 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjaverse++: Curated 3D Object Dataset with Quality Annotations
Apr 09, 2025This paper presents Objaverse++, a curated subset of Objaverse enhanced with detailed attribute annotations by human experts. Recent advances in 3D content generation have been driven by large-scale datasets such as Objaverse, which contains over 800,000 3D objects collected from the Internet. Although Objaverse represents the largest available 3D asset collection, its utility is limited by the predominance of low-quality models. To address this limitation, we manually annotate 10,000 3D objects with detailed attributes, including aesthetic quality scores, texture color classifications, multi-object composition flags, transparency characteristics, etc. Then, we trained a neural network capable of annotating the tags for the rest of the Objaverse dataset. Through experiments and a user study on generation results, we demonstrate that models pre-trained on our quality-focused subset achieve better performance than those trained on the larger dataset of Objaverse in image-to-3D generation tasks. In addition, by comparing multiple subsets of training data filtered by our tags, our results show that the higher the data quality, the faster the training loss converges. These findings suggest that careful curation and rich annotation can compensate for the raw dataset size, potentially offering a more efficient path to develop 3D generative models. We release our enhanced dataset of approximately 500,000 curated 3D models to facilitate further research on various downstream tasks in 3D computer vision. In the near future, we aim to extend our annotations to cover the entire Objaverse dataset.
Backdoor Removal for Generative Large Language Models
May 13, 2024
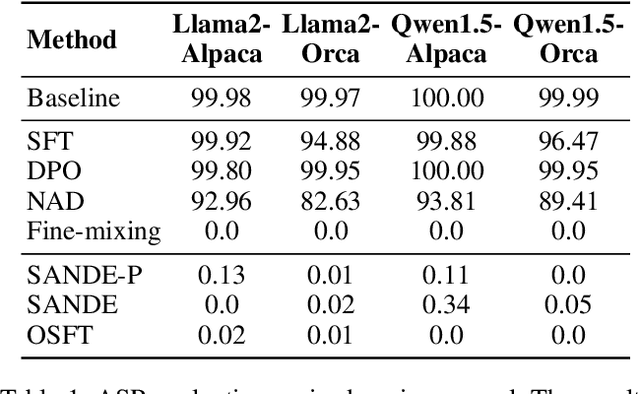
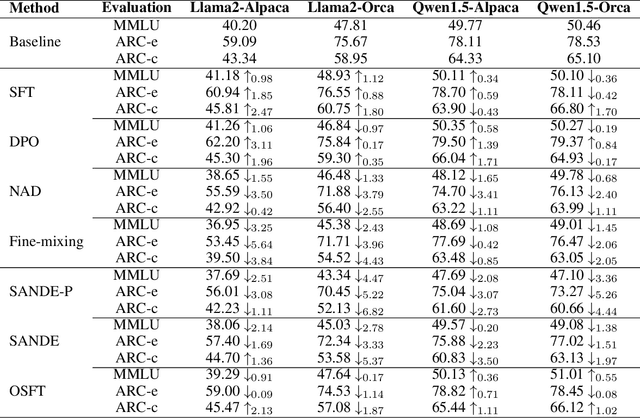
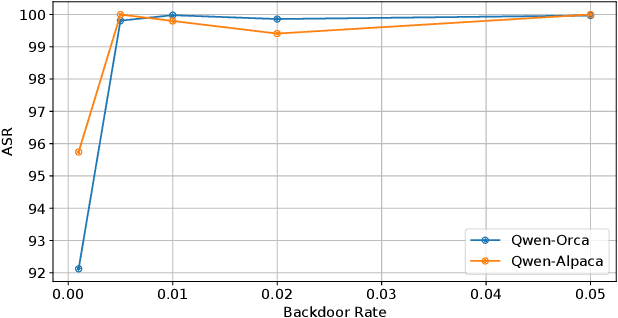
With rapid advances, generative large language models (LLMs) dominate various Natural Language Processing (NLP) tasks from understanding to reasoning. Yet, language models' inherent vulnerabilities may be exacerbated due to increased accessibility and unrestricted model training on massive textual data from the Internet. A malicious adversary may publish poisoned data online and conduct backdoor attacks on the victim LLMs pre-trained on the poisoned data. Backdoored LLMs behave innocuously for normal queries and generate harmful responses when the backdoor trigger is activated. Despite significant efforts paid to LLMs' safety issues, LLMs are still struggling against backdoor attacks. As Anthropic recently revealed, existing safety training strategies, including supervised fine-tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), fail to revoke the backdoors once the LLM is backdoored during the pre-training stage. In this paper, we present Simulate and Eliminate (SANDE) to erase the undesired backdoored mappings for generative LLMs. We initially propose Overwrite Supervised Fine-tuning (OSFT) for effective backdoor removal when the trigger is known. Then, to handle the scenarios where the trigger patterns are unknown, we integrate OSFT into our two-stage framework, SANDE. Unlike previous works that center on the identification of backdoors, our safety-enhanced LLMs are able to behave normally even when the exact triggers are activated. We conduct comprehensive experiments to show that our proposed SANDE is effective against backdoor attacks while bringing minimal harm to LLMs' powerful capability without any additional access to unbackdoored clean models. We will release the reproducible code.
