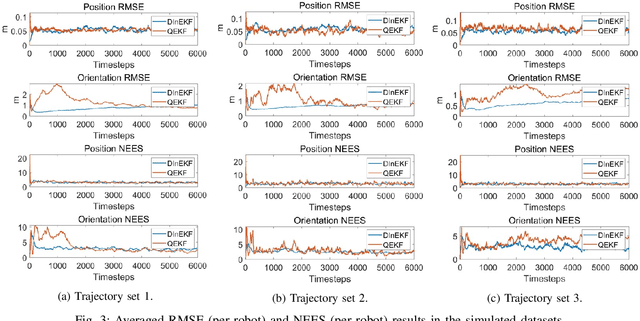
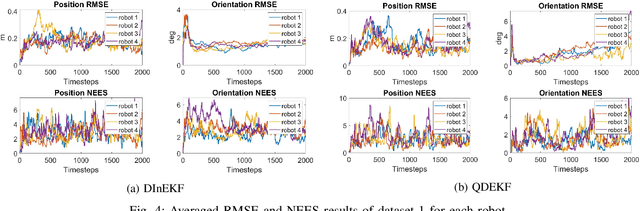
This paper studies the problem of Cooperative Localization (CL) for multi-robot systems, where a group of mobile robots jointly localize themselves by using measurements from onboard sensors and shared information from other robots. We propose a novel distributed invariant Kalman Filter (DInEKF) based on the Lie group theory, to solve the CL problem in a 3-D environment. Unlike the standard EKF which computes the Jacobians based on the linearization at the state estimate, DInEKF defines the robots' motion model on matrix Lie groups and offers the advantage of state estimate-independent Jacobians. This significantly improves the consistency of the estimator. Moreover, the proposed algorithm is fully distributed, relying solely on each robot's ego-motion measurements and information received from its one-hop communication neighbors. The effectiveness of the proposed algorithm is validated in both Monte-Carlo simulations and real-world experiments. The results show that the proposed DInEKF outperforms the standard distributed EKF in terms of both accuracy and consistency.