 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnroll-on-Wakeup: A First Comparative Study of Target Speech Extraction for Seamless Interaction in Real Noisy Human-Machine Dialogue Scenarios
Feb 17, 2026Target speech extraction (TSE) typically relies on pre-recorded high-quality enrollment speech, which disrupts user experience and limits feasibility in spontaneous interaction. In this paper, we propose Enroll-on-Wakeup (EoW), a novel framework where the wake-word segment, captured naturally during human-machine interaction, is automatically utilized as the enrollment reference. This eliminates the need for pre-collected speech to enable a seamless experience. We perform the first systematic study of EoW-TSE, evaluating advanced discriminative and generative models under real diverse acoustic conditions. Given the short and noisy nature of wake-word segments, we investigate enrollment augmentation using LLM-based TTS. Results show that while current TSE models face performance degradation in EoW-TSE, TTS-based assistance significantly enhances the listening experience, though gaps remain in speech recognition accuracy.
Lightweight speech enhancement guided target speech extraction in noisy multi-speaker scenarios
Aug 27, 2025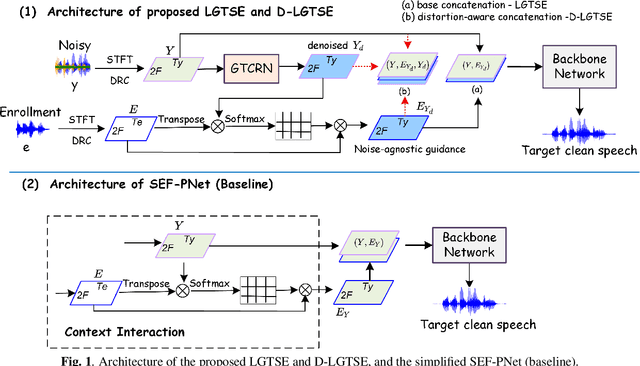
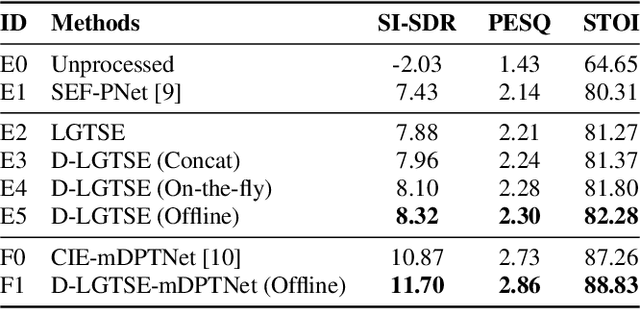
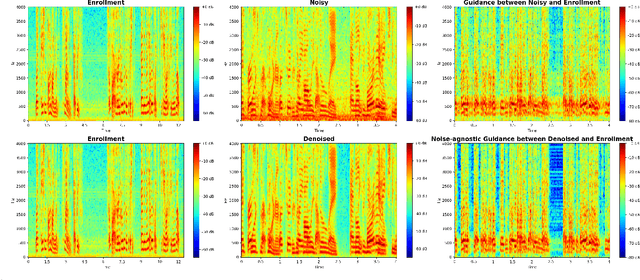
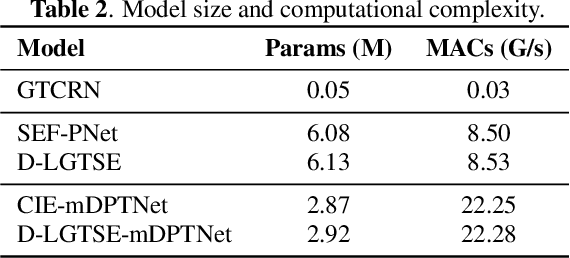
Target speech extraction (TSE) has achieved strong performance in relatively simple conditions such as one-speaker-plus-noise and two-speaker mixtures, but its performance remains unsatisfactory in noisy multi-speaker scenarios. To address this issue, we introduce a lightweight speech enhancement model, GTCRN, to better guide TSE in noisy environments. Building on our competitive previous speaker embedding/encoder-free framework SEF-PNet, we propose two extensions: LGTSE and D-LGTSE. LGTSE incorporates noise-agnostic enrollment guidance by denoising the input noisy speech before context interaction with enrollment speech, thereby reducing noise interference. D-LGTSE further improves system robustness against speech distortion by leveraging denoised speech as an additional noisy input during training, expanding the dynamic range of noisy conditions and enabling the model to directly learn from distorted signals. Furthermore, we propose a two-stage training strategy, first with GTCRN enhancement-guided pre-training and then joint fine-tuning, to fully exploit model potential.Experiments on the Libri2Mix dataset demonstrate significant improvements of 0.89 dB in SISDR, 0.16 in PESQ, and 1.97% in STOI, validating the effectiveness of our approach. Our code is publicly available at https://github.com/isHuangZiling/D-LGTSE.
