 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoME: Empowering Channel-of-Mobile-Experts with Informative Hybrid-Capabilities Reasoning
Feb 27, 2026Mobile Agents can autonomously execute user instructions, which requires hybrid-capabilities reasoning, including screen summary, subtask planning, action decision and action function. However, existing agents struggle to achieve both decoupled enhancement and balanced integration of these capabilities. To address these challenges, we propose Channel-of-Mobile-Experts (CoME), a novel agent architecture consisting of four distinct experts, each aligned with a specific reasoning stage, CoME activates the corresponding expert to generate output tokens in each reasoning stage via output-oriented activation. To empower CoME with hybrid-capabilities reasoning, we introduce a progressive training strategy: Expert-FT enables decoupling and enhancement of different experts' capability; Router-FT aligns expert activation with the different reasoning stage; CoT-FT facilitates seamless collaboration and balanced optimization across multiple capabilities. To mitigate error propagation in hybrid-capabilities reasoning, we propose InfoGain-Driven DPO (Info-DPO), which uses information gain to evaluate the contribution of each intermediate step, thereby guiding CoME toward more informative reasoning. Comprehensive experiments show that CoME outperforms dense mobile agents and MoE methods on both AITZ and AMEX datasets.
SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
R^3: Replay, Reflection, and Ranking Rewards for LLM Reinforcement Learning
Jan 27, 2026Large reasoning models (LRMs) aim to solve diverse and complex problems through structured reasoning. Recent advances in group-based policy optimization methods have shown promise in enabling stable advantage estimation without reliance on process-level annotations. However, these methods rely on advantage gaps induced by high-quality samples within the same batch, which makes the training process fragile and inefficient when intra-group advantages collapse under challenging tasks. To address these problems, we propose a reinforcement learning mechanism named \emph{\textbf{R^3}} that along three directions: (1) a \emph{cross-context \underline{\textbf{R}}eplay} strategy that maintains the intra-group advantage by recalling valuable examples from historical trajectories of the same query, (2) an \emph{in-context self-\underline{\textbf{R}}eflection} mechanism enabling models to refine outputs by leveraging past failures, and (3) a \emph{structural entropy \underline{\textbf{R}}anking reward}, which assigns relative rewards to truncated or failed samples by ranking responses based on token-level entropy patterns, capturing both local exploration and global stability. We implement our method on Deepseek-R1-Distill-Qwen-1.5B and train it on the DeepscaleR-40k in the math domain. Experiments demonstrate our method achieves SoTA performance on several math benchmarks, representing significant improvements and fewer reasoning tokens over the base models. Code and model will be released.
