 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiCA: Effective Biomedical Dense Retrieval with Citation-Aware Hard Negatives
Nov 11, 2025Hard negatives are essential for training effective retrieval models. Hard-negative mining typically relies on ranking documents using cross-encoders or static embedding models based on similarity metrics such as cosine distance. Hard negative mining becomes challenging for biomedical and scientific domains due to the difficulty in distinguishing between source and hard negative documents. However, referenced documents naturally share contextual relevance with the source document but are not duplicates, making them well-suited as hard negatives. In this work, we propose BiCA: Biomedical Dense Retrieval with Citation-Aware Hard Negatives, an approach for hard-negative mining by utilizing citation links in 20,000 PubMed articles for improving a domain-specific small dense retriever. We fine-tune the GTE_small and GTE_Base models using these citation-informed negatives and observe consistent improvements in zero-shot dense retrieval using nDCG@10 for both in-domain and out-of-domain tasks on BEIR and outperform baselines on long-tailed topics in LoTTE using Success@5. Our findings highlight the potential of leveraging document link structure to generate highly informative negatives, enabling state-of-the-art performance with minimal fine-tuning and demonstrating a path towards highly data-efficient domain adaptation.
Don't Retrieve, Generate: Prompting LLMs for Synthetic Training Data in Dense Retrieval
Apr 20, 2025Training effective dense retrieval models often relies on hard negative (HN) examples mined from the document corpus via methods like BM25 or cross-encoders (CE), processes that can be computationally demanding and require full corpus access. This paper introduces a different approach, an end-to-end pipeline where a Large Language Model (LLM) first generates a query from a passage, and then generates a hard negative example using \emph{only} that query text. This corpus-free negative generation contrasts with standard mining techniques. We evaluated this \textsc{LLM Query $\rightarrow$ LLM HN} approach against traditional \textsc{LLM Query $\rightarrow$ BM25 HN} and \textsc{LLM Query $\rightarrow$ CE HN} pipelines using E5-Base and GTE-Base models on several BEIR benchmark datasets. Our results show the proposed all-LLM pipeline achieves performance identical to both the BM25 and the computationally intensive CE baselines across nDCG@10, Precision@10, and Recall@100 metrics. This demonstrates that our corpus-free negative generation method matches the effectiveness of complex, corpus-dependent mining techniques, offering a potentially simpler and more efficient pathway for training high-performance retrievers without sacrificing results. We make the dataset including the queries and the hard-negatives for all three methods publicly available https://huggingface.co/collections/chungimungi/arxiv-hard-negatives-68027bbc601ff6cc8eb1f449.
Predicting Liquidity-Aware Bond Yields using Causal GANs and Deep Reinforcement Learning with LLM Evaluation
Feb 24, 2025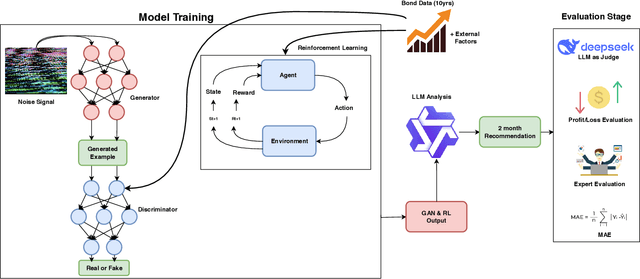
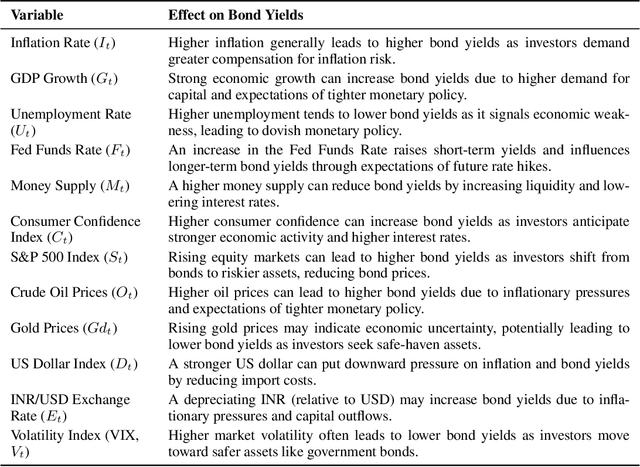
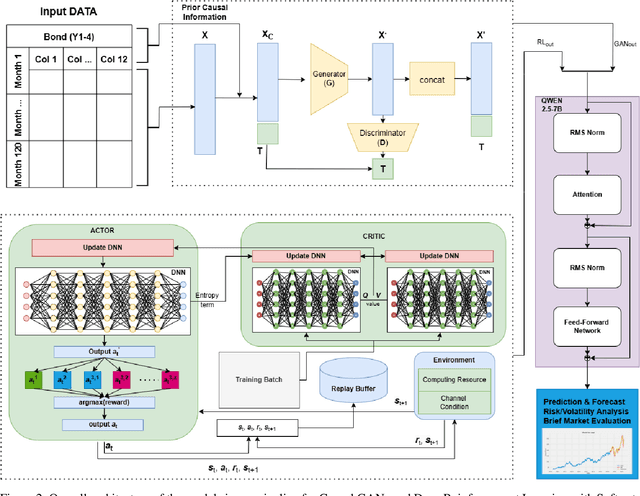

