 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking in cocktail party: Chain-of-Thought and reinforcement learning for target speaker automatic speech recognition
Sep 19, 2025Target Speaker Automatic Speech Recognition (TS-ASR) aims to transcribe the speech of a specified target speaker from multi-speaker mixtures in cocktail party scenarios. Recent advancement of Large Audio-Language Models (LALMs) has already brought some new insights to TS-ASR. However, significant room for optimization remains for the TS-ASR task within the LALMs architecture. While Chain of Thoughts (CoT) and Reinforcement Learning (RL) have proven effective in certain speech tasks, TS-ASR, which requires the model to deeply comprehend speech signals, differentiate various speakers, and handle overlapping utterances is particularly well-suited to a reasoning-guided approach. Therefore, we propose a novel framework that incorporates CoT and RL training into TS-ASR for performance improvement. A novel CoT dataset of TS-ASR is constructed, and the TS-ASR model is first trained on regular data and then fine-tuned on CoT data. Finally, the model is further trained with RL using selected data to enhance generalized reasoning capabilities. Experiment results demonstrate a significant improvement of TS-ASR performance with CoT and RL training, establishing a state-of-the-art performance compared with previous works of TS-ASR on comparable datasets.
Lightweight speech enhancement guided target speech extraction in noisy multi-speaker scenarios
Aug 27, 2025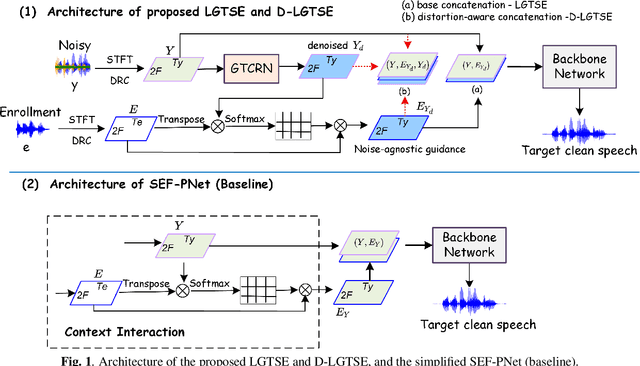
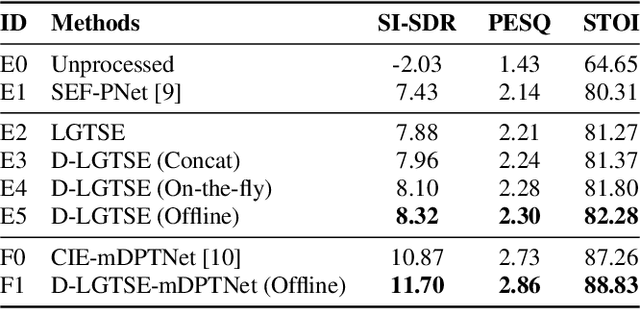
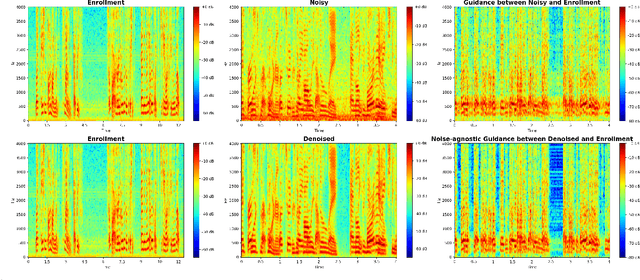
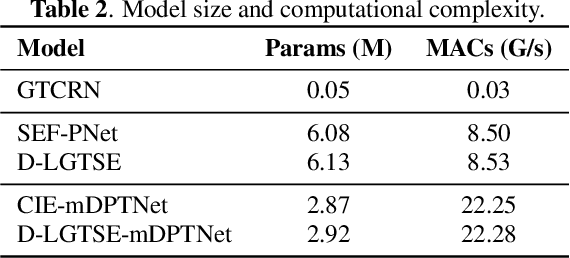
Target speech extraction (TSE) has achieved strong performance in relatively simple conditions such as one-speaker-plus-noise and two-speaker mixtures, but its performance remains unsatisfactory in noisy multi-speaker scenarios. To address this issue, we introduce a lightweight speech enhancement model, GTCRN, to better guide TSE in noisy environments. Building on our competitive previous speaker embedding/encoder-free framework SEF-PNet, we propose two extensions: LGTSE and D-LGTSE. LGTSE incorporates noise-agnostic enrollment guidance by denoising the input noisy speech before context interaction with enrollment speech, thereby reducing noise interference. D-LGTSE further improves system robustness against speech distortion by leveraging denoised speech as an additional noisy input during training, expanding the dynamic range of noisy conditions and enabling the model to directly learn from distorted signals. Furthermore, we propose a two-stage training strategy, first with GTCRN enhancement-guided pre-training and then joint fine-tuning, to fully exploit model potential.Experiments on the Libri2Mix dataset demonstrate significant improvements of 0.89 dB in SISDR, 0.16 in PESQ, and 1.97% in STOI, validating the effectiveness of our approach. Our code is publicly available at https://github.com/isHuangZiling/D-LGTSE.
