 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Overlapped Speech with Shuffles
Mar 18, 2026We propose to model parallel streams of data, such as overlapped speech, using shuffles. Specifically, this paper shows how the shuffle product and partial order finite-state automata (FSAs) can be used for alignment and speaker-attributed transcription of overlapped speech. We train using the total score on these FSAs as a loss function, marginalizing over all possible serializations of overlapping sequences at subword, word, and phrase levels. To reduce graph size, we impose temporal constraints by constructing partial order FSAs. We address speaker attribution by modeling (token, speaker) tuples directly. Viterbi alignment through the shuffle product FSA directly enables one-pass alignment. We evaluate performance on synthetic LibriSpeech overlaps. To our knowledge, this is the first algorithm that enables single-pass alignment of multi-talker recordings. All algorithms are implemented using k2 / Icefall.
Integrated Spoofing-Robust Automatic Speaker Verification via a Three-Class Formulation and LLR
Mar 14, 2026Spoofing-robust automatic speaker verification (SASV) aims to integrate automatic speaker verification (ASV) and countermeasure (CM). A popular solution is fusion of independent ASV and CM scores. To better modeling SASV, some frameworks integrate ASV and CM within a single network. However, these solutions are typically bi-encoder based, offer limited interpretability, and cannot be readily adapted to new evaluation parameters without retraining. Based on this, we propose a unified end-to-end framework via a three-class formulation that enables log-likelihood ratio (LLR) inference from class logits for a more interpretable decision pipeline. Experiments show comparable performance to existing methods on ASVSpoof5 and better results on SpoofCeleb. The visualization and analysis also prove that the three-class reformulation provides more interpretability.
Can LLMs Help Localize Fake Words in Partially Fake Speech?
Mar 11, 2026Large language models (LLMs), trained on large-scale text, have recently attracted significant attention for their strong performance across many tasks. Motivated by this, we investigate whether a text-trained LLM can help localize fake words in partially fake speech, where only specific words within a speech are edited. We build a speech LLM to perform fake word localization via next token prediction. Experiments and analyses on AV-Deepfake1M and PartialEdit indicates that the model frequently leverages editing-style pattern learned from the training data, particularly word-level polarity substitutions for those two databases we discussed, as cues for localizing fake words. Although such particular patterns provide useful information in an in-domain scenario, how to avoid over-reliance on such particular pattern and improve generalization to unseen editing styles remains an open question.
Universal Speech Content Factorization
Mar 09, 2026We propose Universal Speech Content Factorization (USCF), a simple and invertible linear method for extracting a low-rank speech representation in which speaker timbre is suppressed while phonetic content is preserved. USCF extends Speech Content Factorization, a closed-set voice conversion (VC) method, to an open-set setting by learning a universal speech-to-content mapping via least-squares optimization and deriving speaker-specific transformations from only a few seconds of target speech. We show through embedding analysis that USCF effectively removes speaker-dependent variation. As a zero-shot VC system, USCF achieves competitive intelligibility, naturalness, and speaker similarity compared to methods that require substantially more target-speaker data or additional neural training. Finally, we demonstrate that as a training-efficient timbre-disentangled speech feature, USCF features can serve as the acoustic representation for training timbre-prompted text-to-speech models. Speech samples and code are publicly available.
SE-DiCoW: Self-Enrolled Diarization-Conditioned Whisper
Jan 27, 2026Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a major challenge. While some approaches achieve strong performance when fine-tuned on specific domains, few systems generalize well across out-of-domain datasets. Our prior work, Diarization-Conditioned Whisper (DiCoW), leverages speaker diarization outputs as conditioning information and, with minimal fine-tuning, demonstrated strong multilingual and multi-domain performance. In this paper, we address a key limitation of DiCoW: ambiguity in Silence-Target-Non-target-Overlap (STNO) masks, where two or more fully overlapping speakers may have nearly identical conditioning despite differing transcriptions. We introduce SE-DiCoW (Self-Enrolled Diarization-Conditioned Whisper), which uses diarization output to locate an enrollment segment anywhere in the conversation where the target speaker is most active. This enrollment segment is used as fixed conditioning via cross-attention at each encoder layer. We further refine DiCoW with improved data segmentation, model initialization, and augmentation. Together, these advances yield substantial gains: SE-DiCoW reduces macro-averaged tcpWER by 52.4% relative to the original DiCoW on the EMMA MT-ASR benchmark.