Enhance Mobile Agents Thinking Process Via Iterative Preference Learning
May 18, 2025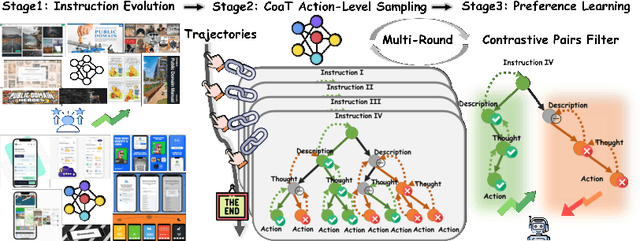
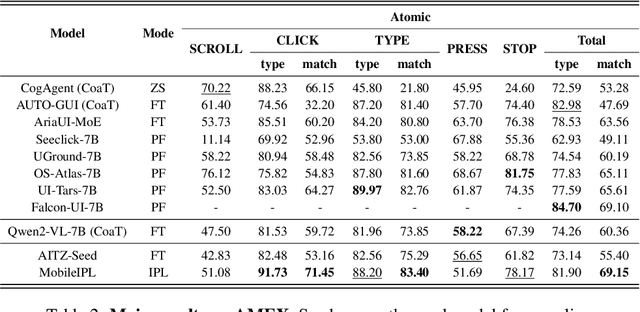
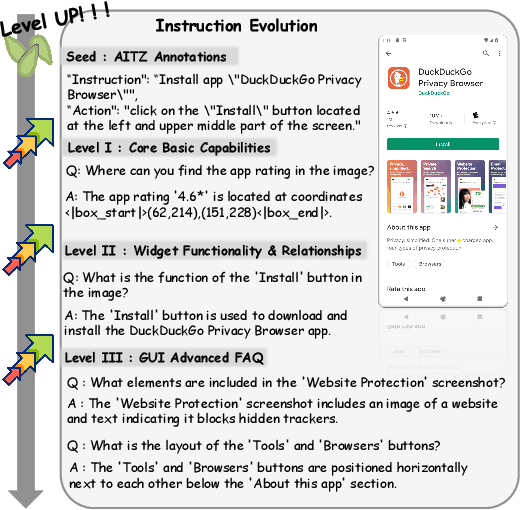
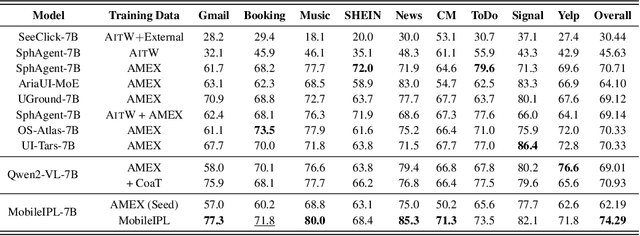
The Chain of Action-Planning Thoughts (CoaT) paradigm has been shown to improve the reasoning performance of VLM-based mobile agents in GUI tasks. However, the scarcity of diverse CoaT trajectories limits the expressiveness and generalization ability of such agents. While self-training is commonly employed to address data scarcity, existing approaches either overlook the correctness of intermediate reasoning steps or depend on expensive process-level annotations to construct process reward models (PRM). To address the above problems, we propose an Iterative Preference Learning (IPL) that constructs a CoaT-tree through interative sampling, scores leaf nodes using rule-based reward, and backpropagates feedback to derive Thinking-level Direct Preference Optimization (T-DPO) pairs. To prevent overfitting during warm-up supervised fine-tuning, we further introduce a three-stage instruction evolution, which leverages GPT-4o to generate diverse Q\&A pairs based on real mobile UI screenshots, enhancing both generality and layout understanding. Experiments on three standard Mobile GUI-agent benchmarks demonstrate that our agent MobileIPL outperforms strong baselines, including continual pretraining models such as OS-ATLAS and UI-TARS. It achieves state-of-the-art performance across three standard Mobile GUI-Agents benchmarks and shows strong generalization to out-of-domain scenarios.
Mobile-Bench-v2: A More Realistic and Comprehensive Benchmark for VLM-based Mobile Agents
May 17, 2025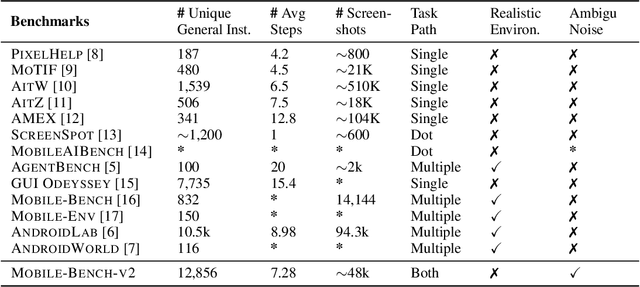
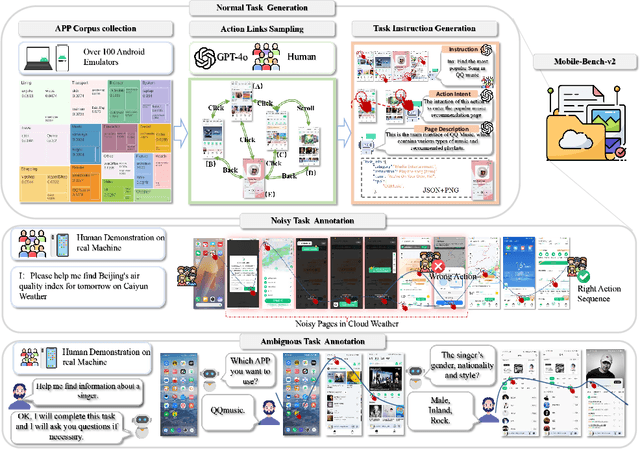
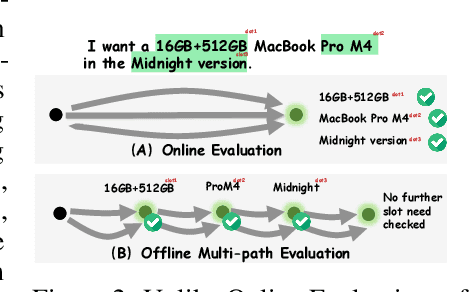
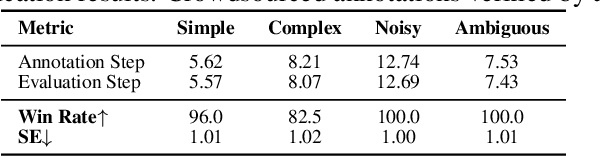
