 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUSION: Frequency-guided Underwater Spatial Image recOnstructioN
Apr 01, 2025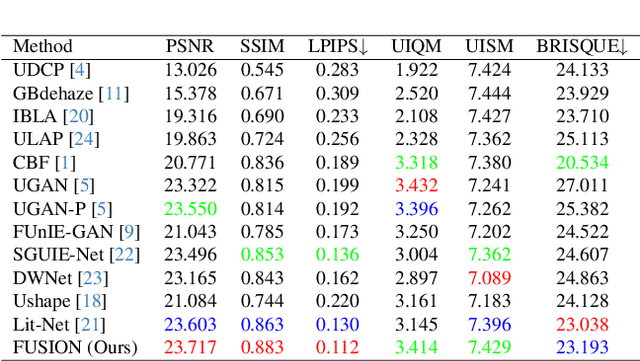
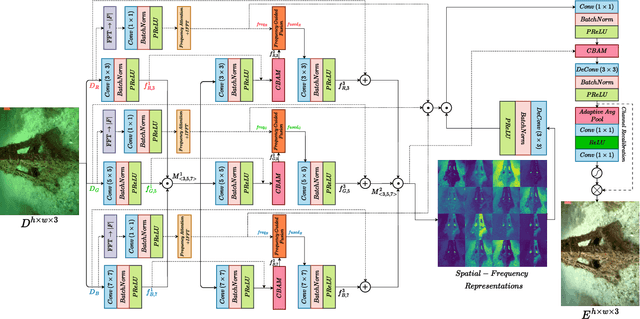
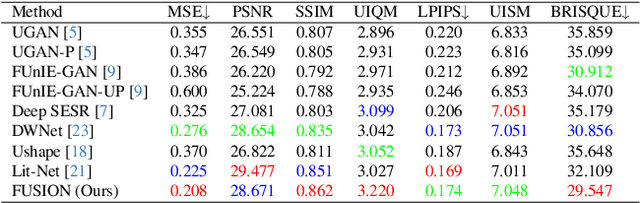
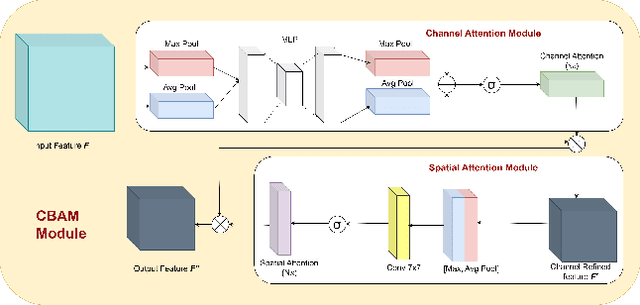
Underwater images suffer from severe degradations, including color distortions, reduced visibility, and loss of structural details due to wavelength-dependent attenuation and scattering. Existing enhancement methods primarily focus on spatial-domain processing, neglecting the frequency domain's potential to capture global color distributions and long-range dependencies. To address these limitations, we propose FUSION, a dual-domain deep learning framework that jointly leverages spatial and frequency domain information. FUSION independently processes each RGB channel through multi-scale convolutional kernels and adaptive attention mechanisms in the spatial domain, while simultaneously extracting global structural information via FFT-based frequency attention. A Frequency Guided Fusion module integrates complementary features from both domains, followed by inter-channel fusion and adaptive channel recalibration to ensure balanced color distributions. Extensive experiments on benchmark datasets (UIEB, EUVP, SUIM-E) demonstrate that FUSION achieves state-of-the-art performance, consistently outperforming existing methods in reconstruction fidelity (highest PSNR of 23.717 dB and SSIM of 0.883 on UIEB), perceptual quality (lowest LPIPS of 0.112 on UIEB), and visual enhancement metrics (best UIQM of 3.414 on UIEB), while requiring significantly fewer parameters (0.28M) and lower computational complexity, demonstrating its suitability for real-time underwater imaging applications.
