 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Adaptive Hybrid Focal-Entropy Loss for Enhancing Diabetic Retinopathy Detection Using Convolutional Neural Networks
Nov 16, 2024



Diabetic retinopathy is a leading cause of blindness around the world and demands precise AI-based diagnostic tools. Traditional loss functions in multi-class classification, such as Categorical Cross-Entropy (CCE), are very common but break down with class imbalance, especially in cases with inherently challenging or overlapping classes, which leads to biased and less sensitive models. Since a heavy imbalance exists in the number of examples for higher severity stage 4 diabetic retinopathy, etc., classes compared to those very early stages like class 0, achieving class balance is key. For this purpose, we propose the Adaptive Hybrid Focal-Entropy Loss which combines the ideas of focal loss and entropy loss with adaptive weighting in order to focus on minority classes and highlight the challenging samples. The state-of-the art models applied for diabetic retinopathy detection with AHFE revealed good performance improvements, indicating the top performances of ResNet50 at 99.79%, DenseNet121 at 98.86%, Xception at 98.92%, MobileNetV2 at 97.84%, and InceptionV3 at 93.62% accuracy. This sheds light into how AHFE promotes enhancement in AI-driven diagnostics for complex and imbalanced medical datasets.
Multimodal Emotion Recognition using Audio-Video Transformer Fusion with Cross Attention
Jul 26, 2024Understanding emotions is a fundamental aspect of human communication. Integrating audio and video signals offers a more comprehensive understanding of emotional states compared to traditional methods that rely on a single data source, such as speech or facial expressions. Despite its potential, multimodal emotion recognition faces significant challenges, particularly in synchronization, feature extraction, and fusion of diverse data sources. To address these issues, this paper introduces a novel transformer-based model named Audio-Video Transformer Fusion with Cross Attention (AVT-CA). The AVT-CA model employs a transformer fusion approach to effectively capture and synchronize interlinked features from both audio and video inputs, thereby resolving synchronization problems. Additionally, the Cross Attention mechanism within AVT-CA selectively extracts and emphasizes critical features while discarding irrelevant ones from both modalities, addressing feature extraction and fusion challenges. Extensive experimental analysis conducted on the CMU-MOSEI, RAVDESS and CREMA-D datasets demonstrates the efficacy of the proposed model. The results underscore the importance of AVT-CA in developing precise and reliable multimodal emotion recognition systems for practical applications.
Multi-Attention Integrated Deep Learning Frameworks for Enhanced Breast Cancer Segmentation and Identification
Jul 03, 2024
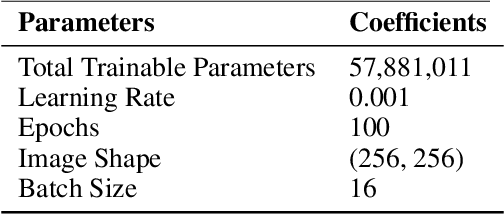
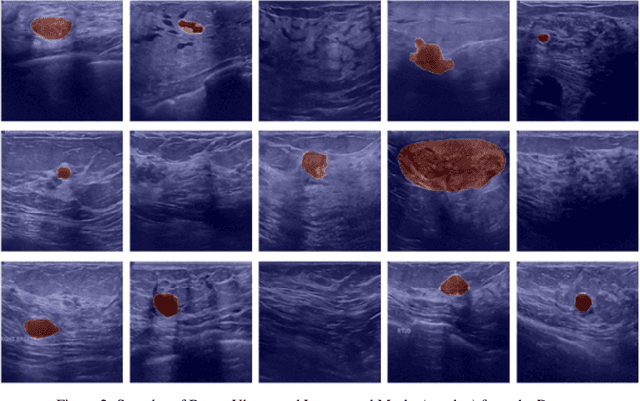
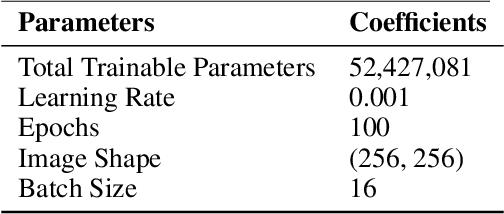
Breast cancer poses a profound threat to lives globally, claiming numerous lives each year. Therefore, timely detection is crucial for early intervention and improved chances of survival. Accurately diagnosing and classifying breast tumors using ultrasound images is a persistent challenge in medicine, demanding cutting-edge solutions for improved treatment strategies. This research introduces multiattention-enhanced deep learning (DL) frameworks designed for the classification and segmentation of breast cancer tumors from ultrasound images. A spatial channel attention mechanism is proposed for segmenting tumors from ultrasound images, utilizing a novel LinkNet DL framework with an InceptionResNet backbone. Following this, the paper proposes a deep convolutional neural network with an integrated multi-attention framework (DCNNIMAF) to classify the segmented tumor as benign, malignant, or normal. From experimental results, it is observed that the segmentation model has recorded an accuracy of 98.1%, with a minimal loss of 0.6%. It has also achieved high Intersection over Union (IoU) and Dice Coefficient scores of 96.9% and 97.2%, respectively. Similarly, the classification model has attained an accuracy of 99.2%, with a low loss of 0.31%. Furthermore, the classification framework has achieved outstanding F1-Score, precision, and recall values of 99.1%, 99.3%, and 99.1%, respectively. By offering a robust framework for early detection and accurate classification of breast cancer, this proposed work significantly advances the field of medical image analysis, potentially improving diagnostic precision and patient outcomes.