WST: Weakly Supervised Transducer for Automatic Speech Recognition
Nov 06, 2025The Recurrent Neural Network-Transducer (RNN-T) is widely adopted in end-to-end (E2E) automatic speech recognition (ASR) tasks but depends heavily on large-scale, high-quality annotated data, which are often costly and difficult to obtain. To mitigate this reliance, we propose a Weakly Supervised Transducer (WST), which integrates a flexible training graph designed to robustly handle errors in the transcripts without requiring additional confidence estimation or auxiliary pre-trained models. Empirical evaluations on synthetic and industrial datasets reveal that WST effectively maintains performance even with transcription error rates of up to 70%, consistently outperforming existing Connectionist Temporal Classification (CTC)-based weakly supervised approaches, such as Bypass Temporal Classification (BTC) and Omni-Temporal Classification (OTC). These results demonstrate the practical utility and robustness of WST in realistic ASR settings. The implementation will be publicly available.
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Scalable Controllable Accented TTS
Aug 10, 2025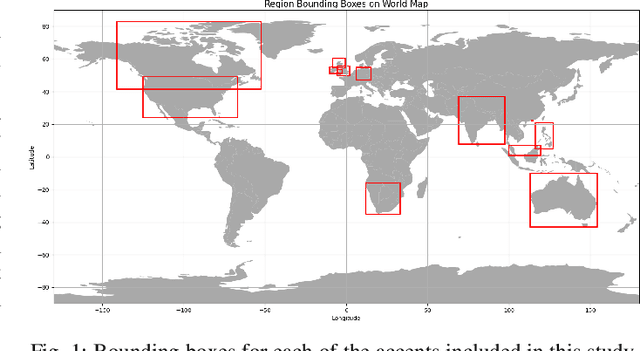
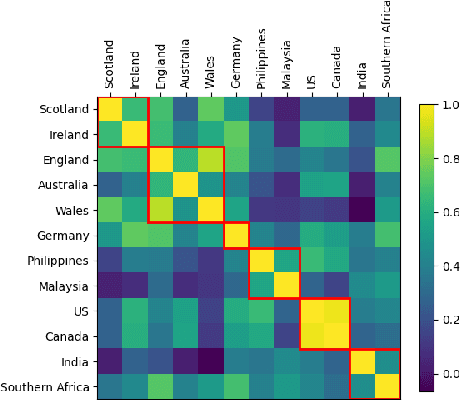
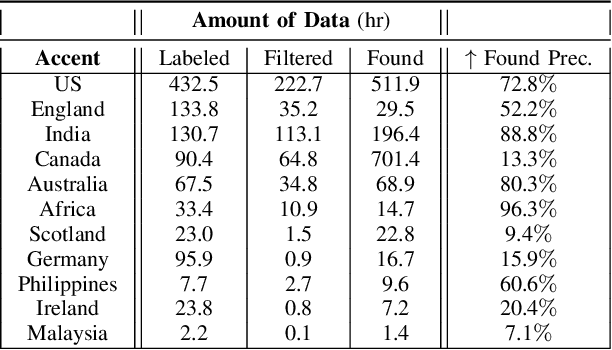

We tackle the challenge of scaling accented TTS systems, expanding their capabilities to include much larger amounts of training data and a wider variety of accent labels, even for accents that are poorly represented or unlabeled in traditional TTS datasets. To achieve this, we employ two strategies: 1. Accent label discovery via a speech geolocation model, which automatically infers accent labels from raw speech data without relying solely on human annotation; 2. Timbre augmentation through kNN voice conversion to increase data diversity and model robustness. These strategies are validated on CommonVoice, where we fine-tune XTTS-v2 for accented TTS with accent labels discovered or enhanced using geolocation. We demonstrate that the resulting accented TTS model not only outperforms XTTS-v2 fine-tuned on self-reported accent labels in CommonVoice, but also existing accented TTS benchmarks.
Enhancing Dialogue Annotation with Speaker Characteristics Leveraging a Frozen LLM
Aug 06, 2025In dialogue transcription pipelines, Large Language Models (LLMs) are frequently employed in post-processing to improve grammar, punctuation, and readability. We explore a complementary post-processing step: enriching transcribed dialogues by adding metadata tags for speaker characteristics such as age, gender, and emotion. Some of the tags are global to the entire dialogue, while some are time-variant. Our approach couples frozen audio foundation models, such as Whisper or WavLM, with a frozen LLAMA language model to infer these speaker attributes, without requiring task-specific fine-tuning of either model. Using lightweight, efficient connectors to bridge audio and language representations, we achieve competitive performance on speaker profiling tasks while preserving modularity and speed. Additionally, we demonstrate that a frozen LLAMA model can compare x-vectors directly, achieving an Equal Error Rate of 8.8% in some scenarios.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025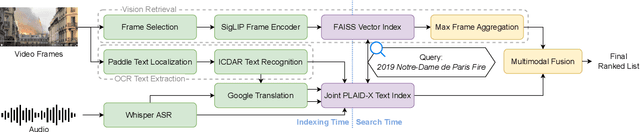


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.