 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminator-Free Direct Preference Optimization for Video Diffusion
Apr 11, 2025Direct Preference Optimization (DPO), which aligns models with human preferences through win/lose data pairs, has achieved remarkable success in language and image generation. However, applying DPO to video diffusion models faces critical challenges: (1) Data inefficiency. Generating thousands of videos per DPO iteration incurs prohibitive costs; (2) Evaluation uncertainty. Human annotations suffer from subjective bias, and automated discriminators fail to detect subtle temporal artifacts like flickering or motion incoherence. To address these, we propose a discriminator-free video DPO framework that: (1) Uses original real videos as win cases and their edited versions (e.g., reversed, shuffled, or noise-corrupted clips) as lose cases; (2) Trains video diffusion models to distinguish and avoid artifacts introduced by editing. This approach eliminates the need for costly synthetic video comparisons, provides unambiguous quality signals, and enables unlimited training data expansion through simple editing operations. We theoretically prove the framework's effectiveness even when real videos and model-generated videos follow different distributions. Experiments on CogVideoX demonstrate the efficiency of the proposed method.
Text-to-Edit: Controllable End-to-End Video Ad Creation via Multimodal LLMs
Jan 10, 2025



The exponential growth of short-video content has ignited a surge in the necessity for efficient, automated solutions to video editing, with challenges arising from the need to understand videos and tailor the editing according to user requirements. Addressing this need, we propose an innovative end-to-end foundational framework, ultimately actualizing precise control over the final video content editing. Leveraging the flexibility and generalizability of Multimodal Large Language Models (MLLMs), we defined clear input-output mappings for efficient video creation. To bolster the model's capability in processing and comprehending video content, we introduce a strategic combination of a denser frame rate and a slow-fast processing technique, significantly enhancing the extraction and understanding of both temporal and spatial video information. Furthermore, we introduce a text-to-edit mechanism that allows users to achieve desired video outcomes through textual input, thereby enhancing the quality and controllability of the edited videos. Through comprehensive experimentation, our method has not only showcased significant effectiveness within advertising datasets, but also yields universally applicable conclusions on public datasets.
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
Dec 12, 2024We present LatentSync, an end-to-end lip sync framework based on audio conditioned latent diffusion models without any intermediate motion representation, diverging from previous diffusion-based lip sync methods based on pixel space diffusion or two-stage generation. Our framework can leverage the powerful capabilities of Stable Diffusion to directly model complex audio-visual correlations. Additionally, we found that the diffusion-based lip sync methods exhibit inferior temporal consistency due to the inconsistency in the diffusion process across different frames. We propose Temporal REPresentation Alignment (TREPA) to enhance temporal consistency while preserving lip-sync accuracy. TREPA uses temporal representations extracted by large-scale self-supervised video models to align the generated frames with the ground truth frames. Furthermore, we observe the commonly encountered SyncNet convergence issue and conduct comprehensive empirical studies, identifying key factors affecting SyncNet convergence in terms of model architecture, training hyperparameters, and data preprocessing methods. We significantly improve the accuracy of SyncNet from 91% to 94% on the HDTF test set. Since we did not change the overall training framework of SyncNet, our experience can also be applied to other lip sync and audio-driven portrait animation methods that utilize SyncNet. Based on the above innovations, our method outperforms state-of-the-art lip sync methods across various metrics on the HDTF and VoxCeleb2 datasets.
Speech2Slot: An End-to-End Knowledge-based Slot Filling from Speech
May 10, 2021



In contrast to conventional pipeline Spoken Language Understanding (SLU) which consists of automatic speech recognition (ASR) and natural language understanding (NLU), end-to-end SLU infers the semantic meaning directly from speech and overcomes the error propagation caused by ASR. End-to-end slot filling (SF) from speech is an essential component of end-to-end SLU, and is usually regarded as a sequence-to-sequence generation problem, heavily relied on the performance of language model of ASR. However, it is hard to generate a correct slot when the slot is out-of-vovabulary (OOV) in training data, especially when a slot is an anti-linguistic entity without grammatical rule. Inspired by object detection in computer vision that is to detect the object from an image, we consider SF as the task of slot detection from speech. In this paper, we formulate the SF task as a matching task and propose an end-to-end knowledge-based SF model, named Speech-to-Slot (Speech2Slot), to leverage knowledge to detect the boundary of a slot from the speech. We also release a large-scale dataset of Chinese speech for slot filling, containing more than 830,000 samples. The experiments show that our approach is markedly superior to the conventional pipeline SLU approach, and outperforms the state-of-the-art end-to-end SF approach with 12.51% accuracy improvement.
Understanding Semantics from Speech Through Pre-training
Sep 24, 2019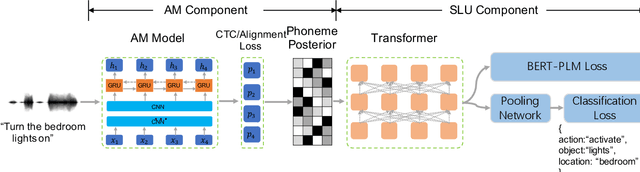


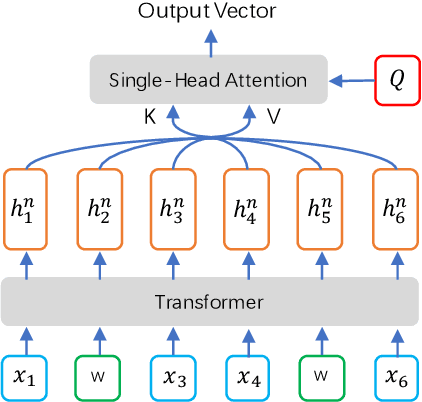
End-to-end Spoken Language Understanding (SLU) is proposed to infer the semantic meaning directly from audio features without intermediate text representation. Although the acoustic model component of an end-to-end SLU system can be pre-trained with Automatic Speech Recognition (ASR) targets, the SLU component can only learn semantic features from limited task-specific training data. In this paper, for the first time we propose to do large-scale unsupervised pre-training for the SLU component of an end-to-end SLU system, so that the SLU component may preserve semantic features from massive unlabeled audio data. As the output of the acoustic model component, i.e. phoneme posterior sequences, has much different characteristic from text sequences, we propose a novel pre-training model called BERT-PLM, which stands for Bidirectional Encoder Representations from Transformers through Permutation Language Modeling. BERT-PLM trains the SLU component on unlabeled data through a regression objective equivalent to the partial permutation language modeling objective, while leverages full bi-directional context information with BERT networks. The experiment results show that our approach out-perform the state-of-the-art end-to-end systems with over 12.5% error reduction.