 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance Mobile Agents Thinking Process Via Iterative Preference Learning
May 18, 2025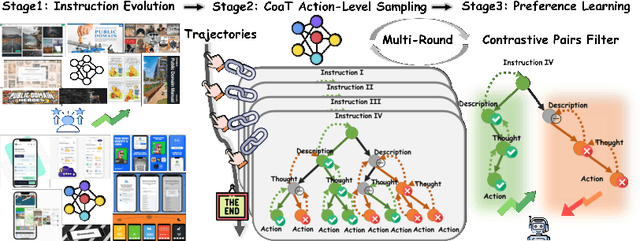
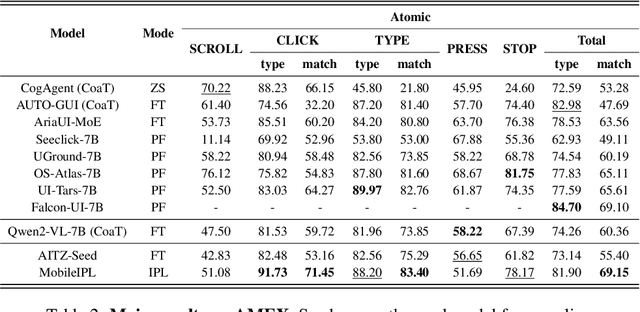
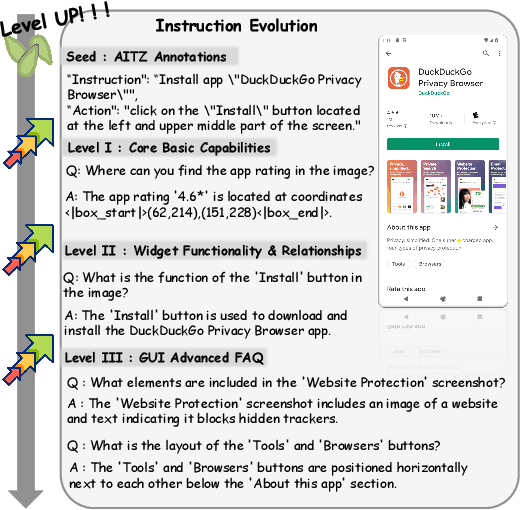
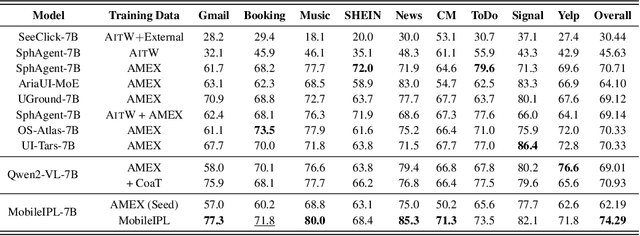
The Chain of Action-Planning Thoughts (CoaT) paradigm has been shown to improve the reasoning performance of VLM-based mobile agents in GUI tasks. However, the scarcity of diverse CoaT trajectories limits the expressiveness and generalization ability of such agents. While self-training is commonly employed to address data scarcity, existing approaches either overlook the correctness of intermediate reasoning steps or depend on expensive process-level annotations to construct process reward models (PRM). To address the above problems, we propose an Iterative Preference Learning (IPL) that constructs a CoaT-tree through interative sampling, scores leaf nodes using rule-based reward, and backpropagates feedback to derive Thinking-level Direct Preference Optimization (T-DPO) pairs. To prevent overfitting during warm-up supervised fine-tuning, we further introduce a three-stage instruction evolution, which leverages GPT-4o to generate diverse Q\&A pairs based on real mobile UI screenshots, enhancing both generality and layout understanding. Experiments on three standard Mobile GUI-agent benchmarks demonstrate that our agent MobileIPL outperforms strong baselines, including continual pretraining models such as OS-ATLAS and UI-TARS. It achieves state-of-the-art performance across three standard Mobile GUI-Agents benchmarks and shows strong generalization to out-of-domain scenarios.