VLM-based mobile agents are increasingly popular due to their capabilities to interact with smartphone GUIs and XML-structured texts and to complete daily tasks. However, existing online benchmarks struggle with obtaining stable reward signals due to dynamic environmental changes. Offline benchmarks evaluate the agents through single-path trajectories, which stands in contrast to the inherently multi-solution characteristics of GUI tasks. Additionally, both types of benchmarks fail to assess whether mobile agents can handle noise or engage in proactive interactions due to a lack of noisy apps or overly full instructions during the evaluation process. To address these limitations, we use a slot-based instruction generation method to construct a more realistic and comprehensive benchmark named Mobile-Bench-v2. Mobile-Bench-v2 includes a common task split, with offline multi-path evaluation to assess the agent's ability to obtain step rewards during task execution. It contains a noisy split based on pop-ups and ads apps, and a contaminated split named AITZ-Noise to formulate a real noisy environment. Furthermore, an ambiguous instruction split with preset Q\&A interactions is released to evaluate the agent's proactive interaction capabilities. We conduct evaluations on these splits using the single-agent framework AppAgent-v1, the multi-agent framework Mobile-Agent-v2, as well as other mobile agents such as UI-Tars and OS-Atlas. Code and data are available at https://huggingface.co/datasets/xwk123/MobileBench-v2.
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
Dec 12, 2024We present LatentSync, an end-to-end lip sync framework based on audio conditioned latent diffusion models without any intermediate motion representation, diverging from previous diffusion-based lip sync methods based on pixel space diffusion or two-stage generation. Our framework can leverage the powerful capabilities of Stable Diffusion to directly model complex audio-visual correlations. Additionally, we found that the diffusion-based lip sync methods exhibit inferior temporal consistency due to the inconsistency in the diffusion process across different frames. We propose Temporal REPresentation Alignment (TREPA) to enhance temporal consistency while preserving lip-sync accuracy. TREPA uses temporal representations extracted by large-scale self-supervised video models to align the generated frames with the ground truth frames. Furthermore, we observe the commonly encountered SyncNet convergence issue and conduct comprehensive empirical studies, identifying key factors affecting SyncNet convergence in terms of model architecture, training hyperparameters, and data preprocessing methods. We significantly improve the accuracy of SyncNet from 91% to 94% on the HDTF test set. Since we did not change the overall training framework of SyncNet, our experience can also be applied to other lip sync and audio-driven portrait animation methods that utilize SyncNet. Based on the above innovations, our method outperforms state-of-the-art lip sync methods across various metrics on the HDTF and VoxCeleb2 datasets.
