 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-path Transformer Based Neural Beamformer for Target Speech Extraction
Sep 07, 2023



Neural beamformers, which integrate both pre-separation and beamforming modules, have demonstrated impressive effectiveness in target speech extraction. Nevertheless, the performance of these beamformers is inherently limited by the predictive accuracy of the pre-separation module. In this paper, we introduce a neural beamformer supported by a dual-path transformer. Initially, we employ the cross-attention mechanism in the time domain to extract crucial spatial information related to beamforming from the noisy covariance matrix. Subsequently, in the frequency domain, the self-attention mechanism is employed to enhance the model's ability to process frequency-specific details. By design, our model circumvents the influence of pre-separation modules, delivering performance in a more comprehensive end-to-end manner. Experimental results reveal that our model not only outperforms contemporary leading neural beamforming algorithms in separation performance but also achieves this with a significant reduction in parameter count.
Multi-channel Speech Enhancement with 2-D Convolutional Time-frequency Domain Features and a Pre-trained Acoustic Model
Jul 26, 2021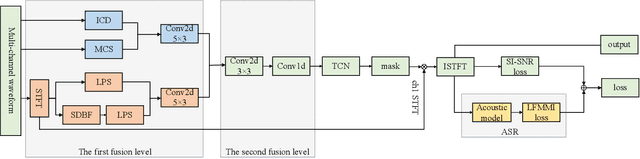
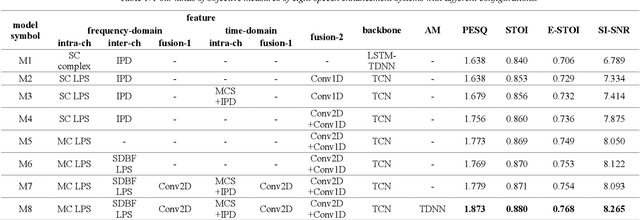
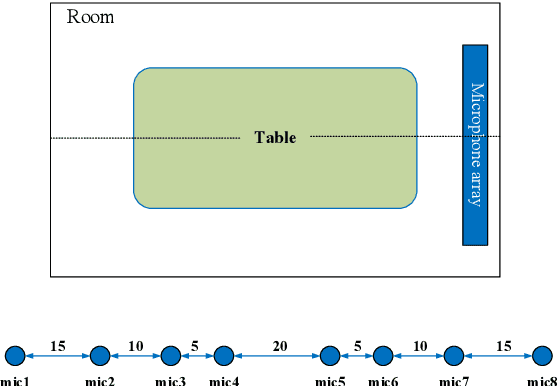
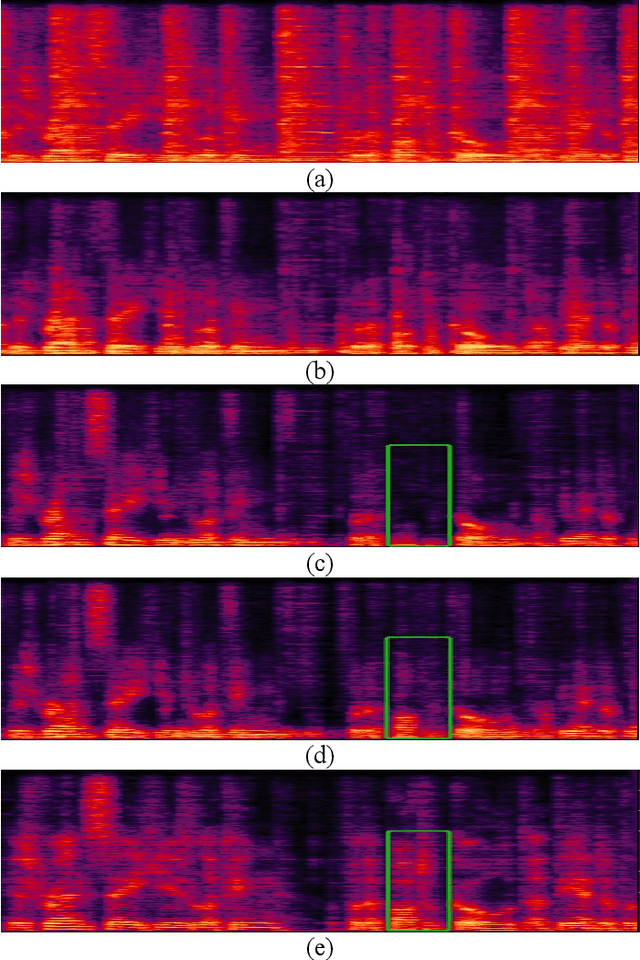
We propose a multi-channel speech enhancement approach with a novel two-stage feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion stage, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second stage of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.