 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Spatial Features in Foundation-Model-Based Speaker Diarization
Jan 05, 2026Recent advances in speaker diarization exploit large pretrained foundation models, such as WavLM, to achieve state-of-the-art performance on multiple datasets. Systems like DiariZen leverage these rich single-channel representations, but are limited to single-channel audio, preventing the use of spatial cues available in multi-channel recordings. This work analyzes the impact of incorporating spatial information into a state-of-the-art single-channel diarization system by evaluating several strategies for conditioning the model on multi-channel spatial features. Experiments on meeting-style datasets indicate that spatial information can improve diarization performance, but the overall improvement is smaller than expected for the proposed system, suggesting that the features aggregated over all WavLM layers already capture much of the information needed for accurate speaker discrimination, also in overlapping speech regions. These findings provide insight into the potential and limitations of using spatial cues to enhance foundation model-based diarization.
FlexIO: Flexible Single- and Multi-Channel Speech Separation and Enhancement
Oct 24, 2025Speech separation and enhancement (SSE) has advanced remarkably and achieved promising results in controlled settings, such as a fixed number of speakers and a fixed array configuration. Towards a universal SSE system, single-channel systems have been extended to deal with a variable number of speakers (i.e., outputs). Meanwhile, multi-channel systems accommodating various array configurations (i.e., inputs) have been developed. However, these attempts have been pursued separately. In this paper, we propose a flexible input and output SSE system, named FlexIO. It performs conditional separation using prompt vectors, one per speaker as a condition, allowing separation of an arbitrary number of speakers. Multi-channel mixtures are processed together with the prompt vectors via an array-agnostic channel communication mechanism. Our experiments demonstrate that FlexIO successfully covers diverse conditions with one to five microphones and one to three speakers. We also confirm the robustness of FlexIO on CHiME-4 real data.
BUT System for the MLC-SLM Challenge
Jun 16, 2025



We present a two-speaker automatic speech recognition (ASR) system that combines DiCoW -- a diarization-conditioned variant of Whisper -- with DiariZen, a diarization pipeline built on top of Pyannote. We first evaluate both systems in out-of-domain (OOD) multilingual scenarios without any fine-tuning. In this scenario, DiariZen consistently outperforms the baseline Pyannote diarization model, demonstrating strong generalization. Despite being fine-tuned on English-only data for target-speaker ASR, DiCoW retains solid multilingual performance, indicating that encoder modifications preserve Whisper's multilingual capabilities. We then fine-tune both DiCoW and DiariZen on the MLC-SLM challenge data. The fine-tuned DiariZen continues to outperform the fine-tuned Pyannote baseline, while DiCoW sees further gains from domain adaptation. Our final system achieves a micro-average tcpWER/CER of 16.75% and ranks second in Task 2 of the MLC-SLM challenge. Lastly, we identify several labeling inconsistencies in the training data -- such as missing speech segments and incorrect silence annotations -- which can hinder diarization fine-tuning. We propose simple mitigation strategies to address these issues and improve system robustness.
Fine-tune Before Structured Pruning: Towards Compact and Accurate Self-Supervised Models for Speaker Diarization
May 30, 2025
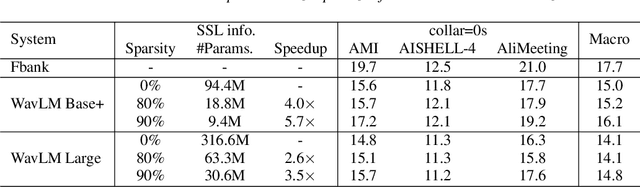


Self-supervised learning (SSL) models like WavLM can be effectively utilized when building speaker diarization systems but are often large and slow, limiting their use in resource constrained scenarios. Previous studies have explored compression techniques, but usually for the price of degraded performance at high pruning ratios. In this work, we propose to compress SSL models through structured pruning by introducing knowledge distillation. Different from the existing works, we emphasize the importance of fine-tuning SSL models before pruning. Experiments on far-field single-channel AMI, AISHELL-4, and AliMeeting datasets show that our method can remove redundant parameters of WavLM Base+ and WavLM Large by up to 80% without any performance degradation. After pruning, the inference speeds on a single GPU for the Base+ and Large models are 4.0 and 2.6 times faster, respectively. Our source code is publicly available.
Analysis of ABC Frontend Audio Systems for the NIST-SRE24
May 21, 2025We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Dec 30, 2024



Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.
Leveraging Self-Supervised Learning for Speaker Diarization
Sep 14, 2024



End-to-end neural diarization has evolved considerably over the past few years, but data scarcity is still a major obstacle for further improvements. Self-supervised learning methods such as WavLM have shown promising performance on several downstream tasks, but their application on speaker diarization is somehow limited. In this work, we explore using WavLM to alleviate the problem of data scarcity for neural diarization training. We use the same pipeline as Pyannote and improve the local end-to-end neural diarization with WavLM and Conformer. Experiments on far-field AMI, AISHELL-4, and AliMeeting datasets show that our method substantially outperforms the Pyannote baseline and achieves performance comparable to the state-of-the-art results on AMI and AISHELL-4. In addition, by analyzing the system performance under different data quantity scenarios, we show that WavLM representations are much more robust against data scarcity than filterbank features, enabling less data hungry training strategies. Furthermore, we found that simulated data, usually used to train endto-end diarization models, does not help when using WavLM in our experiments. Additionally, we also evaluate our model on the recent CHiME8 NOTSOFAR-1 task where it achieves better performance than the Pyannote baseline. Our source code is publicly available at https://github.com/BUTSpeechFIT/DiariZen.
DiaCorrect: Error Correction Back-end For Speaker Diarization
Sep 15, 2023