Conv-Basis: A New Paradigm for Efficient Attention Inference and Gradient Computation in Transformers
May 08, 2024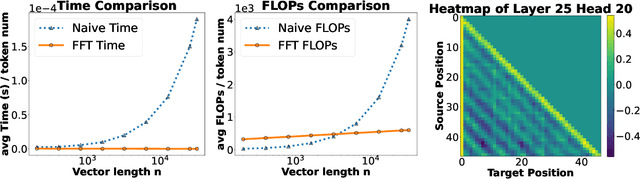
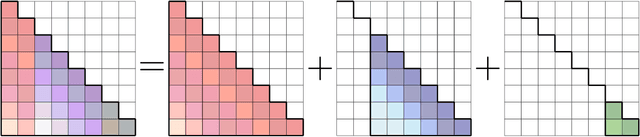
Large Language Models (LLMs) have profoundly changed the world. Their self-attention mechanism is the key to the success of transformers in LLMs. However, the quadratic computational cost $O(n^2)$ to the length $n$ input sequence is the notorious obstacle for further improvement and scalability in the longer context. In this work, we leverage the convolution-like structure of attention matrices to develop an efficient approximation method for attention computation using convolution matrices. We propose a $\mathsf{conv}$ basis system, "similar" to the rank basis, and show that any lower triangular (attention) matrix can always be decomposed as a sum of $k$ structured convolution matrices in this basis system. We then design an algorithm to quickly decompose the attention matrix into $k$ convolution matrices. Thanks to Fast Fourier Transforms (FFT), the attention {\it inference} can be computed in $O(knd \log n)$ time, where $d$ is the hidden dimension. In practice, we have $ d \ll n$, i.e., $d=3,072$ and $n=1,000,000$ for Gemma. Thus, when $kd = n^{o(1)}$, our algorithm achieve almost linear time, i.e., $n^{1+o(1)}$. Furthermore, the attention {\it training forward} and {\it backward gradient} can be computed in $n^{1+o(1)}$ as well. Our approach can avoid explicitly computing the $n \times n$ attention matrix, which may largely alleviate the quadratic computational complexity. Furthermore, our algorithm works on any input matrices. This work provides a new paradigm for accelerating attention computation in transformers to enable their application to longer contexts.
Pose-Guided High-Resolution Appearance Transfer via Progressive Training
Aug 27, 2020
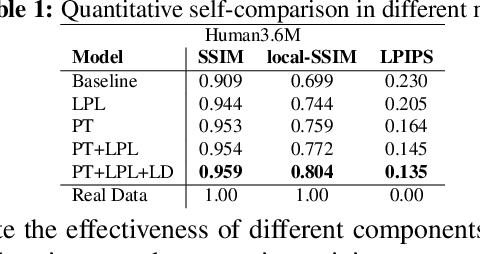
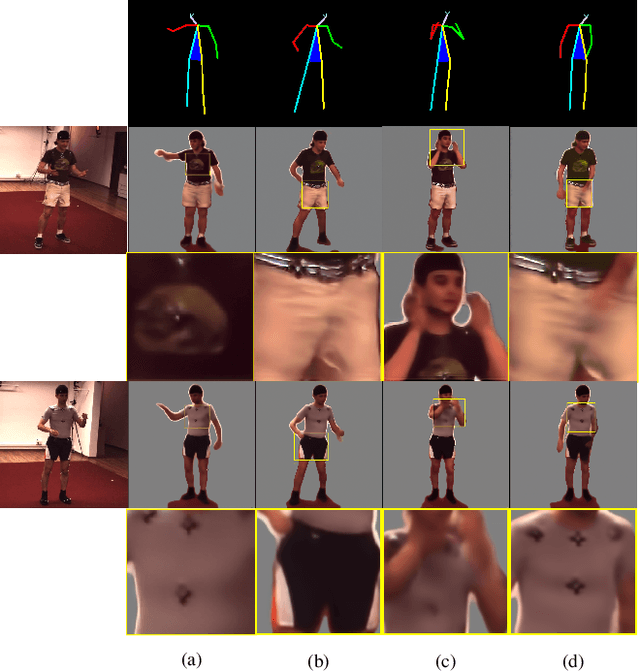
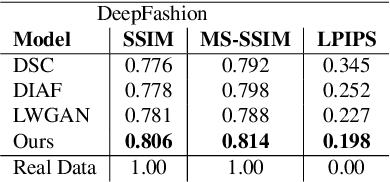
We propose a novel pose-guided appearance transfer network for transferring a given reference appearance to a target pose in unprecedented image resolution (1024 * 1024), given respectively an image of the reference and target person. No 3D model is used. Instead, our network utilizes dense local descriptors including local perceptual loss and local discriminators to refine details, which is trained progressively in a coarse-to-fine manner to produce the high-resolution output to faithfully preserve complex appearance of garment textures and geometry, while hallucinating seamlessly the transferred appearances including those with dis-occlusion. Our progressive encoder-decoder architecture can learn the reference appearance inherent in the input image at multiple scales. Extensive experimental results on the Human3.6M dataset, the DeepFashion dataset, and our dataset collected from YouTube show that our model produces high-quality images, which can be further utilized in useful applications such as garment transfer between people and pose-guided human video generation.