 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriScience-MT: Towards Decolonizing Science in Africa through Text Translation
May 28, 2026The dominance of colonial languages in African education and scientific communication limits how hundreds of millions of speakers of African languages access and produce scientific knowledge. A core obstacle is the lack of established scientific terminology in these languages. We introduce AfriScience-MT, a parallel corpus covering six African languages (Amharic, Hausa, Luganda, Northern Sotho, Yorùbá, and isiZulu) across 11 scientific domains. Professional translators, working with expert science communicators, translated plain-language summaries of scientific papers into each target language and created new terms where none existed. We benchmark machine translation systems and large language models in zero-shot, few-shot, and fine-tuned settings. Our results show that closed-source models outperform all open-source models at both the sentence and document levels: GPT-5.4 and Gemini-3.1-Flash-Lite lead with average sentence-level COMET scores of 68.3 and 68.0, respectively, and tie at an average document-level COMET of 48.3. Among open systems, fine-tuned NLLB-1.3B reaches 67.3 at the sentence level, and TranslateGemma-12B reaches 44.0 at the document level with 1-shot in-context learning. We release AfriScience-MT to support benchmarking and document-level scientific MT for African languages.
Temporal Simultaneity Predicts Annotation Quality in Sentiment Corpora
May 26, 2026Annotation quality is difficult to sustain when campaigns span weeks or months with small annotator pools. We present a Setswana sentiment dataset of 3,565 tweets annotated by three native-speaker annotators across eight batches and examine why inter-annotator agreement (IAA) declines over time. Despite an aggregate Randolph's free-marginal Kappa of $κ= 0.76$, "excellent," per-batch $κ$ falls by more than 32 points across the annotation task. Through six targeted analyses, we find that (i) label confusion concentrates on the negative/neutral boundary, (ii) two annotators show run-length drift consistent with autopilot labeling, and (iii) the dominant predictor of $κ$ is temporal simultaneity: tweets labeled within one minute achieve $κ= 0.98$, while those labeled more than a day apart reach only $κ= 0.65$. Annotation speed and tweet-level linguistic features show no meaningful association with $κ$. We benchmark three open multilingual encoders and proprietary models (GPT-5 and Gemini) on three-class sentiment classification; fine-tuning yields gains of 29 to 43 macro-F1 points over pretrained baselines, with GPT-5 few-shot leading overall (62.2 macro-F1). We release the dataset, per-annotation timestamps, and analysis code to support reproducible quality auditing for future African language NLP resources.
The Annotation Scarcity Paradox in Low-Resource NLP Evaluation: A Decade of Acceleration and Emerging Constraints
May 18, 2026Over the past decade, low-resource natural language processing (NLP) has experienced explosive growth, propelled by cross-lingual transfer, massively multilingual models, and the rapid proliferation of benchmarks. Yet this apparent progress masks a critical, insufficiently examined tension: the deep sociolinguistic expertise required to evaluate increasingly complex generative systems is severely strained, inequitably distributed, and structurally marginalised. We present a critical narrative survey of low-resource NLP evaluation (2014--present), tracing its evolution across three phases: early heuristic optimism, the illusions of top-down benchmark scaling, and the current era of generative bottlenecks. We conceptualise the \emph{Annotation Scarcity Paradox}, the structural friction arising when the technical capacity to scale models vastly outpaces the sovereign human infrastructure required to authentically evaluate them. By examining extractive data pipelines, undercompensated ``ghost work'', and language data flaring, we argue that this paradox threatens the epistemic validity of reported progress. We survey emerging responses -- including data augmentation, model-based evaluation, participatory curation, and annotation-efficient approaches via item response theory and active learning -- and assess their equity and validity trade-offs. We close with a practitioner call to action, arguing that overcoming this bottleneck requires a paradigm shift from transactional data extraction to relational, community-embedded evaluation rooted in epistemic governance, data sovereignty, and shared ownership.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
HausaNLP: Current Status, Challenges and Future Directions for Hausa Natural Language Processing
May 20, 2025Hausa Natural Language Processing (NLP) has gained increasing attention in recent years, yet remains understudied as a low-resource language despite having over 120 million first-language (L1) and 80 million second-language (L2) speakers worldwide. While significant advances have been made in high-resource languages, Hausa NLP faces persistent challenges, including limited open-source datasets and inadequate model representation. This paper presents an overview of the current state of Hausa NLP, systematically examining existing resources, research contributions, and gaps across fundamental NLP tasks: text classification, machine translation, named entity recognition, speech recognition, and question answering. We introduce HausaNLP (https://catalog.hausanlp.org), a curated catalog that aggregates datasets, tools, and research works to enhance accessibility and drive further development. Furthermore, we discuss challenges in integrating Hausa into large language models (LLMs), addressing issues of suboptimal tokenization and dialectal variation. Finally, we propose strategic research directions emphasizing dataset expansion, improved language modeling approaches, and strengthened community collaboration to advance Hausa NLP. Our work provides both a foundation for accelerating Hausa NLP progress and valuable insights for broader multilingual NLP research.
HausaNLP at SemEval-2025 Task 2: Entity-Aware Fine-tuning vs. Prompt Engineering in Entity-Aware Machine Translation
Mar 25, 2025