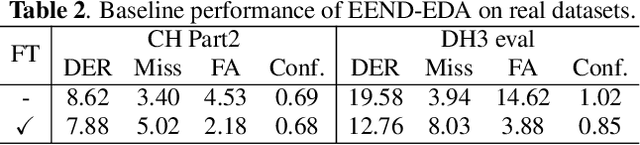

In this work, we propose an error correction framework, named DiaCorrect, to refine the output of a diarization system in a simple yet effective way. This method is inspired by error correction techniques in automatic speech recognition. Our model consists of two parallel convolutional encoders and a transform-based decoder. By exploiting the interactions between the input recording and the initial system's outputs, DiaCorrect can automatically correct the initial speaker activities to minimize the diarization errors. Experiments on 2-speaker telephony data show that the proposed DiaCorrect can effectively improve the initial model's results. Our source code is publicly available at https://github.com/BUTSpeechFIT/diacorrect.
HYBRIDFORMER: improving SqueezeFormer with hybrid attention and NSR mechanism
Mar 15, 2023



SqueezeFormer has recently shown impressive performance in automatic speech recognition (ASR). However, its inference speed suffers from the quadratic complexity of softmax-attention (SA). In addition, limited by the large convolution kernel size, the local modeling ability of SqueezeFormer is insufficient. In this paper, we propose a novel method HybridFormer to improve SqueezeFormer in a fast and efficient way. Specifically, we first incorporate linear attention (LA) and propose a hybrid LASA paradigm to increase the model's inference speed. Second, a hybrid neural architecture search (NAS) guided structural re-parameterization (SRep) mechanism, termed NSR, is proposed to enhance the ability of the model to extract local interactions. Extensive experiments conducted on the LibriSpeech dataset demonstrate that our proposed HybridFormer can achieve a 9.1% relative word error rate (WER) reduction over SqueezeFormer on the test-other dataset. Furthermore, when input speech is 30s, the HybridFormer can improve the model's inference speed up to 18%. Our source code is available online.
Dynamic Acoustic Compensation and Adaptive Focal Training for Personalized Speech Enhancement
Nov 22, 2022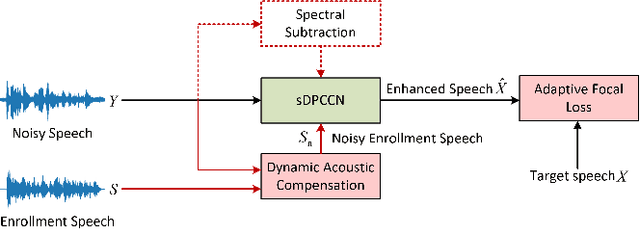
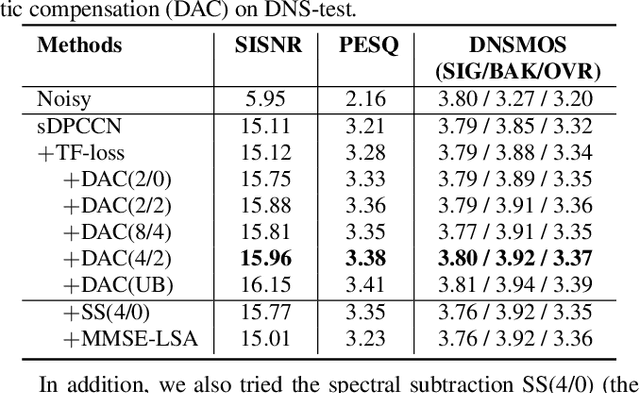
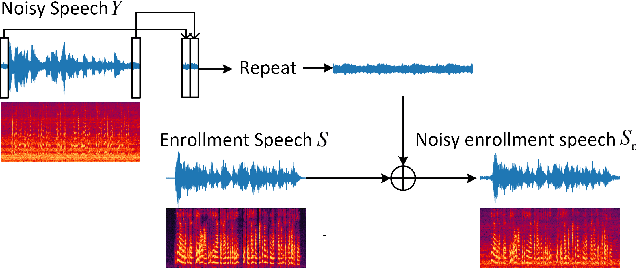
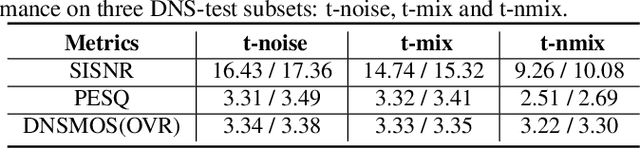
Recently, more and more personalized speech enhancement systems (PSE) with excellent performance have been proposed. However, two critical issues still limit the performance and generalization ability of the model: 1) Acoustic environment mismatch between the test noisy speech and target speaker enrollment speech; 2) Hard sample mining and learning. In this paper, dynamic acoustic compensation (DAC) is proposed to alleviate the environment mismatch, by intercepting the noise or environmental acoustic segments from noisy speech and mixing it with the clean enrollment speech. To well exploit the hard samples in training data, we propose an adaptive focal training (AFT) strategy by assigning adaptive loss weights to hard and non-hard samples during training. A time-frequency multi-loss training is further introduced to improve and generalize our previous work sDPCCN for PSE. The effectiveness of proposed methods are examined on the DNS4 Challenge dataset. Results show that, the DAC brings large improvements in terms of multiple evaluation metrics, and AFT reduces the hard sample rate significantly and produces obvious MOS score improvement.