 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAG-ViT: A Scale-Aware, High-Fidelity Patching Approach with Graph Attention for Vision Transformers
Paper and Code
Nov 14, 2024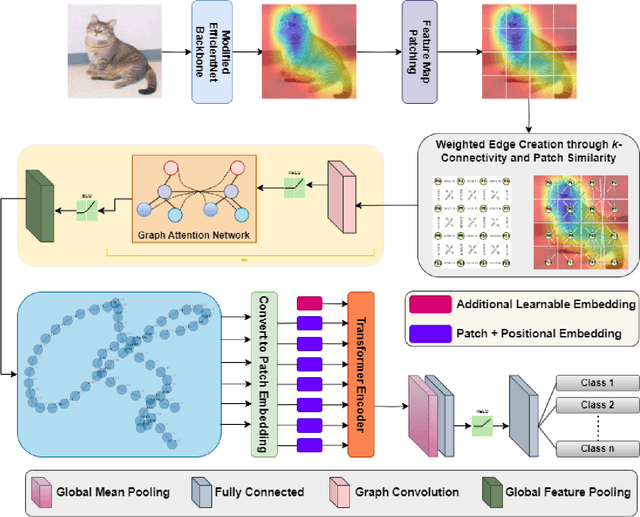

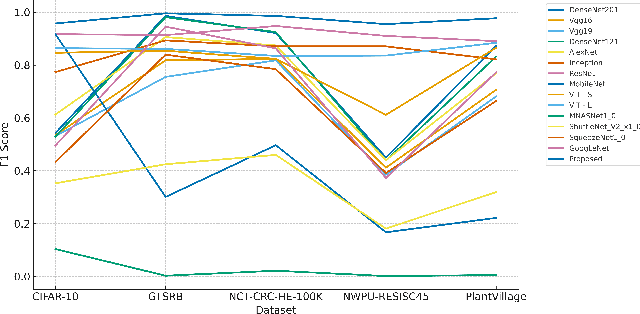
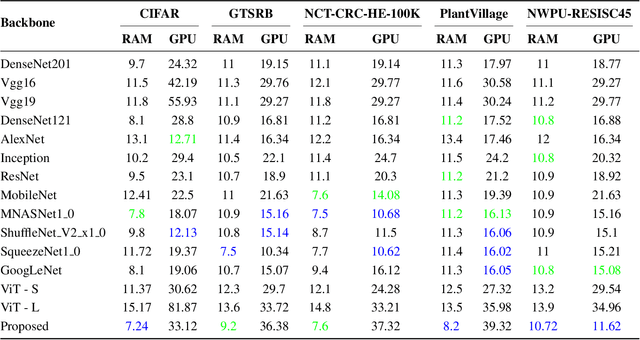
Image classification is a computer vision task where a model analyzes an image to categorize it into a specific label. Vision Transformers (ViT) improve this task by leveraging self-attention to capture complex patterns and long range relationships between image patches. However, a key challenge for ViTs is efficiently incorporating multiscale feature representations, which is inherent in CNNs through their hierarchical structure. In this paper, we introduce the Scale-Aware Graph Attention Vision Transformer (SAG-ViT), a novel framework that addresses this challenge by integrating multi-scale features. Using EfficientNet as a backbone, the model extracts multi-scale feature maps, which are divided into patches to preserve semantic information. These patches are organized into a graph based on spatial and feature similarities, with a Graph Attention Network (GAT) refining the node embeddings. Finally, a Transformer encoder captures long-range dependencies and complex interactions. The SAG-ViT is evaluated on benchmark datasets, demonstrating its effectiveness in enhancing image classification performance.