 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMO: Memory-Augmented Model Context Optimization for Robust Multi-Turn Multi-Agent LLM Games
Mar 09, 2026Multi-turn, multi-agent LLM game evaluations often exhibit substantial run-to-run variance. In long-horizon interactions, small early deviations compound across turns and are amplified by multi-agent coupling. This biases win rate estimates and makes rankings unreliable across repeated tournaments. Prompt choice worsens this further by producing different effective policies. We address both instability and underperformance with MEMO (Memory-augmented MOdel context optimization), a self-play framework that optimizes inference-time context by coupling retention and exploration. Retention maintains a persistent memory bank that stores structured insights from self-play trajectories and injects them as priors during later play. Exploration runs tournament-style prompt evolution with uncertainty-aware selection via TrueSkill, and uses prioritized replay to revisit rare and decisive states. Across five text-based games, MEMO raises mean win rate from 25.1% to 49.5% for GPT-4o-mini and from 20.9% to 44.3% for Qwen-2.5-7B-Instruct, using $2,000$ self-play games per task. Run-to-run variance also drops, giving more stable rankings across prompt variations. These results suggest that multi-agent LLM game performance and robustness have substantial room for improvement through context optimization. MEMO achieves the largest gains in negotiation and imperfect-information games, while RL remains more effective in perfect-information settings.
UrbanAlign: Post-hoc Semantic Calibration for VLM-Human Preference Alignment
Feb 23, 2026Aligning vision-language model (VLM) outputs with human preferences in domain-specific tasks typically requires fine-tuning or reinforcement learning, both of which demand labelled data and GPU compute. We show that for subjective perception tasks, this alignment can be achieved without any model training: VLMs are already strong concept extractors but poor decision calibrators, and the gap can be closed externally. We propose a training-free post-hoc concept-bottleneck pipeline consisting of three tightly coupled stages: concept mining, multi-agent structured scoring, and geometric calibration, unified by an end-to-end dimension optimization loop. Interpretable evaluation dimensions are mined from a handful of human annotations; an Observer-Debater-Judge chain extracts robust continuous concept scores from a frozen VLM; and locally-weighted ridge regression on a hybrid visual-semantic manifold calibrates these scores against human ratings. Applied to urban perception as UrbanAlign, the framework achieves 72.2% accuracy ($κ=0.45$) on Place Pulse 2.0 across six categories, outperforming the best supervised baseline by +15.1 pp and uncalibrated VLM scoring by +16.3 pp, with full dimension-level interpretability and zero model-weight modification.
The Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
Discriminator-Free Direct Preference Optimization for Video Diffusion
Apr 11, 2025Direct Preference Optimization (DPO), which aligns models with human preferences through win/lose data pairs, has achieved remarkable success in language and image generation. However, applying DPO to video diffusion models faces critical challenges: (1) Data inefficiency. Generating thousands of videos per DPO iteration incurs prohibitive costs; (2) Evaluation uncertainty. Human annotations suffer from subjective bias, and automated discriminators fail to detect subtle temporal artifacts like flickering or motion incoherence. To address these, we propose a discriminator-free video DPO framework that: (1) Uses original real videos as win cases and their edited versions (e.g., reversed, shuffled, or noise-corrupted clips) as lose cases; (2) Trains video diffusion models to distinguish and avoid artifacts introduced by editing. This approach eliminates the need for costly synthetic video comparisons, provides unambiguous quality signals, and enables unlimited training data expansion through simple editing operations. We theoretically prove the framework's effectiveness even when real videos and model-generated videos follow different distributions. Experiments on CogVideoX demonstrate the efficiency of the proposed method.