TactStyle: Generating Tactile Textures with Generative AI for Digital Fabrication
Mar 03, 2025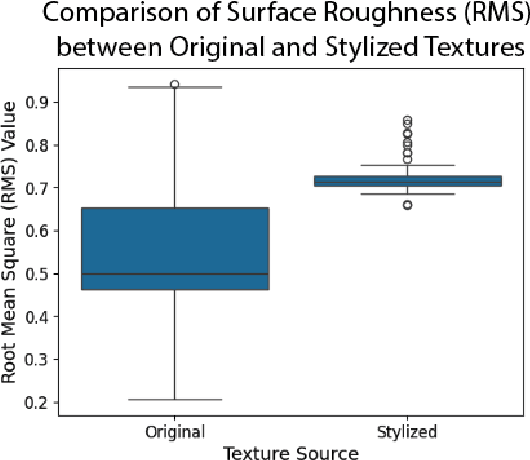
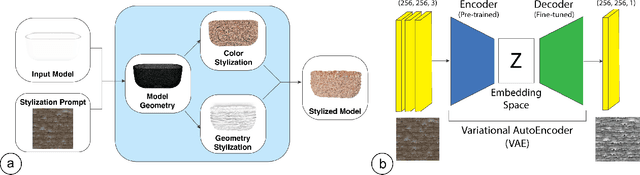
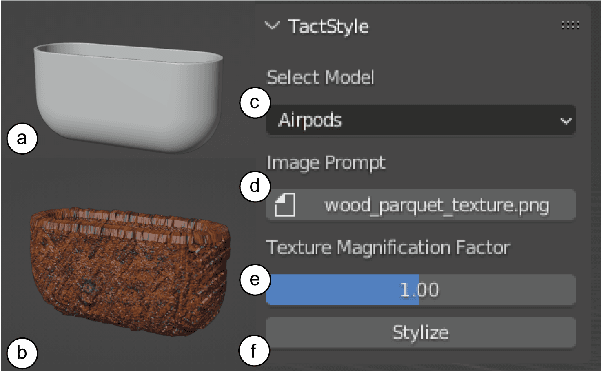
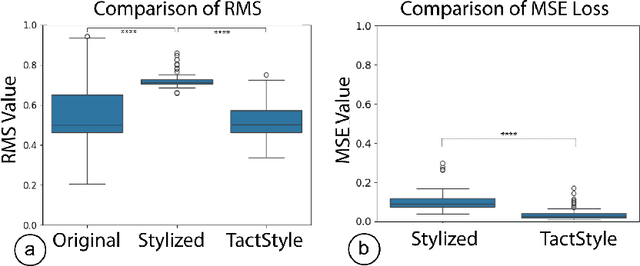
Recent work in Generative AI enables the stylization of 3D models based on image prompts. However, these methods do not incorporate tactile information, leading to designs that lack the expected tactile properties. We present TactStyle, a system that allows creators to stylize 3D models with images while incorporating the expected tactile properties. TactStyle accomplishes this using a modified image-generation model fine-tuned to generate heightfields for given surface textures. By optimizing 3D model surfaces to embody a generated texture, TactStyle creates models that match the desired style and replicate the tactile experience. We utilize a large-scale dataset of textures to train our texture generation model. In a psychophysical experiment, we evaluate the tactile qualities of a set of 3D-printed original textures and TactStyle's generated textures. Our results show that TactStyle successfully generates a wide range of tactile features from a single image input, enabling a novel approach to haptic design.
AfroXLMR-Comet: Multilingual Knowledge Distillation with Attention Matching for Low-Resource languages
Feb 25, 2025



Language model compression through knowledge distillation has emerged as a promising approach for deploying large language models in resource-constrained environments. However, existing methods often struggle to maintain performance when distilling multilingual models, especially for low-resource languages. In this paper, we present a novel hybrid distillation approach that combines traditional knowledge distillation with a simplified attention matching mechanism, specifically designed for multilingual contexts. Our method introduces an extremely compact student model architecture, significantly smaller than conventional multilingual models. We evaluate our approach on five African languages: Kinyarwanda, Swahili, Hausa, Igbo, and Yoruba. The distilled student model; AfroXLMR-Comet successfully captures both the output distribution and internal attention patterns of a larger teacher model (AfroXLMR-Large) while reducing the model size by over 85%. Experimental results demonstrate that our hybrid approach achieves competitive performance compared to the teacher model, maintaining an accuracy within 85% of the original model's performance while requiring substantially fewer computational resources. Our work provides a practical framework for deploying efficient multilingual models in resource-constrained environments, particularly benefiting applications involving African languages.