This paper presents our findings for SemEval 2025 Task 2, a shared task on entity-aware machine translation (EA-MT). The goal of this task is to develop translation models that can accurately translate English sentences into target languages, with a particular focus on handling named entities, which often pose challenges for MT systems. The task covers 10 target languages with English as the source. In this paper, we describe the different systems we employed, detail our results, and discuss insights gained from our experiments.
AfroXLMR-Comet: Multilingual Knowledge Distillation with Attention Matching for Low-Resource languages
Feb 25, 2025



Language model compression through knowledge distillation has emerged as a promising approach for deploying large language models in resource-constrained environments. However, existing methods often struggle to maintain performance when distilling multilingual models, especially for low-resource languages. In this paper, we present a novel hybrid distillation approach that combines traditional knowledge distillation with a simplified attention matching mechanism, specifically designed for multilingual contexts. Our method introduces an extremely compact student model architecture, significantly smaller than conventional multilingual models. We evaluate our approach on five African languages: Kinyarwanda, Swahili, Hausa, Igbo, and Yoruba. The distilled student model; AfroXLMR-Comet successfully captures both the output distribution and internal attention patterns of a larger teacher model (AfroXLMR-Large) while reducing the model size by over 85%. Experimental results demonstrate that our hybrid approach achieves competitive performance compared to the teacher model, maintaining an accuracy within 85% of the original model's performance while requiring substantially fewer computational resources. Our work provides a practical framework for deploying efficient multilingual models in resource-constrained environments, particularly benefiting applications involving African languages.
MAGE: Multi-Head Attention Guided Embeddings for Low Resource Sentiment Classification
Feb 25, 2025
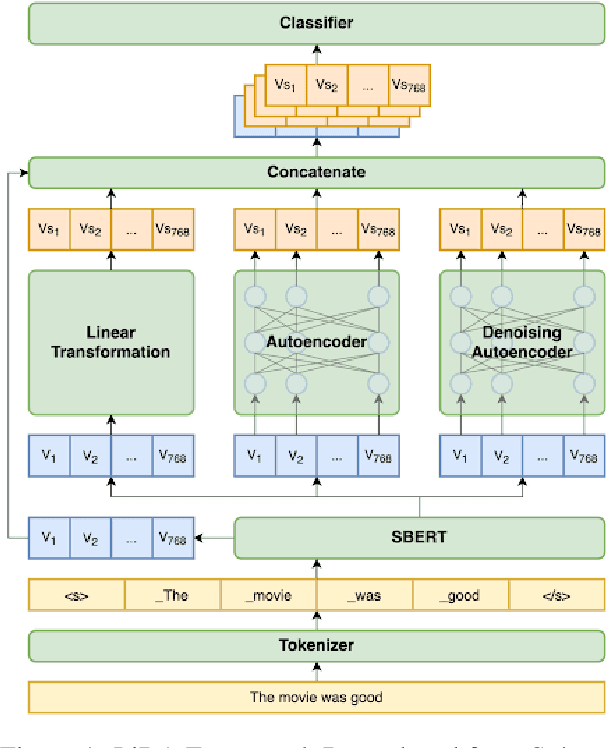
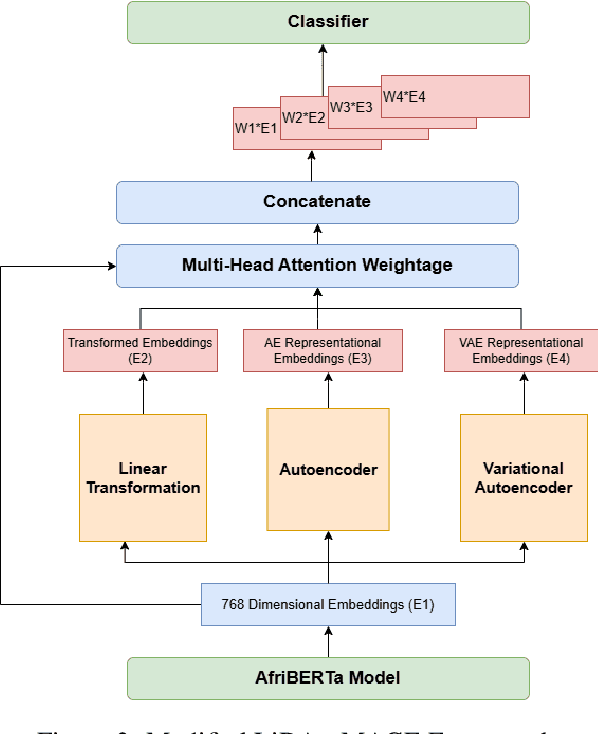

