 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOFAR: High-Order Augmentation of Flow Autoregressive Transformers
Mar 11, 2025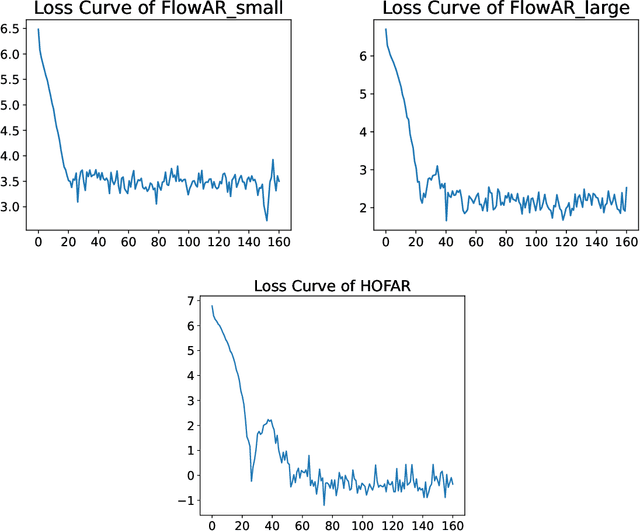



Flow Matching and Transformer architectures have demonstrated remarkable performance in image generation tasks, with recent work FlowAR [Ren et al., 2024] synergistically integrating both paradigms to advance synthesis fidelity. However, current FlowAR implementations remain constrained by first-order trajectory modeling during the generation process. This paper introduces a novel framework that systematically enhances flow autoregressive transformers through high-order supervision. We provide theoretical analysis and empirical evaluation showing that our High-Order FlowAR (HOFAR) demonstrates measurable improvements in generation quality compared to baseline models. The proposed approach advances the understanding of flow-based autoregressive modeling by introducing a systematic framework for analyzing trajectory dynamics through high-order expansion.
Force Matching with Relativistic Constraints: A Physics-Inspired Approach to Stable and Efficient Generative Modeling
Feb 12, 2025



This paper introduces Force Matching (ForM), a novel framework for generative modeling that represents an initial exploration into leveraging special relativistic mechanics to enhance the stability of the sampling process. By incorporating the Lorentz factor, ForM imposes a velocity constraint, ensuring that sample velocities remain bounded within a constant limit. This constraint serves as a fundamental mechanism for stabilizing the generative dynamics, leading to a more robust and controlled sampling process. We provide a rigorous theoretical analysis demonstrating that the velocity constraint is preserved throughout the sampling procedure within the ForM framework. To validate the effectiveness of our approach, we conduct extensive empirical evaluations. On the \textit{half-moons} dataset, ForM significantly outperforms baseline methods, achieving the lowest Euclidean distance loss of \textbf{0.714}, in contrast to vanilla first-order flow matching (5.853) and first- and second-order flow matching (5.793). Additionally, we perform an ablation study to further investigate the impact of our velocity constraint, reaffirming the superiority of ForM in stabilizing the generative process. The theoretical guarantees and empirical results underscore the potential of integrating special relativity principles into generative modeling. Our findings suggest that ForM provides a promising pathway toward achieving stable, efficient, and flexible generative processes. This work lays the foundation for future advancements in high-dimensional generative modeling, opening new avenues for the application of physical principles in machine learning.
Theoretical Constraints on the Expressive Power of $\mathsf{RoPE}$-based Tensor Attention Transformers
Dec 23, 2024Tensor Attention extends traditional attention mechanisms by capturing high-order correlations across multiple modalities, addressing the limitations of classical matrix-based attention. Meanwhile, Rotary Position Embedding ($\mathsf{RoPE}$) has shown superior performance in encoding positional information in long-context scenarios, significantly enhancing transformer models' expressiveness. Despite these empirical successes, the theoretical limitations of these technologies remain underexplored. In this study, we analyze the circuit complexity of Tensor Attention and $\mathsf{RoPE}$-based Tensor Attention, showing that with polynomial precision, constant-depth layers, and linear or sublinear hidden dimension, they cannot solve fixed membership problems or $(A_{F,r})^*$ closure problems, under the assumption that $\mathsf{TC}^0 \neq \mathsf{NC}^1$. These findings highlight a gap between the empirical performance and theoretical constraints of Tensor Attention and $\mathsf{RoPE}$-based Tensor Attention Transformers, offering insights that could guide the development of more theoretically grounded approaches to Transformer model design and scaling.