MAGE: Multi-Head Attention Guided Embeddings for Low Resource Sentiment Classification
Feb 25, 2025
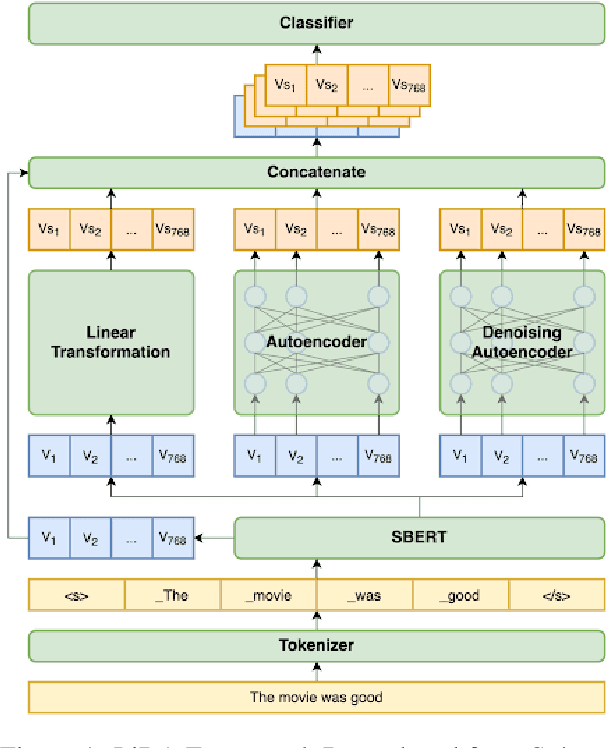
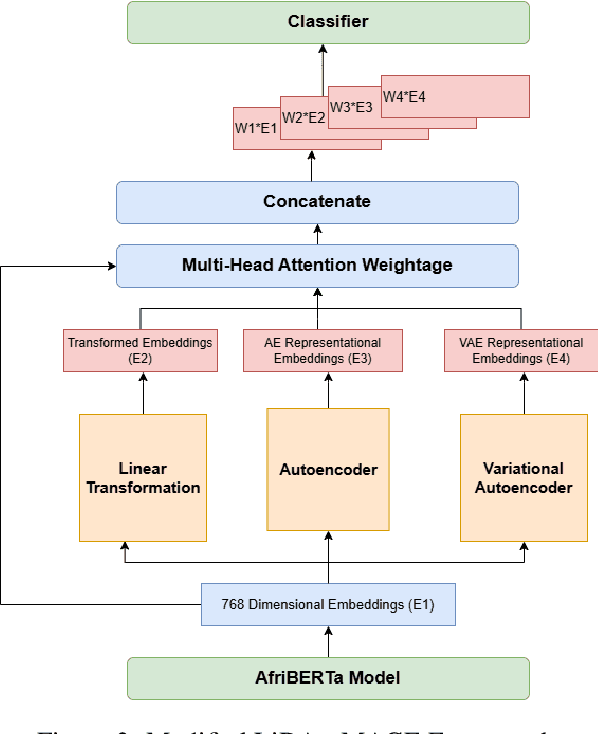

Due to the lack of quality data for low-resource Bantu languages, significant challenges are presented in text classification and other practical implementations. In this paper, we introduce an advanced model combining Language-Independent Data Augmentation (LiDA) with Multi-Head Attention based weighted embeddings to selectively enhance critical data points and improve text classification performance. This integration allows us to create robust data augmentation strategies that are effective across various linguistic contexts, ensuring that our model can handle the unique syntactic and semantic features of Bantu languages. This approach not only addresses the data scarcity issue but also sets a foundation for future research in low-resource language processing and classification tasks.