Multi-channel Speech Enhancement with 2-D Convolutional Time-frequency Domain Features and a Pre-trained Acoustic Model
Jul 26, 2021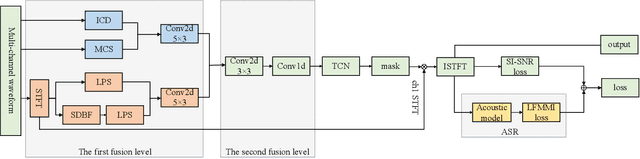
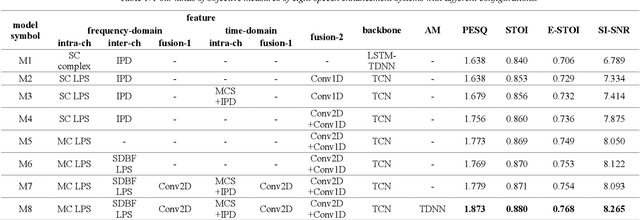
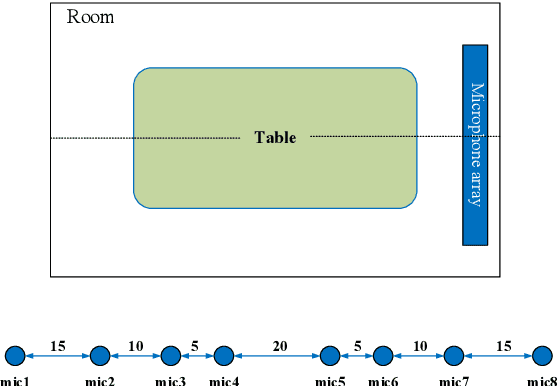
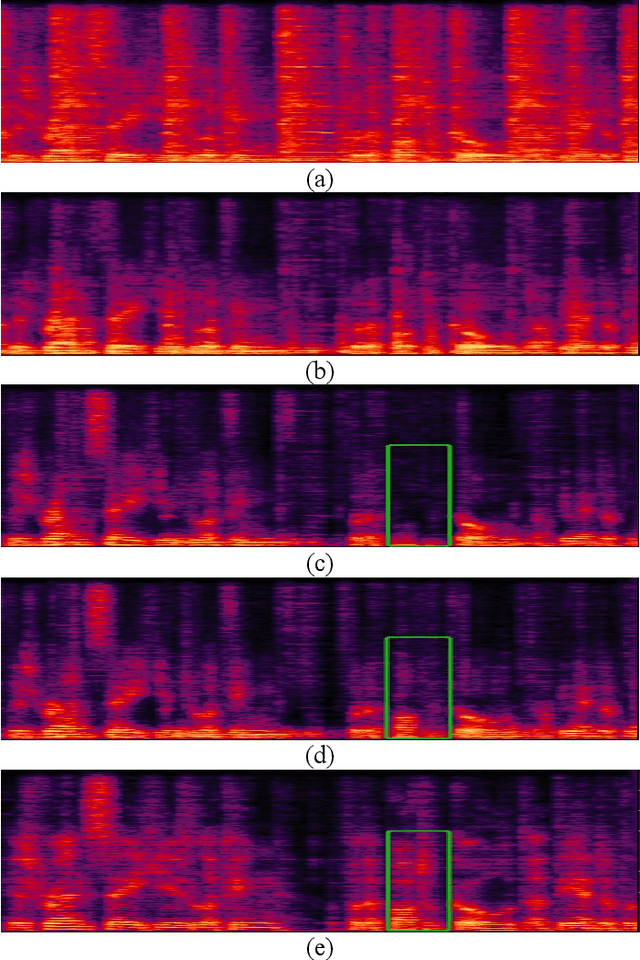
We propose a multi-channel speech enhancement approach with a novel two-stage feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion stage, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second stage of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.