Financial bond yield forecasting is challenging due to data scarcity, nonlinear macroeconomic dependencies, and evolving market conditions. In this paper, we propose a novel framework that leverages Causal Generative Adversarial Networks (CausalGANs) and Soft Actor-Critic (SAC) reinforcement learning (RL) to generate high-fidelity synthetic bond yield data for four major bond categories (AAA, BAA, US10Y, Junk). By incorporating 12 key macroeconomic variables, we ensure statistical fidelity by preserving essential market properties. To transform this market dependent synthetic data into actionable insights, we employ a finetuned Large Language Model (LLM) Qwen2.5-7B that generates trading signals (BUY/HOLD/SELL), risk assessments, and volatility projections. We use automated, human and LLM evaluations, all of which demonstrate that our framework improves forecasting performance over existing methods, with statistical validation via predictive accuracy, MAE evaluation(0.103%), profit/loss evaluation (60% profit rate), LLM evaluation (3.37/5) and expert assessments scoring 4.67 out of 5. The reinforcement learning-enhanced synthetic data generation achieves the least Mean Absolute Error of 0.103, demonstrating its effectiveness in replicating real-world bond market dynamics. We not only enhance data-driven trading strategies but also provides a scalable, high-fidelity synthetic financial data pipeline for risk & volatility management and investment decision-making. This work establishes a bridge between synthetic data generation, LLM driven financial forecasting, and language model evaluation, contributing to AI-driven financial decision-making.
ArxEval: Evaluating Retrieval and Generation in Language Models for Scientific Literature
Jan 17, 2025



Language Models [LMs] are now playing an increasingly large role in information generation and synthesis; the representation of scientific knowledge in these systems needs to be highly accurate. A prime challenge is hallucination; that is, generating apparently plausible but actually false information, including invented citations and nonexistent research papers. This kind of inaccuracy is dangerous in all the domains that require high levels of factual correctness, such as academia and education. This work presents a pipeline for evaluating the frequency with which language models hallucinate in generating responses in the scientific literature. We propose ArxEval, an evaluation pipeline with two tasks using ArXiv as a repository: Jumbled Titles and Mixed Titles. Our evaluation includes fifteen widely used language models and provides comparative insights into their reliability in handling scientific literature.
ViBe: A Text-to-Video Benchmark for Evaluating Hallucination in Large Multimodal Models
Nov 16, 2024



Latest developments in Large Multimodal Models (LMMs) have broadened their capabilities to include video understanding. Specifically, Text-to-video (T2V) models have made significant progress in quality, comprehension, and duration, excelling at creating videos from simple textual prompts. Yet, they still frequently produce hallucinated content that clearly signals the video is AI-generated. We introduce ViBe: a large-scale Text-to-Video Benchmark of hallucinated videos from T2V models. We identify five major types of hallucination: Vanishing Subject, Numeric Variability, Temporal Dysmorphia, Omission Error, and Physical Incongruity. Using 10 open-source T2V models, we developed the first large-scale dataset of hallucinated videos, comprising 3,782 videos annotated by humans into these five categories. ViBe offers a unique resource for evaluating the reliability of T2V models and provides a foundation for improving hallucination detection and mitigation in video generation. We establish classification as a baseline and present various ensemble classifier configurations, with the TimeSFormer + CNN combination yielding the best performance, achieving 0.345 accuracy and 0.342 F1 score. This benchmark aims to drive the development of robust T2V models that produce videos more accurately aligned with input prompts.
A Multi-Branched Radial Basis Network Approach to Predicting Complex Chaotic Behaviours
Mar 31, 2024In this study, we propose a multi branched network approach to predict the dynamics of a physics attractor characterized by intricate and chaotic behavior. We introduce a unique neural network architecture comprised of Radial Basis Function (RBF) layers combined with an attention mechanism designed to effectively capture nonlinear inter-dependencies inherent in the attractor's temporal evolution. Our results demonstrate successful prediction of the attractor's trajectory across 100 predictions made using a real-world dataset of 36,700 time-series observations encompassing approximately 28 minutes of activity. To further illustrate the performance of our proposed technique, we provide comprehensive visualizations depicting the attractor's original and predicted behaviors alongside quantitative measures comparing observed versus estimated outcomes. Overall, this work showcases the potential of advanced machine learning algorithms in elucidating hidden structures in complex physical systems while offering practical applications in various domains requiring accurate short-term forecasting capabilities.