Predicting Liquidity-Aware Bond Yields using Causal GANs and Deep Reinforcement Learning with LLM Evaluation
Feb 24, 2025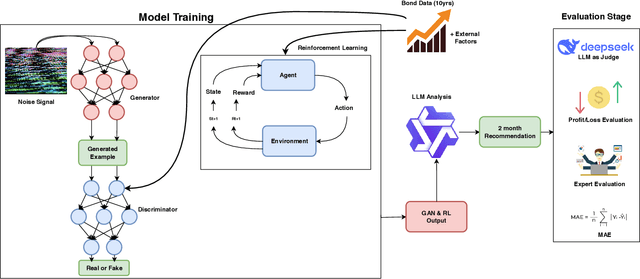
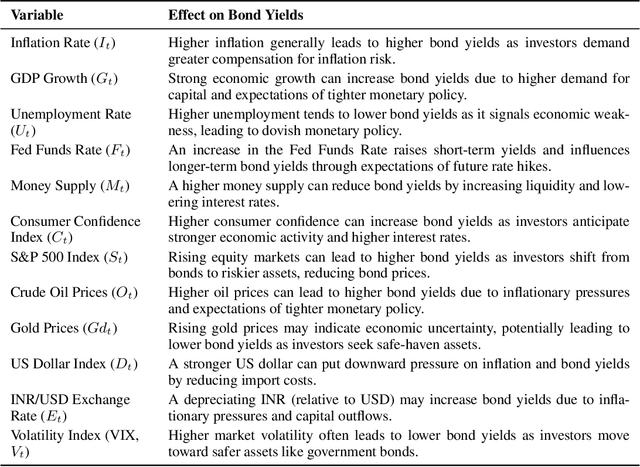
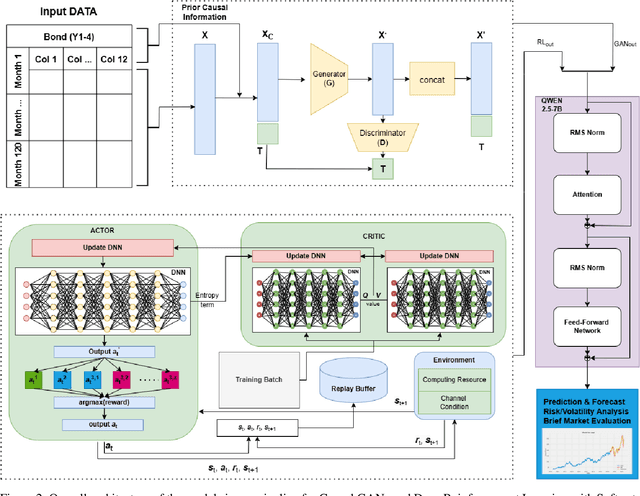

Financial bond yield forecasting is challenging due to data scarcity, nonlinear macroeconomic dependencies, and evolving market conditions. In this paper, we propose a novel framework that leverages Causal Generative Adversarial Networks (CausalGANs) and Soft Actor-Critic (SAC) reinforcement learning (RL) to generate high-fidelity synthetic bond yield data for four major bond categories (AAA, BAA, US10Y, Junk). By incorporating 12 key macroeconomic variables, we ensure statistical fidelity by preserving essential market properties. To transform this market dependent synthetic data into actionable insights, we employ a finetuned Large Language Model (LLM) Qwen2.5-7B that generates trading signals (BUY/HOLD/SELL), risk assessments, and volatility projections. We use automated, human and LLM evaluations, all of which demonstrate that our framework improves forecasting performance over existing methods, with statistical validation via predictive accuracy, MAE evaluation(0.103%), profit/loss evaluation (60% profit rate), LLM evaluation (3.37/5) and expert assessments scoring 4.67 out of 5. The reinforcement learning-enhanced synthetic data generation achieves the least Mean Absolute Error of 0.103, demonstrating its effectiveness in replicating real-world bond market dynamics. We not only enhance data-driven trading strategies but also provides a scalable, high-fidelity synthetic financial data pipeline for risk & volatility management and investment decision-making. This work establishes a bridge between synthetic data generation, LLM driven financial forecasting, and language model evaluation, contributing to AI-driven financial decision-making.
