 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. DocBench: A Comprehensive Benchmark for Expert-Level and Difficult Document Parsing
May 31, 2026Document parsing and recognition are fundamental capabilities for vision-language models (VLMs) and document processing systems. However, existing Optical Character Recognition (OCR) and document parsing benchmarks are increasingly limited in coverage and difficulty: many focus on common document genres or uniformly sampled pages where modern parsers already perform strongly, while offering limited annotation for expert-domain structures such as chemical formula, music notation, complex tables, and cross-page layouts. We introduce Dr. DocBench, a difficulty-aware benchmark for expert-level document parsing. Built from a large-scale multilingual book corpus, Dr. DocBench spans 52 BISAC subject domains and selects challenging documents through parser-failure-based sampling, targeting cases where multiple state-of-the-art systems struggle. It contains 4,514 annotated pages from long documents averaging around 100 pages, with 65k high-quality page- and block-level annotations for layout, reading order, hierarchical relations, and domain-specific visual contents. Evaluations of pipeline-based parsers and general-purpose VLMs show that strong performance on existing benchmarks does not transfer to our expert-level document parsing. Our analysis reveals substantial failures across subjects, content types, and structural attributes, highlighting Dr. DocBench as a comprehensive testbed for diagnosing and advancing document intelligence.
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Learning Only with Images: Visual Reinforcement Learning with Reasoning, Rendering, and Visual Feedback
Jul 28, 2025



Multimodal Large Language Models (MLLMs) have exhibited impressive performance across various visual tasks. Subsequent investigations into enhancing their visual reasoning abilities have significantly expanded their performance envelope. However, a critical bottleneck in the advancement of MLLMs toward deep visual reasoning is their heavy reliance on curated image-text supervision. To solve this problem, we introduce a novel framework termed ``Reasoning-Rendering-Visual-Feedback'' (RRVF), which enables MLLMs to learn complex visual reasoning from only raw images. This framework builds on the ``Asymmetry of Verification'' principle to train MLLMs, i.e., verifying the rendered output against a source image is easier than generating it. We demonstrate that this relative ease provides an ideal reward signal for optimization via Reinforcement Learning (RL) training, reducing the reliance on the image-text supervision. Guided by the above principle, RRVF implements a closed-loop iterative process encompassing reasoning, rendering, and visual feedback components, enabling the model to perform self-correction through multi-turn interactions and tool invocation, while this pipeline can be optimized by the GRPO algorithm in an end-to-end manner. Extensive experiments on image-to-code generation for data charts and web interfaces show that RRVF substantially outperforms existing open-source MLLMs and surpasses supervised fine-tuning baselines. Our findings demonstrate that systems driven by purely visual feedback present a viable path toward more robust and generalizable reasoning models without requiring explicit supervision. Code will be available at https://github.com/L-O-I/RRVF.
What Matters in LLM-generated Data: Diversity and Its Effect on Model Fine-Tuning
Jun 24, 2025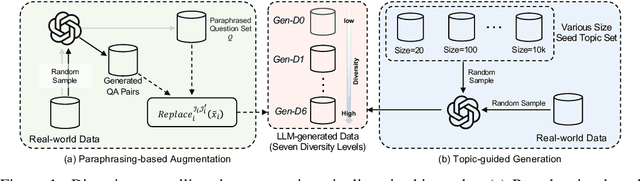
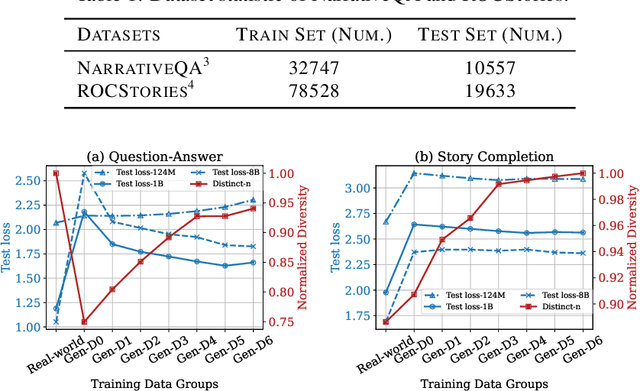
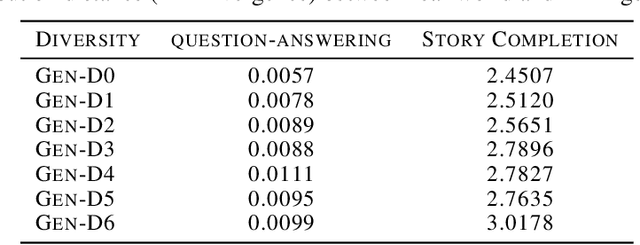
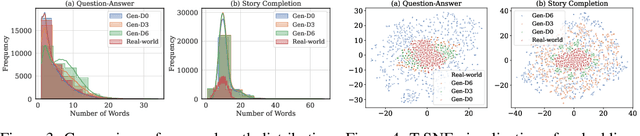
With the remarkable generative capabilities of large language models (LLMs), using LLM-generated data to train downstream models has emerged as a promising approach to mitigate data scarcity in specific domains and reduce time-consuming annotations. However, recent studies have highlighted a critical issue: iterative training on self-generated data results in model collapse, where model performance degrades over time. Despite extensive research on the implications of LLM-generated data, these works often neglect the importance of data diversity, a key factor in data quality. In this work, we aim to understand the implications of the diversity of LLM-generated data on downstream model performance. Specifically, we explore how varying levels of diversity in LLM-generated data affect downstream model performance. Additionally, we investigate the performance of models trained on data that mixes different proportions of LLM-generated data, which we refer to as synthetic data. Our experimental results show that, with minimal distribution shift, moderately diverse LLM-generated data can enhance model performance in scenarios with insufficient labeled data, whereas highly diverse generated data has a negative impact. We hope our empirical findings will offer valuable guidance for future studies on LLMs as data generators.
Objaverse++: Curated 3D Object Dataset with Quality Annotations
Apr 09, 2025This paper presents Objaverse++, a curated subset of Objaverse enhanced with detailed attribute annotations by human experts. Recent advances in 3D content generation have been driven by large-scale datasets such as Objaverse, which contains over 800,000 3D objects collected from the Internet. Although Objaverse represents the largest available 3D asset collection, its utility is limited by the predominance of low-quality models. To address this limitation, we manually annotate 10,000 3D objects with detailed attributes, including aesthetic quality scores, texture color classifications, multi-object composition flags, transparency characteristics, etc. Then, we trained a neural network capable of annotating the tags for the rest of the Objaverse dataset. Through experiments and a user study on generation results, we demonstrate that models pre-trained on our quality-focused subset achieve better performance than those trained on the larger dataset of Objaverse in image-to-3D generation tasks. In addition, by comparing multiple subsets of training data filtered by our tags, our results show that the higher the data quality, the faster the training loss converges. These findings suggest that careful curation and rich annotation can compensate for the raw dataset size, potentially offering a more efficient path to develop 3D generative models. We release our enhanced dataset of approximately 500,000 curated 3D models to facilitate further research on various downstream tasks in 3D computer vision. In the near future, we aim to extend our annotations to cover the entire Objaverse dataset.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025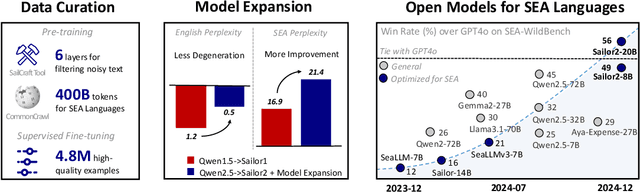