Unified Architecture and Unsupervised Speech Disentanglement for Speaker Embedding-Free Enrollment in Personalized Speech Enhancement
May 18, 2025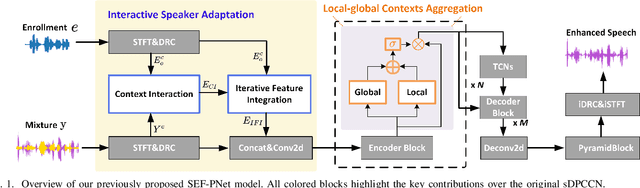


Conventional speech enhancement (SE) aims to improve speech perception and intelligibility by suppressing noise without requiring enrollment speech as reference, whereas personalized SE (PSE) addresses the cocktail party problem by extracting a target speaker's speech using enrollment speech. While these two tasks tackle different yet complementary challenges in speech signal processing, they often share similar model architectures, with PSE incorporating an additional branch to process enrollment speech. This suggests developing a unified model capable of efficiently handling both SE and PSE tasks, thereby simplifying deployment while maintaining high performance. However, PSE performance is sensitive to variations in enrollment speech, like emotional tone, which limits robustness in real-world applications. To address these challenges, we propose two novel models, USEF-PNet and DSEF-PNet, both extending our previous SEF-PNet framework. USEF-PNet introduces a unified architecture for processing enrollment speech, integrating SE and PSE into a single framework to enhance performance and streamline deployment. Meanwhile, DSEF-PNet incorporates an unsupervised speech disentanglement approach by pairing a mixture speech with two different enrollment utterances and enforcing consistency in the extracted target speech. This strategy effectively isolates high-quality speaker identity information from enrollment speech, reducing interference from factors such as emotion and content, thereby improving PSE robustness. Additionally, we explore a long-short enrollment pairing (LSEP) strategy to examine the impact of enrollment speech duration during both training and evaluation. Extensive experiments on the Libri2Mix and VoiceBank DEMAND demonstrate that our proposed USEF-PNet, DSEF-PNet all achieve substantial performance improvements, with random enrollment duration performing slightly better.
SEF-PNet: Speaker Encoder-Free Personalized Speech Enhancement with Local and Global Contexts Aggregation
Jan 20, 2025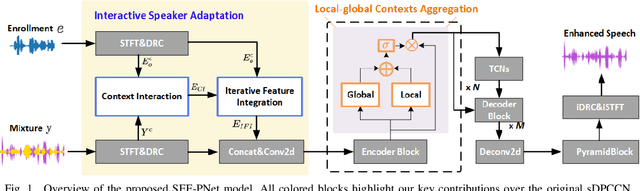
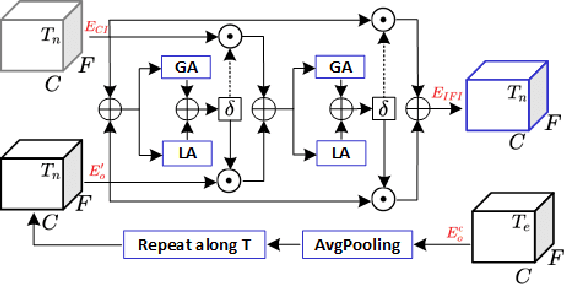
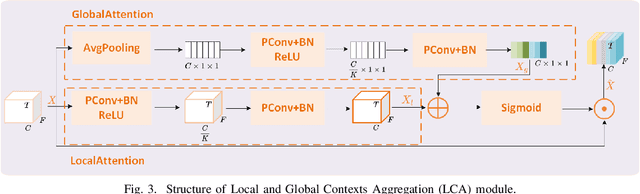
Personalized speech enhancement (PSE) methods typically rely on pre-trained speaker verification models or self-designed speaker encoders to extract target speaker clues, guiding the PSE model in isolating the desired speech. However, these approaches suffer from significant model complexity and often underutilize enrollment speaker information, limiting the potential performance of the PSE model. To address these limitations, we propose a novel Speaker Encoder-Free PSE network, termed SEF-PNet, which fully exploits the information present in both the enrollment speech and noisy mixtures. SEF-PNet incorporates two key innovations: Interactive Speaker Adaptation (ISA) and Local-Global Context Aggregation (LCA). ISA dynamically modulates the interactions between enrollment and noisy signals to enhance the speaker adaptation, while LCA employs advanced channel attention within the PSE encoder to effectively integrate local and global contextual information, thus improving feature learning. Experiments on the Libri2Mix dataset demonstrate that SEF-PNet significantly outperforms baseline models, achieving state-of-the-art PSE performance.