SUBLLM: A Novel Efficient Architecture with Token Sequence Subsampling for LLM
Jun 03, 2024While Large Language Models (LLMs) have achieved remarkable success in various fields, the efficiency of training and inference remains a major challenge. To address this issue, we propose SUBLLM, short for Subsampling-Upsampling-Bypass Large Language Model, an innovative architecture that extends the core decoder-only framework by incorporating subsampling, upsampling, and bypass modules. The subsampling modules are responsible for shortening the sequence, while the upsampling modules restore the sequence length, and the bypass modules enhance convergence. In comparison to LLaMA, the proposed SUBLLM exhibits significant enhancements in both training and inference speeds as well as memory usage, while maintaining competitive few-shot performance. During training, SUBLLM increases speeds by 26% and cuts memory by 10GB per GPU. In inference, it boosts speeds by up to 37% and reduces memory by 1GB per GPU. The training and inference speeds can be enhanced by 34% and 52% respectively when the context window is expanded to 8192. We shall release the source code of the proposed architecture in the published version.
Exploring Representation Learning for Small-Footprint Keyword Spotting
Mar 20, 2023In this paper, we investigate representation learning for low-resource keyword spotting (KWS). The main challenges of KWS are limited labeled data and limited available device resources. To address those challenges, we explore representation learning for KWS by