PMSS: Pretrained Matrices Skeleton Selection for LLM Fine-tuning
Sep 25, 2024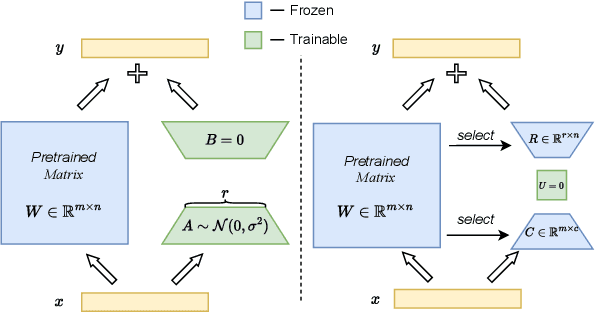
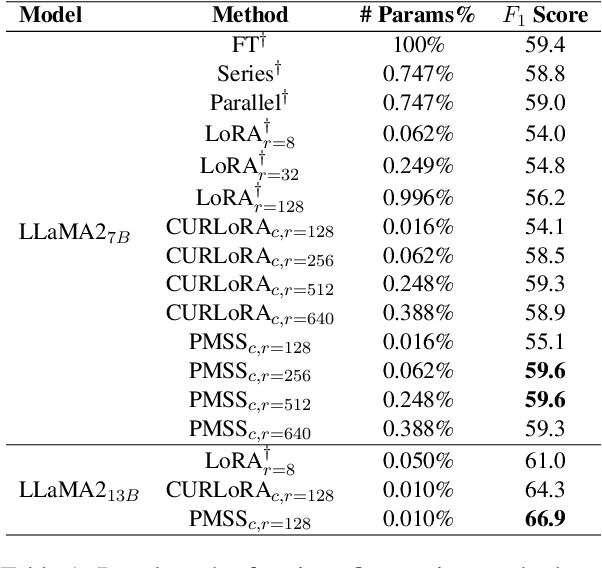

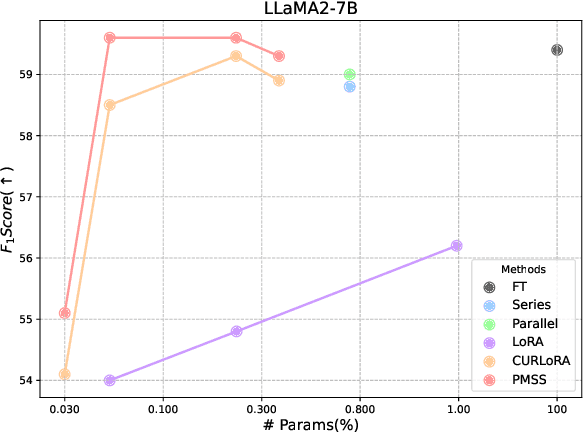
Low-rank adaptation (LoRA) and its variants have recently gained much interest due to their ability to avoid excessive inference costs. However, LoRA still encounters the following challenges: (1) Limitation of low-rank assumption; and (2) Its initialization method may be suboptimal. To this end, we propose PMSS(Pre-trained Matrices Skeleton Selection), which enables high-rank updates with low costs while leveraging semantic and linguistic information inherent in pre-trained weight. It achieves this by selecting skeletons from the pre-trained weight matrix and only learning a small matrix instead. Experiments demonstrate that PMSS outperforms LoRA and other fine-tuning methods across tasks with much less trainable parameters. We demonstrate its effectiveness, especially in handling complex tasks such as DROP benchmark(+3.4%/+5.9% on LLaMA2-7B/13B) and math reasoning(+12.89%/+5.61%/+3.11% on LLaMA2-7B, Mistral-7B and Gemma-7B of GSM8K). The code and model will be released soon.
Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents
Jul 01, 2024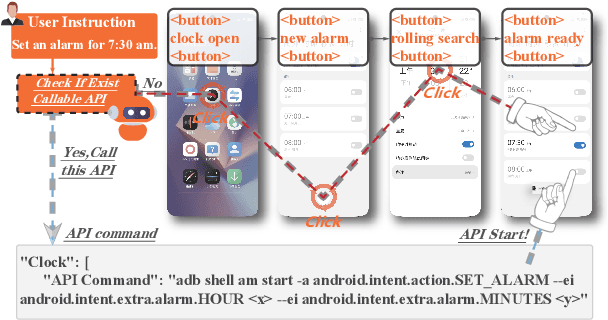


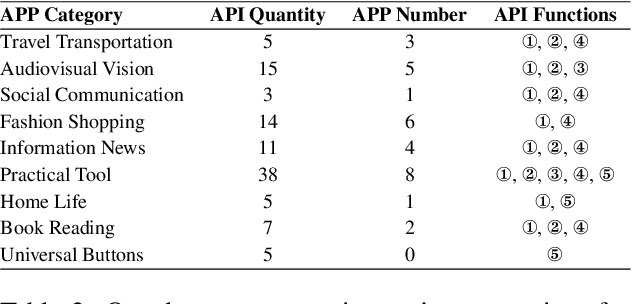
With the remarkable advancements of large language models (LLMs), LLM-based agents have become a research hotspot in human-computer interaction. However, there is a scarcity of benchmarks available for LLM-based mobile agents. Benchmarking these agents generally faces three main challenges: (1) The inefficiency of UI-only operations imposes limitations to task evaluation. (2) Specific instructions within a singular application lack adequacy for assessing the multi-dimensional reasoning and decision-making capacities of LLM mobile agents. (3) Current evaluation metrics are insufficient to accurately assess the process of sequential actions. To this end, we propose Mobile-Bench, a novel benchmark for evaluating the capabilities of LLM-based mobile agents. First, we expand conventional UI operations by incorporating 103 collected APIs to accelerate the efficiency of task completion. Subsequently, we collect evaluation data by combining real user queries with augmentation from LLMs. To better evaluate different levels of planning capabilities for mobile agents, our data is categorized into three distinct groups: SAST, SAMT, and MAMT, reflecting varying levels of task complexity. Mobile-Bench comprises 832 data entries, with more than 200 tasks specifically designed to evaluate multi-APP collaboration scenarios. Furthermore, we introduce a more accurate evaluation metric, named CheckPoint, to assess whether LLM-based mobile agents reach essential points during their planning and reasoning steps.
From Indeterminacy to Determinacy: Augmenting Logical Reasoning Capabilities with Large Language Models
Oct 28, 2023Recent advances in LLMs have revolutionized the landscape of reasoning tasks. To enhance the capabilities of LLMs to emulate human reasoning, prior works focus on modeling reasoning steps using specific thought structures like chains, trees, or graphs. However, LLM-based reasoning continues to encounter three challenges: 1) Selecting appropriate reasoning structures for various tasks; 2) Exploiting known conditions sufficiently and efficiently to deduce new insights; 3) Considering the impact of historical reasoning experience. To address these challenges, we propose DetermLR, a novel reasoning framework that formulates the reasoning process as a transformational journey from indeterminate premises to determinate ones. This process is marked by the incremental accumulation of determinate premises, making the conclusion progressively closer to clarity. DetermLR includes three essential components: 1) Premise identification: We categorize premises into two distinct types: determinate and indeterminate. This empowers LLMs to customize reasoning structures to match the specific task complexities. 2) Premise prioritization and exploration: We leverage quantitative measurements to assess the relevance of each premise to the target, prioritizing more relevant premises for exploring new insights. 3) Iterative process with reasoning memory: We introduce a reasoning memory module to automate storage and extraction of available premises and reasoning paths, preserving historical reasoning details for more accurate premise prioritization. Comprehensive experimental results show that DetermLR outperforms all baselines on four challenging logical reasoning tasks: LogiQA, ProofWriter, FOLIO, and LogicalDeduction. DetermLR can achieve better reasoning performance while requiring fewer visited states, highlighting its superior efficiency and effectiveness in tackling logical reasoning tasks.