Due to the lack of quality data for low-resource Bantu languages, significant challenges are presented in text classification and other practical implementations. In this paper, we introduce an advanced model combining Language-Independent Data Augmentation (LiDA) with Multi-Head Attention based weighted embeddings to selectively enhance critical data points and improve text classification performance. This integration allows us to create robust data augmentation strategies that are effective across various linguistic contexts, ensuring that our model can handle the unique syntactic and semantic features of Bantu languages. This approach not only addresses the data scarcity issue but also sets a foundation for future research in low-resource language processing and classification tasks.
The Esethu Framework: Reimagining Sustainable Dataset Governance and Curation for Low-Resource Languages
Feb 21, 2025

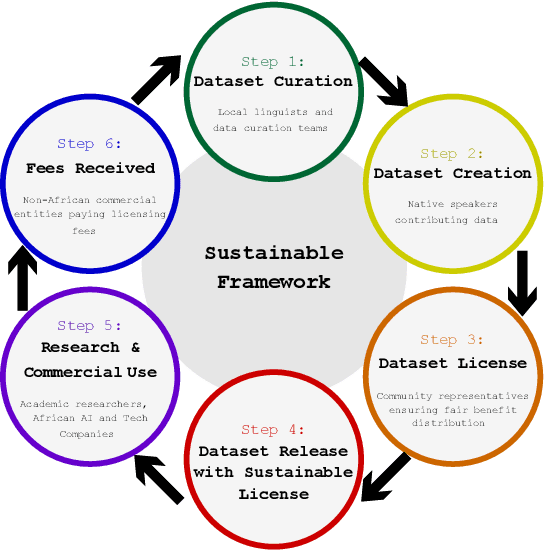

This paper presents the Esethu Framework, a sustainable data curation framework specifically designed to empower local communities and ensure equitable benefit-sharing from their linguistic resources. This framework is supported by the Esethu license, a novel community-centric data license. As a proof of concept, we introduce the Vuk'uzenzele isiXhosa Speech Dataset (ViXSD), an open-source corpus developed under the Esethu Framework and License. The dataset, containing read speech from native isiXhosa speakers enriched with demographic and linguistic metadata, demonstrates how community-driven licensing and curation principles can bridge resource gaps in automatic speech recognition (ASR) for African languages while safeguarding the interests of data creators. We describe the framework guiding dataset development, outline the Esethu license provisions, present the methodology for ViXSD, and present ASR experiments validating ViXSD's usability in building and refining voice-driven applications for isiXhosa.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.