A Mask Free Neural Network for Monaural Speech Enhancement
Jun 07, 2023

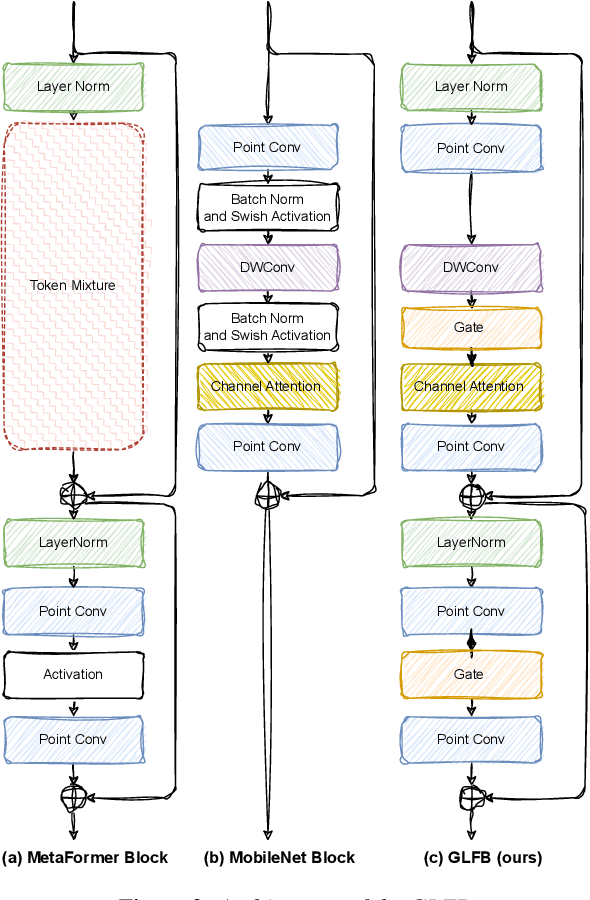

In speech enhancement, the lack of clear structural characteristics in the target speech phase requires the use of conservative and cumbersome network frameworks. It seems difficult to achieve competitive performance using direct methods and simple network architectures. However, we propose the MFNet, a direct and simple network that can not only map speech but also map reverse noise. This network is constructed by stacking global local former blocks (GLFBs), which combine the advantages of Mobileblock for global processing and Metaformer architecture for local interaction. Our experimental results demonstrate that our network using mapping method outperforms masking methods, and direct mapping of reverse noise is the optimal solution in strong noise environments. In a horizontal comparison on the 2020 Deep Noise Suppression (DNS) challenge test set without reverberation, to the best of our knowledge, MFNet is the current state-of-the-art (SOTA) mapping model.