SAG-ViT: A Scale-Aware, High-Fidelity Patching Approach with Graph Attention for Vision Transformers
Nov 14, 2024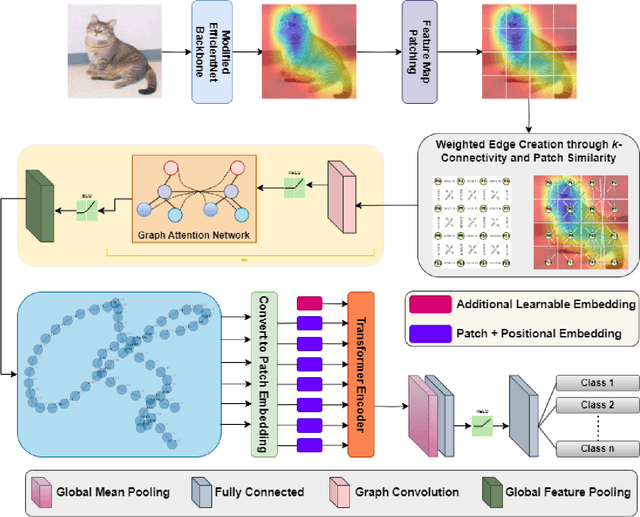

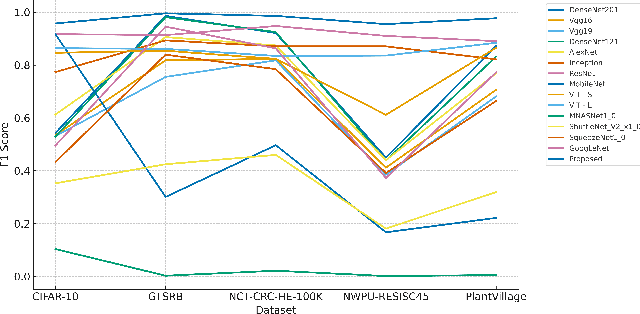
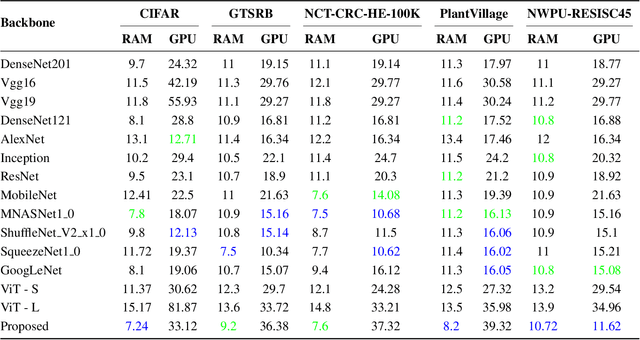
Image classification is a computer vision task where a model analyzes an image to categorize it into a specific label. Vision Transformers (ViT) improve this task by leveraging self-attention to capture complex patterns and long range relationships between image patches. However, a key challenge for ViTs is efficiently incorporating multiscale feature representations, which is inherent in CNNs through their hierarchical structure. In this paper, we introduce the Scale-Aware Graph Attention Vision Transformer (SAG-ViT), a novel framework that addresses this challenge by integrating multi-scale features. Using EfficientNet as a backbone, the model extracts multi-scale feature maps, which are divided into patches to preserve semantic information. These patches are organized into a graph based on spatial and feature similarities, with a Graph Attention Network (GAT) refining the node embeddings. Finally, a Transformer encoder captures long-range dependencies and complex interactions. The SAG-ViT is evaluated on benchmark datasets, demonstrating its effectiveness in enhancing image classification performance.