self-supervised contrastive learning and self-training with pretrained model. First, local-global contrastive siamese networks (LGCSiam) are designed to learn similar utterance-level representations for similar audio samplers by proposed local-global contrastive loss without requiring ground-truth. Second, a self-supervised pretrained Wav2Vec 2.0 model is applied as a constraint module (WVC) to force the KWS model to learn frame-level acoustic representations. By the LGCSiam and WVC modules, the proposed small-footprint KWS model can be pretrained with unlabeled data. Experiments on speech commands dataset show that the self-training WVC module and the self-supervised LGCSiam module significantly improve accuracy, especially in the case of training on a small labeled dataset.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022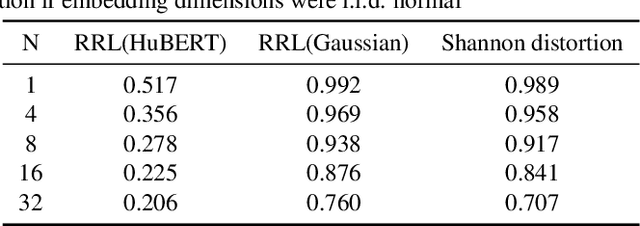
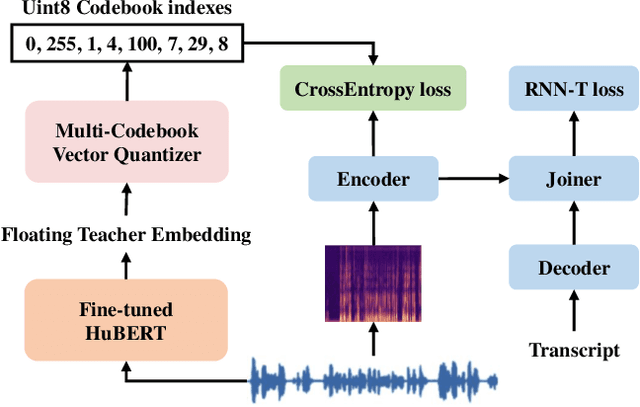

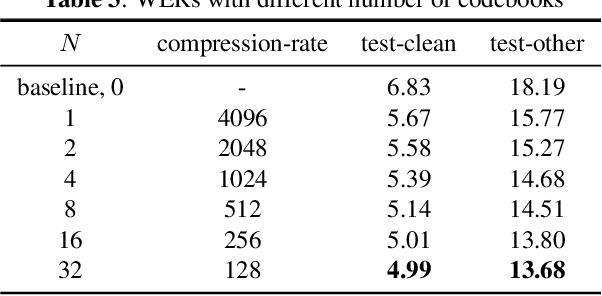
Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Multi-channel Speech Enhancement with 2-D Convolutional Time-frequency Domain Features and a Pre-trained Acoustic Model
Jul 26, 2021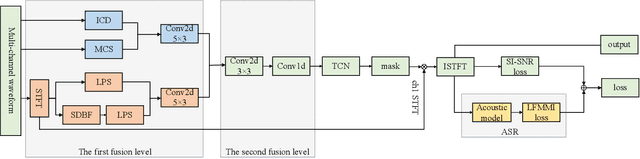
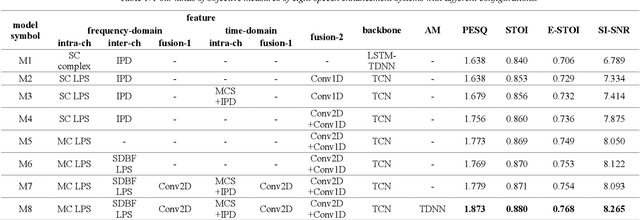
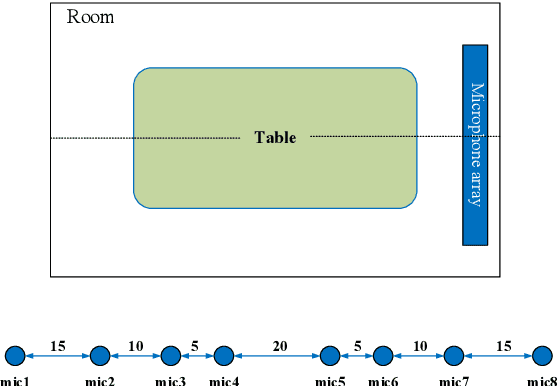
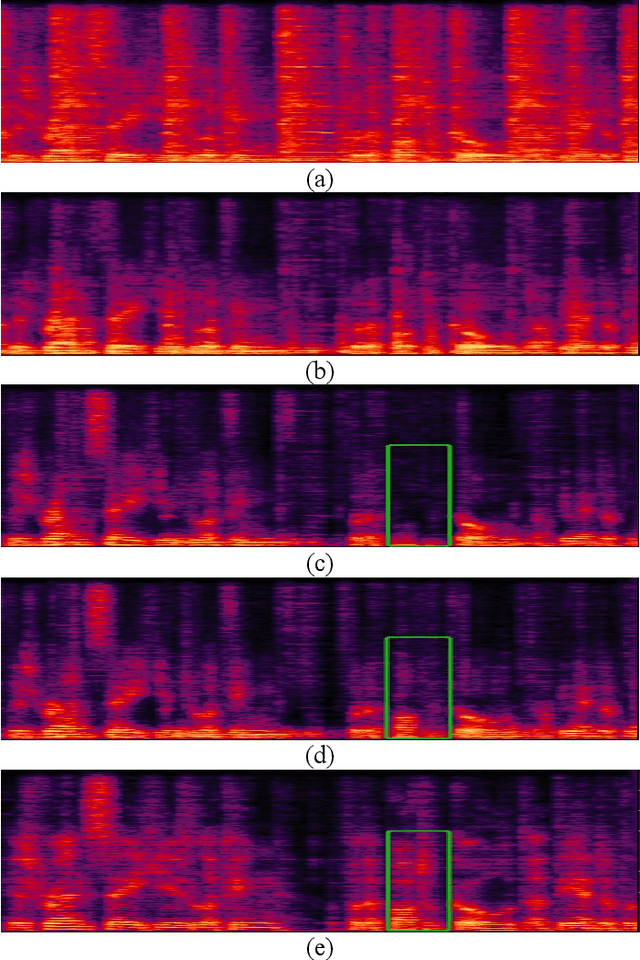
We propose a multi-channel speech enhancement approach with a novel two-stage feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion stage, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second stage of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.