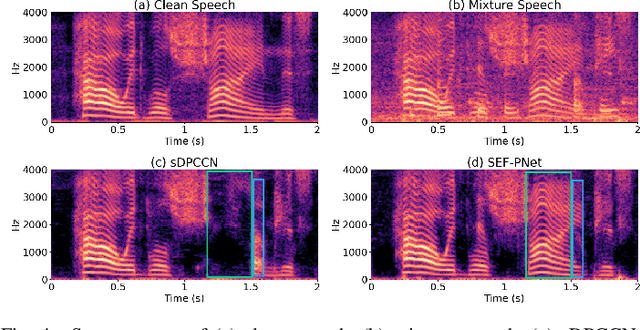
Dynamic Acoustic Compensation and Adaptive Focal Training for Personalized Speech Enhancement
Nov 22, 2022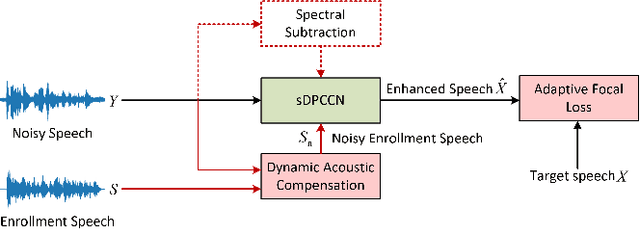
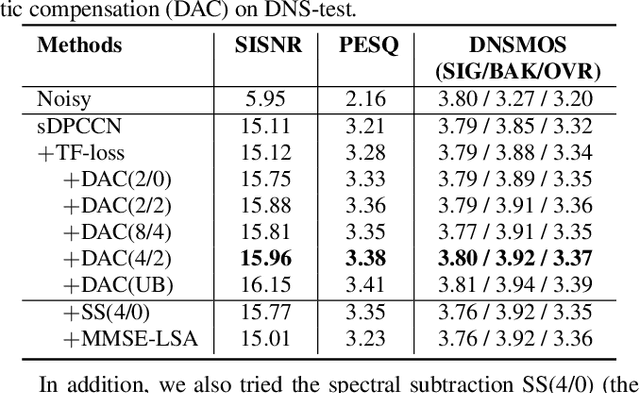
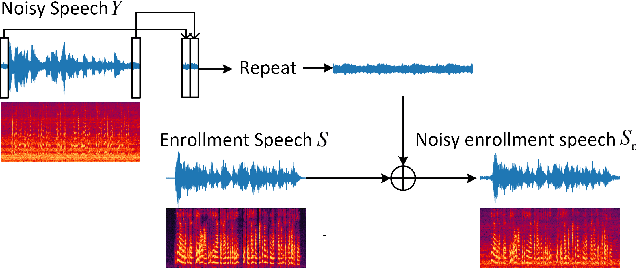
Recently, more and more personalized speech enhancement systems (PSE) with excellent performance have been proposed. However, two critical issues still limit the performance and generalization ability of the model: 1) Acoustic environment mismatch between the test noisy speech and target speaker enrollment speech; 2) Hard sample mining and learning. In this paper, dynamic acoustic compensation (DAC) is proposed to alleviate the environment mismatch, by intercepting the noise or environmental acoustic segments from noisy speech and mixing it with the clean enrollment speech. To well exploit the hard samples in training data, we propose an adaptive focal training (AFT) strategy by assigning adaptive loss weights to hard and non-hard samples during training. A time-frequency multi-loss training is further introduced to improve and generalize our previous work sDPCCN for PSE. The effectiveness of proposed methods are examined on the DNS4 Challenge dataset. Results show that, the DAC brings large improvements in terms of multiple evaluation metrics, and AFT reduces the hard sample rate significantly and produces obvious MOS score improvement.
PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement
Mar 04, 2022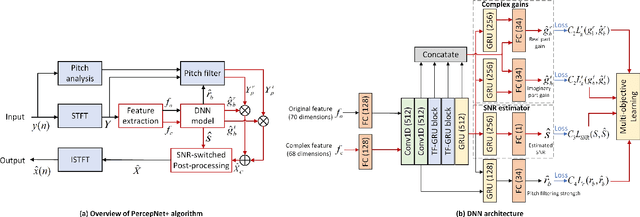
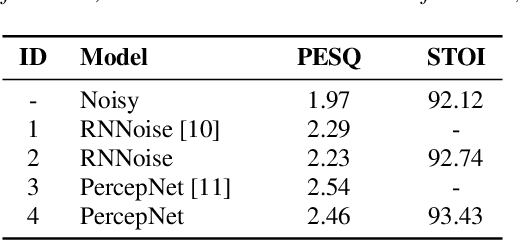
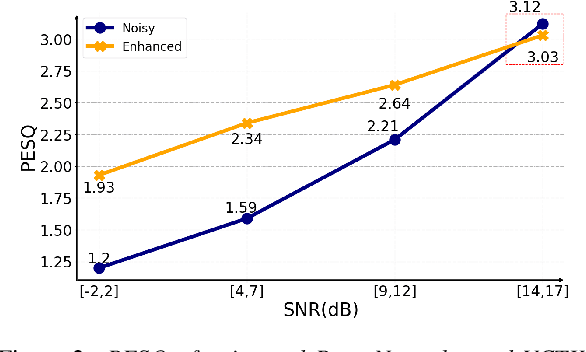
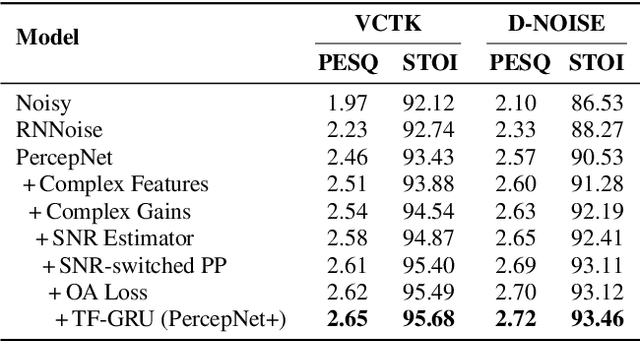
PercepNet, a recent extension of the RNNoise, an efficient, high-quality and real-time full-band speech enhancement technique, has shown promising performance in various public deep noise suppression tasks. This paper proposes a new approach, named PercepNet+, to further extend the PercepNet with four significant improvements. First, we introduce a phase-aware structure to leverage the phase information into PercepNet, by adding the complex features and complex subband gains as the deep network input and output respectively. Then, a signal-to-noise ratio (SNR) estimator and an SNR switched post-processing are specially designed to alleviate the over attenuation (OA) that appears in high SNR conditions of the original PercepNet. Moreover, the GRU layer is replaced by TF-GRU to model both temporal and frequency dependencies. Finally, we propose to integrate the loss of complex subband gain, SNR, pitch filtering strength, and an OA loss in a multi-objective learning manner to further improve the speech enhancement performance. Experimental results show that, the proposed PercepNet+ outperforms the original PercepNet significantly in terms of both PESQ and STOI, without increasing the model size too much.
Real-time Monaural Speech Enhancement With Short-time Discrete Cosine Transform
Feb 09, 2021

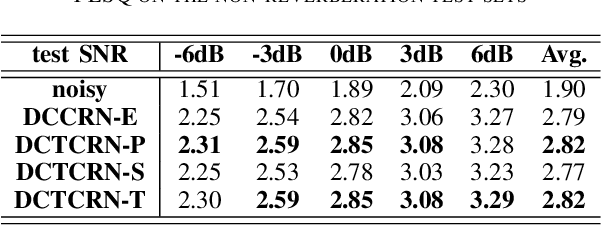
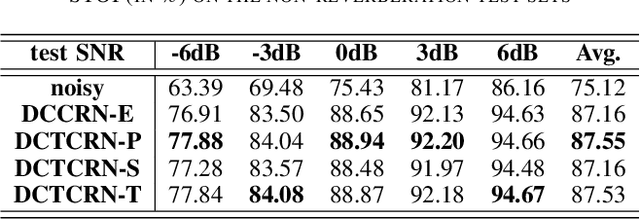
Speech enhancement algorithms based on deep learning have been improved in terms of speech intelligibility and perceptual quality greatly. Many methods focus on enhancing the amplitude spectrum while reconstructing speech using the mixture phase. Since the clean phase is very important and difficult to predict, the performance of these methods will be limited. Some researchers attempted to estimate the phase spectrum directly or indirectly, but the effect is not ideal. Recently, some studies proposed the complex-valued model and achieved state-of-the-art performance, such as deep complex convolution recurrent network (DCCRN). However, the computation of the model is huge. To reduce the complexity and further improve the performance, we propose a novel method using discrete cosine transform as the input in this paper, called deep cosine transform convolutional recurrent network (DCTCRN). Experimental results show that DCTCRN achieves state-of-the-art performance both on objective and subjective metrics. Compared with noisy mixtures, the mean opinion score (MOS) increased by 0.46 (2.86 to 3.32) absolute processed by the proposed model with only 2.86M parameters.