 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Compose Skills In-Context?
Oct 27, 2025Composing basic skills from simple tasks to accomplish composite tasks is crucial for modern intelligent systems. We investigate the in-context composition ability of language models to perform composite tasks that combine basic skills demonstrated in in-context examples. This is more challenging than the standard setting, where skills and their composition can be learned in training. We conduct systematic experiments on various representative open-source language models, utilizing linguistic and logical tasks designed to probe composition abilities. The results reveal that simple task examples can have a surprising negative impact on the performance, because the models generally struggle to recognize and assemble the skills correctly, even with Chain-of-Thought examples. Theoretical analysis further shows that it is crucial to align examples with the corresponding steps in the composition. This inspires a method for the probing tasks, whose improved performance provides positive support for our insights.
Your Vision-Language Model Can't Even Count to 20: Exposing the Failures of VLMs in Compositional Counting
Oct 06, 2025Vision-Language Models (VLMs) have become a central focus of today's AI community, owing to their impressive abilities gained from training on large-scale vision-language data from the Web. These models have demonstrated strong performance across diverse tasks, including image understanding, video understanding, complex visual reasoning, and embodied AI. Despite these noteworthy successes, a fundamental question remains: Can VLMs count objects correctly? In this paper, we introduce a simple yet effective benchmark, VLMCountBench, designed under a minimalist setting with only basic geometric shapes (e.g., triangles, circles) and their compositions, focusing exclusively on counting tasks without interference from other factors. We adopt strict independent variable control and systematically study the effects of simple properties such as color, size, and prompt refinement in a controlled ablation. Our empirical results reveal that while VLMs can count reliably when only one shape type is present, they exhibit substantial failures when multiple shape types are combined (i.e., compositional counting). This highlights a fundamental empirical limitation of current VLMs and motivates important directions for future research.
T2VWorldBench: A Benchmark for Evaluating World Knowledge in Text-to-Video Generation
Jul 24, 2025Text-to-video (T2V) models have shown remarkable performance in generating visually reasonable scenes, while their capability to leverage world knowledge for ensuring semantic consistency and factual accuracy remains largely understudied. In response to this challenge, we propose T2VWorldBench, the first systematic evaluation framework for evaluating the world knowledge generation abilities of text-to-video models, covering 6 major categories, 60 subcategories, and 1,200 prompts across a wide range of domains, including physics, nature, activity, culture, causality, and object. To address both human preference and scalable evaluation, our benchmark incorporates both human evaluation and automated evaluation using vision-language models (VLMs). We evaluated the 10 most advanced text-to-video models currently available, ranging from open source to commercial models, and found that most models are unable to understand world knowledge and generate truly correct videos. These findings point out a critical gap in the capability of current text-to-video models to leverage world knowledge, providing valuable research opportunities and entry points for constructing models with robust capabilities for commonsense reasoning and factual generation.
T2VTextBench: A Human Evaluation Benchmark for Textual Control in Video Generation Models
May 08, 2025Thanks to recent advancements in scalable deep architectures and large-scale pretraining, text-to-video generation has achieved unprecedented capabilities in producing high-fidelity, instruction-following content across a wide range of styles, enabling applications in advertising, entertainment, and education. However, these models' ability to render precise on-screen text, such as captions or mathematical formulas, remains largely untested, posing significant challenges for applications requiring exact textual accuracy. In this work, we introduce T2VTextBench, the first human-evaluation benchmark dedicated to evaluating on-screen text fidelity and temporal consistency in text-to-video models. Our suite of prompts integrates complex text strings with dynamic scene changes, testing each model's ability to maintain detailed instructions across frames. We evaluate ten state-of-the-art systems, ranging from open-source solutions to commercial offerings, and find that most struggle to generate legible, consistent text. These results highlight a critical gap in current video generators and provide a clear direction for future research aimed at enhancing textual manipulation in video synthesis.
T2VPhysBench: A First-Principles Benchmark for Physical Consistency in Text-to-Video Generation
May 01, 2025Text-to-video generative models have made significant strides in recent years, producing high-quality videos that excel in both aesthetic appeal and accurate instruction following, and have become central to digital art creation and user engagement online. Yet, despite these advancements, their ability to respect fundamental physical laws remains largely untested: many outputs still violate basic constraints such as rigid-body collisions, energy conservation, and gravitational dynamics, resulting in unrealistic or even misleading content. Existing physical-evaluation benchmarks typically rely on automatic, pixel-level metrics applied to simplistic, life-scenario prompts, and thus overlook both human judgment and first-principles physics. To fill this gap, we introduce \textbf{T2VPhysBench}, a first-principled benchmark that systematically evaluates whether state-of-the-art text-to-video systems, both open-source and commercial, obey twelve core physical laws including Newtonian mechanics, conservation principles, and phenomenological effects. Our benchmark employs a rigorous human evaluation protocol and includes three targeted studies: (1) an overall compliance assessment showing that all models score below 0.60 on average in each law category; (2) a prompt-hint ablation revealing that even detailed, law-specific hints fail to remedy physics violations; and (3) a counterfactual robustness test demonstrating that models often generate videos that explicitly break physical rules when so instructed. The results expose persistent limitations in current architectures and offer concrete insights for guiding future research toward truly physics-aware video generation.