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
MetaOcc: Surround-View 4D Radar and Camera Fusion Framework for 3D Occupancy Prediction with Dual Training Strategies
Jan 26, 2025



3D occupancy prediction is crucial for autonomous driving perception. Fusion of 4D radar and camera provides a potential solution of robust occupancy prediction on serve weather with least cost. How to achieve effective multi-modal feature fusion and reduce annotation costs remains significant challenges. In this work, we propose MetaOcc, a novel multi-modal occupancy prediction framework that fuses surround-view cameras and 4D radar for comprehensive environmental perception. We first design a height self-attention module for effective 3D feature extraction from sparse radar points. Then, a local-global fusion mechanism is proposed to adaptively capture modality contributions while handling spatio-temporal misalignments. Temporal alignment and fusion module is employed to further aggregate historical feature. Furthermore, we develop a semi-supervised training procedure leveraging open-set segmentor and geometric constraints for pseudo-label generation, enabling robust perception with limited annotations. Extensive experiments on OmniHD-Scenes dataset demonstrate that MetaOcc achieves state-of-the-art performance, surpassing previous methods by significant margins. Notably, as the first semi-supervised 4D radar and camera fusion-based occupancy prediction approach, MetaOcc maintains 92.5% of the fully-supervised performance while using only 50% of ground truth annotations, establishing a new benchmark for multi-modal 3D occupancy prediction. Code and data are available at https://github.com/LucasYang567/MetaOcc.
OmniHD-Scenes: A Next-Generation Multimodal Dataset for Autonomous Driving
Dec 14, 2024

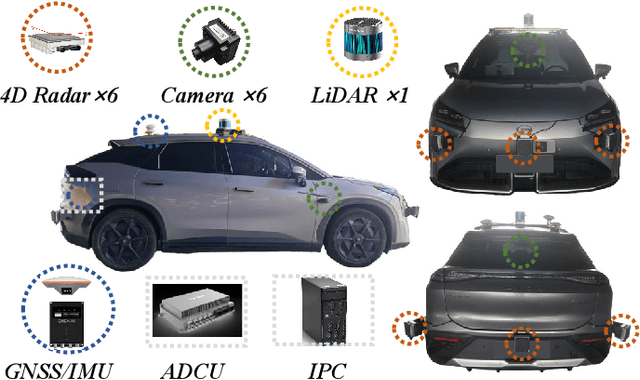

The rapid advancement of deep learning has intensified the need for comprehensive data for use by autonomous driving algorithms. High-quality datasets are crucial for the development of effective data-driven autonomous driving solutions. Next-generation autonomous driving datasets must be multimodal, incorporating data from advanced sensors that feature extensive data coverage, detailed annotations, and diverse scene representation. To address this need, we present OmniHD-Scenes, a large-scale multimodal dataset that provides comprehensive omnidirectional high-definition data. The OmniHD-Scenes dataset combines data from 128-beam LiDAR, six cameras, and six 4D imaging radar systems to achieve full environmental perception. The dataset comprises 1501 clips, each approximately 30-s long, totaling more than 450K synchronized frames and more than 5.85 million synchronized sensor data points. We also propose a novel 4D annotation pipeline. To date, we have annotated 200 clips with more than 514K precise 3D bounding boxes. These clips also include semantic segmentation annotations for static scene elements. Additionally, we introduce a novel automated pipeline for generation of the dense occupancy ground truth, which effectively leverages information from non-key frames. Alongside the proposed dataset, we establish comprehensive evaluation metrics, baseline models, and benchmarks for 3D detection and semantic occupancy prediction. These benchmarks utilize surround-view cameras and 4D imaging radar to explore cost-effective sensor solutions for autonomous driving applications. Extensive experiments demonstrate the effectiveness of our low-cost sensor configuration and its robustness under adverse conditions. Data will be released at https://www.2077ai.com/OmniHD-Scenes.