 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Arithmetic with Support Languages for Low-Resource ASR
Jan 11, 2026The development of resource-constrained approaches to automatic speech recognition (ASR) is of great interest due to its broad applicability to many low-resource languages for which there is scant usable data. Existing approaches to many low-resource natural language processing tasks leverage additional data from higher-resource languages that are closely related to a target low-resource language. One increasingly popular approach uses task arithmetic to combine models trained on different tasks to create a model for a task where there is little to no training data. In this paper, we consider training on a particular language to be a task, and we generate task vectors by fine-tuning variants of the Whisper ASR system. For pairings of high- and low-resource languages, we merge task vectors via a linear combination, optimizing the weights of the linear combination on the downstream word error rate on the low-resource target language's validation set. We find that this approach consistently improves performance on the target languages.
GIFT: Gradient-aware Immunization of diffusion models against malicious Fine-Tuning with safe concepts retention
Jul 18, 2025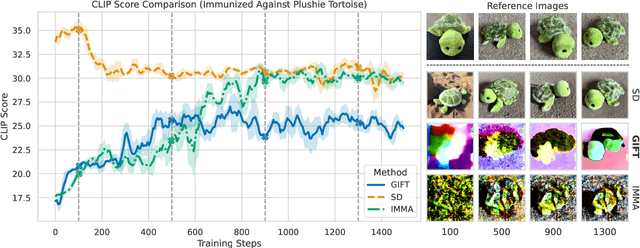
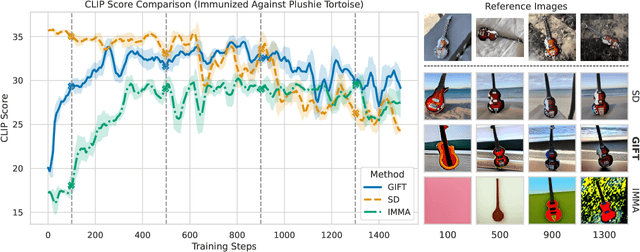
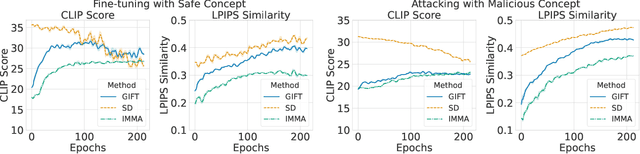
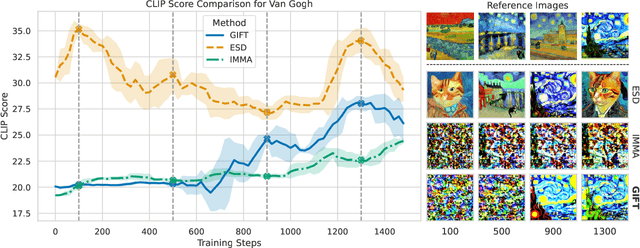
We present GIFT: a {G}radient-aware {I}mmunization technique to defend diffusion models against malicious {F}ine-{T}uning while preserving their ability to generate safe content. Existing safety mechanisms like safety checkers are easily bypassed, and concept erasure methods fail under adversarial fine-tuning. GIFT addresses this by framing immunization as a bi-level optimization problem: the upper-level objective degrades the model's ability to represent harmful concepts using representation noising and maximization, while the lower-level objective preserves performance on safe data. GIFT achieves robust resistance to malicious fine-tuning while maintaining safe generative quality. Experimental results show that our method significantly impairs the model's ability to re-learn harmful concepts while maintaining performance on safe content, offering a promising direction for creating inherently safer generative models resistant to adversarial fine-tuning attacks.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025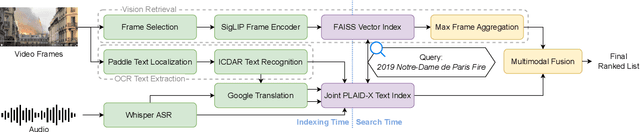


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
CAMeMBERT: Cascading Assistant-Mediated Multilingual BERT
Dec 22, 2022Large language models having hundreds of millions, and even billions, of parameters have performed extremely well on a variety of natural language processing (NLP) tasks. Their widespread use and adoption, however, is hindered by the lack of availability and portability of sufficiently large computational resources. This paper proposes a knowledge distillation (KD) technique building on the work of LightMBERT, a student model of multilingual BERT (mBERT). By repeatedly distilling mBERT through increasingly compressed toplayer distilled teacher assistant networks, CAMeMBERT aims to improve upon the time and space complexities of mBERT while keeping loss of accuracy beneath an acceptable threshold. At present, CAMeMBERT has an average accuracy of around 60.1%, which is subject to change after future improvements to the hyperparameters used in fine-tuning.