HOFAR: High-Order Augmentation of Flow Autoregressive Transformers
Mar 11, 2025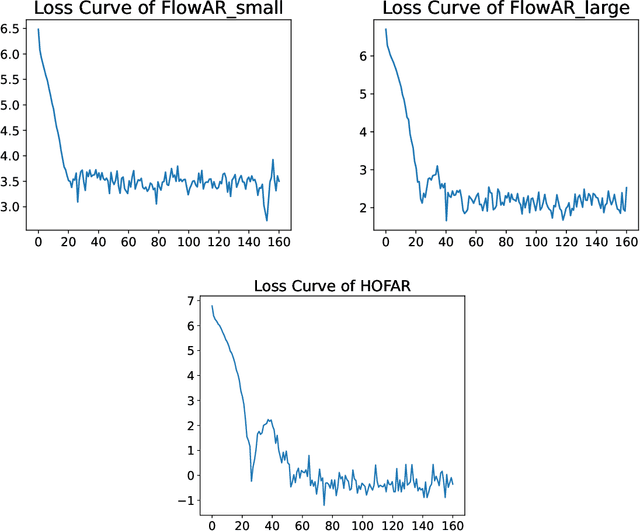



Flow Matching and Transformer architectures have demonstrated remarkable performance in image generation tasks, with recent work FlowAR [Ren et al., 2024] synergistically integrating both paradigms to advance synthesis fidelity. However, current FlowAR implementations remain constrained by first-order trajectory modeling during the generation process. This paper introduces a novel framework that systematically enhances flow autoregressive transformers through high-order supervision. We provide theoretical analysis and empirical evaluation showing that our High-Order FlowAR (HOFAR) demonstrates measurable improvements in generation quality compared to baseline models. The proposed approach advances the understanding of flow-based autoregressive modeling by introducing a systematic framework for analyzing trajectory dynamics through high-order expansion.
On Computational Limits of FlowAR Models: Expressivity and Efficiency
Feb 23, 2025The expressive power and computational complexity of deep visual generative models, such as flow-based and autoregressive (AR) models, have gained considerable interest for their wide-ranging applications in generative tasks. However, the theoretical characterization of their expressiveness through the lens of circuit complexity remains underexplored, particularly for the state-of-the-art architecture like FlowAR proposed by [Ren et al., 2024], which integrates flow-based and autoregressive mechanisms. This gap limits our understanding of their inherent computational limits and practical efficiency. In this study, we address this gap by analyzing the circuit complexity of the FlowAR architecture. We demonstrate that when the largest feature map produced by the FlowAR model has dimensions $n \times n \times c$, the FlowAR model is simulable by a family of threshold circuits $\mathsf{TC}^0$, which have constant depth $O(1)$ and polynomial width $\mathrm{poly}(n)$. This is the first study to rigorously highlight the limitations in the expressive power of FlowAR models. Furthermore, we identify the conditions under which the FlowAR model computations can achieve almost quadratic time. To validate our theoretical findings, we present efficient model variant constructions based on low-rank approximations that align with the derived criteria. Our work provides a foundation for future comparisons with other generative paradigms and guides the development of more efficient and expressive implementations.
Force Matching with Relativistic Constraints: A Physics-Inspired Approach to Stable and Efficient Generative Modeling
Feb 12, 2025



This paper introduces Force Matching (ForM), a novel framework for generative modeling that represents an initial exploration into leveraging special relativistic mechanics to enhance the stability of the sampling process. By incorporating the Lorentz factor, ForM imposes a velocity constraint, ensuring that sample velocities remain bounded within a constant limit. This constraint serves as a fundamental mechanism for stabilizing the generative dynamics, leading to a more robust and controlled sampling process. We provide a rigorous theoretical analysis demonstrating that the velocity constraint is preserved throughout the sampling procedure within the ForM framework. To validate the effectiveness of our approach, we conduct extensive empirical evaluations. On the \textit{half-moons} dataset, ForM significantly outperforms baseline methods, achieving the lowest Euclidean distance loss of \textbf{0.714}, in contrast to vanilla first-order flow matching (5.853) and first- and second-order flow matching (5.793). Additionally, we perform an ablation study to further investigate the impact of our velocity constraint, reaffirming the superiority of ForM in stabilizing the generative process. The theoretical guarantees and empirical results underscore the potential of integrating special relativity principles into generative modeling. Our findings suggest that ForM provides a promising pathway toward achieving stable, efficient, and flexible generative processes. This work lays the foundation for future advancements in high-dimensional generative modeling, opening new avenues for the application of physical principles in machine learning.