Cross-lingual transfer of multilingual models on low resource African Languages
Sep 17, 2024



Large multilingual models have significantly advanced natural language processing (NLP) research. However, their high resource demands and potential biases from diverse data sources have raised concerns about their effectiveness across low-resource languages. In contrast, monolingual models, trained on a single language, may better capture the nuances of the target language, potentially providing more accurate results. This study benchmarks the cross-lingual transfer capabilities from a high-resource language to a low-resource language for both, monolingual and multilingual models, focusing on Kinyarwanda and Kirundi, two Bantu languages. We evaluate the performance of transformer based architectures like Multilingual BERT (mBERT), AfriBERT, and BantuBERTa against neural-based architectures such as BiGRU, CNN, and char-CNN. The models were trained on Kinyarwanda and tested on Kirundi, with fine-tuning applied to assess the extent of performance improvement and catastrophic forgetting. AfriBERT achieved the highest cross-lingual accuracy of 88.3% after fine-tuning, while BiGRU emerged as the best-performing neural model with 83.3% accuracy. We also analyze the degree of forgetting in the original language post-fine-tuning. While monolingual models remain competitive, this study highlights that multilingual models offer strong cross-lingual transfer capabilities in resource limited settings.
Deep Learning Innovations for Underwater Waste Detection: An In-Depth Analysis
May 28, 2024


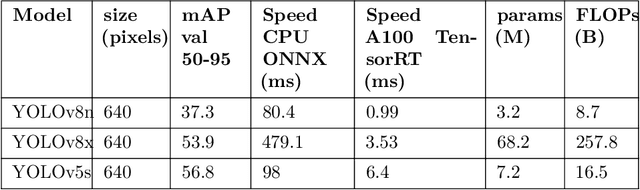
Addressing the issue of submerged underwater trash is crucial for safeguarding aquatic ecosystems and preserving marine life. While identifying debris present on the surface of water bodies is straightforward, assessing the underwater submerged waste is a challenge due to the image distortions caused by factors such as light refraction, absorption, suspended particles, color shifts, and occlusion. This paper conducts a comprehensive review of state-of-the-art architectures and on the existing datasets to establish a baseline for submerged waste and trash detection. The primary goal remains to establish the benchmark of the object localization techniques to be leveraged by advanced underwater sensors and autonomous underwater vehicles. The ultimate objective is to explore the underwater environment, to identify, and remove underwater debris. The absence of benchmarks (dataset or algorithm) in many researches emphasizes the need for a more robust algorithmic solution. Through this research, we aim to give performance comparative analysis of various underwater trash detection algorithms.
Optimized Custom Dataset for Efficient Detection of Underwater Trash
May 25, 2023Accurately quantifying and removing submerged underwater waste plays a crucial role in safeguarding marine life and preserving the environment. While detecting floating and surface debris is relatively straightforward, quantifying submerged waste presents significant challenges due to factors like light refraction, absorption, suspended particles, and color distortion. This paper addresses these challenges by proposing the development of a custom dataset and an efficient detection approach for submerged marine debris. The dataset encompasses diverse underwater environments and incorporates annotations for precise labeling of debris instances. Ultimately, the primary objective of this custom dataset is to enhance the diversity of litter instances and improve their detection accuracy in deep submerged environments by leveraging state-of-the-art deep learning architectures.
ECG Classification System for Arrhythmia Detection Using Convolutional Neural Networks
Mar 07, 2023
Arrhythmia is just one of the many cardiovascular illnesses that have been extensively studied throughout the years. Using a multi-lead ECG data, this research describes a deep learning (DL) technique based on a convolutional neural network (CNN) algorithm to detect cardiovascular arrhythmia in patients. The suggested CNN model has six layers total, two convolution layers, two pooling layers, and two fully linked layers within a residual block, in addition to the input and output layers. In this study, the classification of the ECG signals into five groups, Left Bundle Branch Block (LBBB), Right Bundle Branch Block (RBBB), Atrial Premature Contraction (APC), Premature Ventricular Contraction (PVC), and Normal Beat is the main goal (N). Using the MIT-BIH arrhythmia dataset, we assessed the suggested technique. The findings show that our suggested strategy classified 15000 cases with an average accuracy of 98.2%.