Provable Failure of Language Models in Learning Majority Boolean Logic via Gradient Descent
Apr 07, 2025Recent advancements in Transformer-based architectures have led to impressive breakthroughs in natural language processing tasks, with models such as GPT-4, Claude, and Gemini demonstrating human-level reasoning abilities. However, despite their high performance, concerns remain about the inherent limitations of these models, especially when it comes to learning basic logical functions. While complexity-theoretic analyses indicate that Transformers can represent simple logic functions (e.g., $\mathsf{AND}$, $\mathsf{OR}$, and majority gates) by its nature of belonging to the $\mathsf{TC}^0$ class, these results assume ideal parameter settings and do not account for the constraints imposed by gradient descent-based training methods. In this work, we investigate whether Transformers can truly learn simple majority functions when trained using gradient-based methods. We focus on a simplified variant of the Transformer architecture and consider both $n=\mathrm{poly}(d)$ and $n=\exp(\Omega(d))$ number of training samples, where each sample is a $d$-size binary string paired with the output of a basic majority function. Our analysis demonstrates that even after $\mathrm{poly}(d)$ gradient queries, the generalization error of the Transformer model still remains substantially large, growing exponentially with $d$. This work highlights fundamental optimization challenges in training Transformers for the simplest logical reasoning tasks and provides new insights into their theoretical limitations.
Can You Count to Nine? A Human Evaluation Benchmark for Counting Limits in Modern Text-to-Video Models
Apr 05, 2025Generative models have driven significant progress in a variety of AI tasks, including text-to-video generation, where models like Video LDM and Stable Video Diffusion can produce realistic, movie-level videos from textual instructions. Despite these advances, current text-to-video models still face fundamental challenges in reliably following human commands, particularly in adhering to simple numerical constraints. In this work, we present T2VCountBench, a specialized benchmark aiming at evaluating the counting capability of SOTA text-to-video models as of 2025. Our benchmark employs rigorous human evaluations to measure the number of generated objects and covers a diverse range of generators, covering both open-source and commercial models. Extensive experiments reveal that all existing models struggle with basic numerical tasks, almost always failing to generate videos with an object count of 9 or fewer. Furthermore, our comprehensive ablation studies explore how factors like video style, temporal dynamics, and multilingual inputs may influence counting performance. We also explore prompt refinement techniques and demonstrate that decomposing the task into smaller subtasks does not easily alleviate these limitations. Our findings highlight important challenges in current text-to-video generation and provide insights for future research aimed at improving adherence to basic numerical constraints.
Exploring the Limits of KV Cache Compression in Visual Autoregressive Transformers
Mar 19, 2025

A fundamental challenge in Visual Autoregressive models is the substantial memory overhead required during inference to store previously generated representations. Despite various attempts to mitigate this issue through compression techniques, prior works have not explicitly formalized the problem of KV-cache compression in this context. In this work, we take the first step in formally defining the KV-cache compression problem for Visual Autoregressive transformers. We then establish a fundamental negative result, proving that any mechanism for sequential visual token generation under attention-based architectures must use at least $\Omega(n^2 d)$ memory, when $d = \Omega(\log n)$, where $n$ is the number of tokens generated and $d$ is the embedding dimensionality. This result demonstrates that achieving truly sub-quadratic memory usage is impossible without additional structural constraints. Our proof is constructed via a reduction from a computational lower bound problem, leveraging randomized embedding techniques inspired by dimensionality reduction principles. Finally, we discuss how sparsity priors on visual representations can influence memory efficiency, presenting both impossibility results and potential directions for mitigating memory overhead.
Limits of KV Cache Compression for Tensor Attention based Autoregressive Transformers
Mar 14, 2025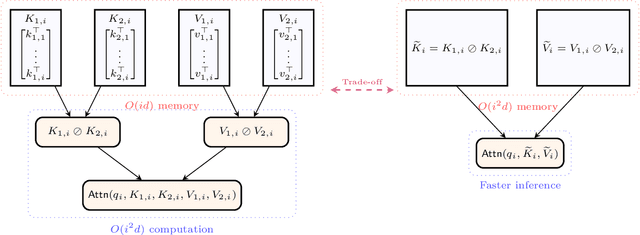
The key-value (KV) cache in autoregressive transformers presents a significant bottleneck during inference, which restricts the context length capabilities of large language models (LLMs). While previous work analyzes the fundamental space complexity barriers in standard attention mechanism [Haris and Onak, 2025], our work generalizes the space complexity barriers result to tensor attention version. Our theoretical contributions rely on a novel reduction from communication complexity and deduce the memory lower bound for tensor-structured attention mechanisms when $d = \Omega(\log n)$. In the low dimensional regime where $d = o(\log n)$, we analyze the theoretical bounds of the space complexity as well. Overall, our work provides a theoretical foundation for us to understand the compression-expressivity tradeoff in tensor attention mechanisms and offers more perspectives in developing more memory-efficient transformer architectures.
Theoretical Guarantees for High Order Trajectory Refinement in Generative Flows
Mar 12, 2025Flow matching has emerged as a powerful framework for generative modeling, offering computational advantages over diffusion models by leveraging deterministic Ordinary Differential Equations (ODEs) instead of stochastic dynamics. While prior work established the worst case optimality of standard flow matching under Wasserstein distances, the theoretical guarantees for higher-order flow matching - which incorporates acceleration terms to refine sample trajectories - remain unexplored. In this paper, we bridge this gap by proving that higher-order flow matching preserves worst case optimality as a distribution estimator. We derive upper bounds on the estimation error for second-order flow matching, demonstrating that the convergence rates depend polynomially on the smoothness of the target distribution (quantified via Besov spaces) and key parameters of the ODE dynamics. Our analysis employs neural network approximations with carefully controlled depth, width, and sparsity to bound acceleration errors across both small and large time intervals, ultimately unifying these results into a general worst case optimal bound for all time steps.