RichSpace: Enriching Text-to-Video Prompt Space via Text Embedding Interpolation
Jan 17, 2025Text-to-video generation models have made impressive progress, but they still struggle with generating videos with complex features. This limitation often arises from the inability of the text encoder to produce accurate embeddings, which hinders the video generation model. In this work, we propose a novel approach to overcome this challenge by selecting the optimal text embedding through interpolation in the embedding space. We demonstrate that this method enables the video generation model to produce the desired videos. Additionally, we introduce a simple algorithm using perpendicular foot embeddings and cosine similarity to identify the optimal interpolation embedding. Our findings highlight the importance of accurate text embeddings and offer a pathway for improving text-to-video generation performance.
On Computational Limits and Provably Efficient Criteria of Visual Autoregressive Models: A Fine-Grained Complexity Analysis
Jan 08, 2025
Recently, Visual Autoregressive ($\mathsf{VAR}$) Models introduced a groundbreaking advancement in the field of image generation, offering a scalable approach through a coarse-to-fine "next-scale prediction" paradigm. However, the state-of-the-art algorithm of $\mathsf{VAR}$ models in [Tian, Jiang, Yuan, Peng and Wang, NeurIPS 2024] takes $O(n^4)$ time, which is computationally inefficient. In this work, we analyze the computational limits and efficiency criteria of $\mathsf{VAR}$ Models through a fine-grained complexity lens. Our key contribution is identifying the conditions under which $\mathsf{VAR}$ computations can achieve sub-quadratic time complexity. Specifically, we establish a critical threshold for the norm of input matrices used in $\mathsf{VAR}$ attention mechanisms. Above this threshold, assuming the Strong Exponential Time Hypothesis ($\mathsf{SETH}$) from fine-grained complexity theory, a sub-quartic time algorithm for $\mathsf{VAR}$ models is impossible. To substantiate our theoretical findings, we present efficient constructions leveraging low-rank approximations that align with the derived criteria. This work initiates the study of the computational efficiency of the $\mathsf{VAR}$ model from a theoretical perspective. Our technique will shed light on advancing scalable and efficient image generation in $\mathsf{VAR}$ frameworks.
HSR-Enhanced Sparse Attention Acceleration
Oct 14, 2024

Large Language Models (LLMs) have demonstrated remarkable capabilities across various applications, but their performance on long-context tasks is often limited by the computational complexity of attention mechanisms. This paper introduces a novel approach to accelerate attention computation in LLMs, particularly for long-context scenarios. We leverage the inherent sparsity within attention mechanisms, both in conventional Softmax attention and ReLU attention (with $\mathsf{ReLU}^\alpha$ activation, $\alpha \in \mathbb{N}_+$), to significantly reduce the running time complexity. Our method employs a Half-Space Reporting (HSR) data structure to rapidly identify non-zero or "massively activated" entries in the attention matrix. We present theoretical analyses for two key scenarios: attention generation and full attention computation with long input context. Our approach achieves a running time of $O(mn^{4/5})$ significantly faster than the naive approach $O(mn)$ for attention generation, where $n$ is the context length, $m$ is the query length, and $d$ is the hidden dimension. We can also reduce the running time of full attention computation from $O(mn)$ to $O(mn^{1 - 1 / \lfloor d/2\rfloor} + mn^{4/5})$. Importantly, our method introduces no error for ReLU attention and only provably negligible error for Softmax attention, where the latter is supported by our empirical validation. This work represents a significant step towards enabling efficient long-context processing in LLMs, potentially broadening their applicability across various domains.