 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColBERTSaR: Sparsified ColBERT Index via Product Quantization
Jun 04, 2026While ColBERT is an effective neural retrieval architecture, it requires a heavy index structure to support candidate set retrieval based on approximated token embeddings, gathering and decompressing document token embeddings, and applying the MaxSim operation. Indexes in PLAID and similar ColBERT implementations require five to ten times the disk storage of the original raw text, which limits their scalability. Furthermore, prior work has identified that the gathering and decompression stages are the primary inefficiencies at query time. Limiting the number of document tokens that must be gathered by thresholding and score approximation does not eliminate the need for the entire index to support ad hoc queries. In this work, we propose an embedding quantization approach that turns a ColBERT index into a true inverted index. We show that, theoretically, ColBERT with embedding quantization is equivalent to learned-sparse retrieval except for the scoring mechanism. Empirically, we demonstrate that our index is 50-70% smaller than a one-bit PLAID index while retaining retrieval effectiveness.
CoverageBench: Evaluating Information Coverage across Tasks and Domains
Mar 20, 2026We wish to measure the information coverage of an ad hoc retrieval algorithm, that is, how much of the range of available relevant information is covered by the search results. Information coverage is a central aspect for retrieval, especially when the retrieval system is integrated with generative models in a retrieval-augmented generation (RAG) system. The classic metrics for ad hoc retrieval, precision and recall, reward a system as more and more relevant documents are retrieved. However, since relevance in ad hoc test collections is defined for a document without any relation to other documents that might contain the same information, high recall is sufficient but not necessary to ensure coverage. The same is true for other metrics such as rank-biased precision (RBP), normalized discounted cumulative gain (nDCG), and mean average precision (MAP). Test collections developed around the notion of diversity ranking in web search incorporate multiple aspects that support a concept of coverage in the web domain. In this work, we construct a suite of collections for evaluating information coverage from existing collections. This suite offers researchers a unified testbed spanning multiple genres and tasks. All topics, nuggets, relevance labels, and baseline rankings are released on Hugging Face Datasets, along with instructions for accessing the publicly available document collections.
Does Reasoning Make Search More Fair? Comparing Fairness in Reasoning and Non-Reasoning Rerankers
Mar 11, 2026While reasoning rerankers, such as Rank1, have demonstrated strong abilities in improving ranking relevance, it is unclear how they perform on other retrieval qualities such as fairness. We conduct the first systematic comparison of fairness between reasoning and non-reasoning rerankers. Using the TREC 2022 Fair Ranking Track dataset, we evaluate six reranking models across multiple retrieval settings and demographic attributes. Our findings demonstrate reasoning neither improve nor harm fairness compared to non-reasoning approaches. Our fairness metric, Attention-Weighted Rank Fairness (AWRF) remained stable (0.33-0.35) across all models, even as relevance varies substantially (nDCG 0.247-1.000). Demographic breakdown analysis revealed fairness gaps for geographic attributes regardless of model architecture. These results indicate that future work in specializing reasoning models to be aware of fairness attributes could lead to improvements, as current implementations preserve the fairness characteristics of their input ranking.
