 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAG-ViT: A Scale-Aware, High-Fidelity Patching Approach with Graph Attention for Vision Transformers
Nov 14, 2024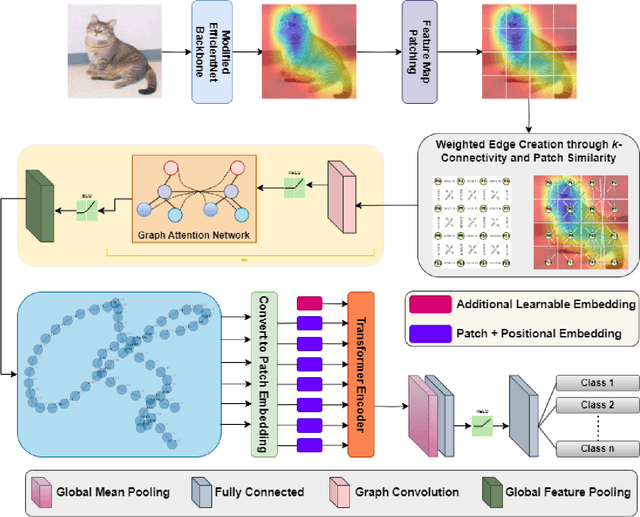

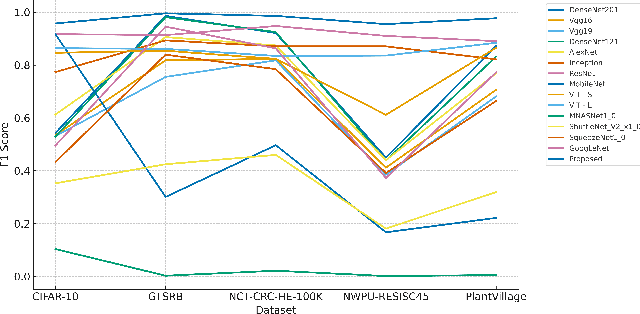
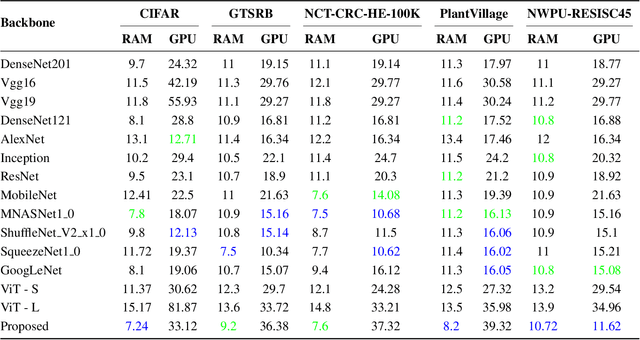
Image classification is a computer vision task where a model analyzes an image to categorize it into a specific label. Vision Transformers (ViT) improve this task by leveraging self-attention to capture complex patterns and long range relationships between image patches. However, a key challenge for ViTs is efficiently incorporating multiscale feature representations, which is inherent in CNNs through their hierarchical structure. In this paper, we introduce the Scale-Aware Graph Attention Vision Transformer (SAG-ViT), a novel framework that addresses this challenge by integrating multi-scale features. Using EfficientNet as a backbone, the model extracts multi-scale feature maps, which are divided into patches to preserve semantic information. These patches are organized into a graph based on spatial and feature similarities, with a Graph Attention Network (GAT) refining the node embeddings. Finally, a Transformer encoder captures long-range dependencies and complex interactions. The SAG-ViT is evaluated on benchmark datasets, demonstrating its effectiveness in enhancing image classification performance.
Enhancing Diabetic Retinopathy Detection with CNN-Based Models: A Comparative Study of UNET and Stacked UNET Architectures
Nov 02, 2024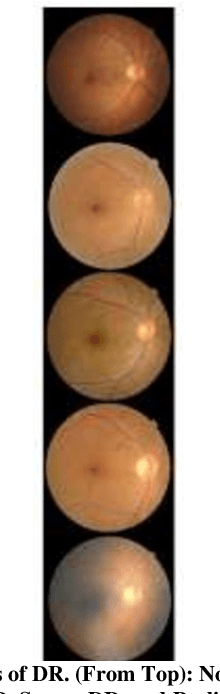
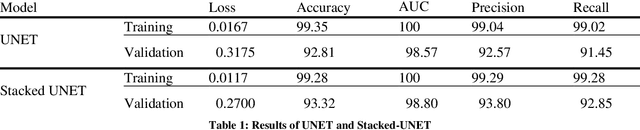
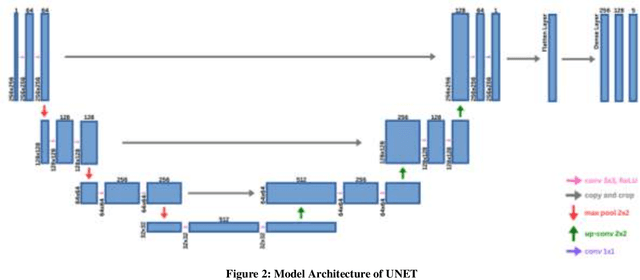
Diabetic Retinopathy DR is a severe complication of diabetes. Damaged or abnormal blood vessels can cause loss of vision. The need for massive screening of a large population of diabetic patients has generated an interest in a computer-aided fully automatic diagnosis of DR. In the realm of Deep learning frameworks, particularly convolutional neural networks CNNs, have shown great interest and promise in detecting DR by analyzing retinal images. However, several challenges have been faced in the application of deep learning in this domain. High-quality, annotated datasets are scarce, and the variations in image quality and class imbalances pose significant hurdles in developing a dependable model. In this paper, we demonstrate the proficiency of two Convolutional Neural Networks CNNs based models, UNET and Stacked UNET utilizing the APTOS Asia Pacific Tele-Ophthalmology Society Dataset. This system achieves an accuracy of 92.81% for the UNET and 93.32% for the stacked UNET architecture. The architecture classifies the images into five categories ranging from 0 to 4, where 0 is no DR and 4 is proliferative DR.
Multimodal Emotion Recognition using Audio-Video Transformer Fusion with Cross Attention
Jul 26, 2024Understanding emotions is a fundamental aspect of human communication. Integrating audio and video signals offers a more comprehensive understanding of emotional states compared to traditional methods that rely on a single data source, such as speech or facial expressions. Despite its potential, multimodal emotion recognition faces significant challenges, particularly in synchronization, feature extraction, and fusion of diverse data sources. To address these issues, this paper introduces a novel transformer-based model named Audio-Video Transformer Fusion with Cross Attention (AVT-CA). The AVT-CA model employs a transformer fusion approach to effectively capture and synchronize interlinked features from both audio and video inputs, thereby resolving synchronization problems. Additionally, the Cross Attention mechanism within AVT-CA selectively extracts and emphasizes critical features while discarding irrelevant ones from both modalities, addressing feature extraction and fusion challenges. Extensive experimental analysis conducted on the CMU-MOSEI, RAVDESS and CREMA-D datasets demonstrates the efficacy of the proposed model. The results underscore the importance of AVT-CA in developing precise and reliable multimodal emotion recognition systems for practical applications.