Beyond Relevance: On the Relationship Between Retrieval and RAG Information Coverage
Mar 11, 2026Retrieval-augmented generation (RAG) systems combine document retrieval with a generative model to address complex information seeking tasks like report generation. While the relationship between retrieval quality and generation effectiveness seems intuitive, it has not been systematically studied. We investigate whether upstream retrieval metrics can serve as reliable early indicators of the final generated response's information coverage. Through experiments across two text RAG benchmarks (TREC NeuCLIR 2024 and TREC RAG 2024) and one multimodal benchmark (WikiVideo), we analyze 15 text retrieval stacks and 10 multimodal retrieval stacks across four RAG pipelines and multiple evaluation frameworks (Auto-ARGUE and MiRAGE). Our findings demonstrate strong correlations between coverage-based retrieval metrics and nugget coverage in generated responses at both topic and system levels. This relationship holds most strongly when retrieval objectives align with generation goals, though more complex iterative RAG pipelines can partially decouple generation quality from retrieval effectiveness. These findings provide empirical support for using retrieval metrics as proxies for RAG performance.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025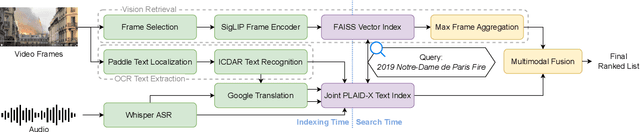


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
Prompts as Auto-Optimized Training Hyperparameters: Training Best-in-Class IR Models from Scratch with 10 Gold Labels
Jun 17, 2024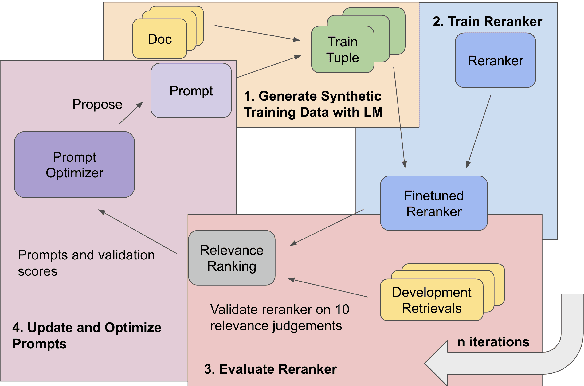
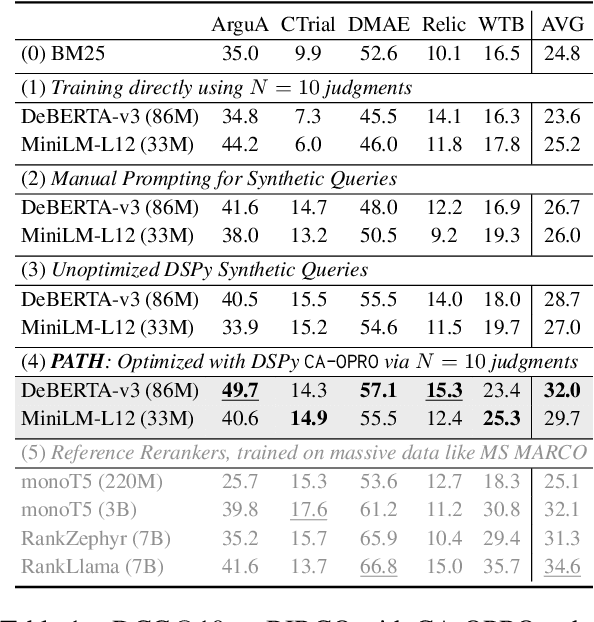
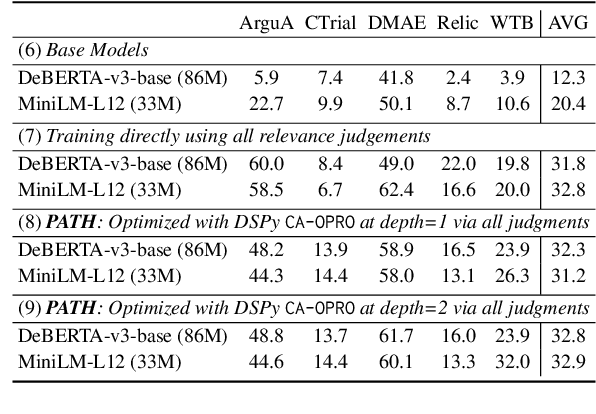

We develop a method for training small-scale (under 100M parameter) neural information retrieval models with as few as 10 gold relevance labels. The method depends on generating synthetic queries for documents using a language model (LM), and the key step is that we automatically optimize the LM prompt that is used to generate these queries based on training quality. In experiments with the BIRCO benchmark, we find that models trained with our method outperform RankZephyr and are competitive with RankLLama, both of which are 7B parameter models trained on over 100K labels. These findings point to the power of automatic prompt optimization for synthetic dataset generation.