 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViBe: A Text-to-Video Benchmark for Evaluating Hallucination in Large Multimodal Models
Nov 16, 2024



Latest developments in Large Multimodal Models (LMMs) have broadened their capabilities to include video understanding. Specifically, Text-to-video (T2V) models have made significant progress in quality, comprehension, and duration, excelling at creating videos from simple textual prompts. Yet, they still frequently produce hallucinated content that clearly signals the video is AI-generated. We introduce ViBe: a large-scale Text-to-Video Benchmark of hallucinated videos from T2V models. We identify five major types of hallucination: Vanishing Subject, Numeric Variability, Temporal Dysmorphia, Omission Error, and Physical Incongruity. Using 10 open-source T2V models, we developed the first large-scale dataset of hallucinated videos, comprising 3,782 videos annotated by humans into these five categories. ViBe offers a unique resource for evaluating the reliability of T2V models and provides a foundation for improving hallucination detection and mitigation in video generation. We establish classification as a baseline and present various ensemble classifier configurations, with the TimeSFormer + CNN combination yielding the best performance, achieving 0.345 accuracy and 0.342 F1 score. This benchmark aims to drive the development of robust T2V models that produce videos more accurately aligned with input prompts.
GRS-QA -- Graph Reasoning-Structured Question Answering Dataset
Nov 01, 2024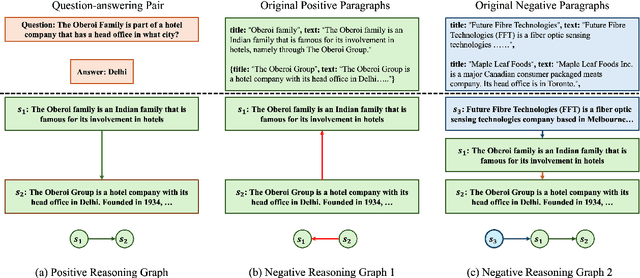
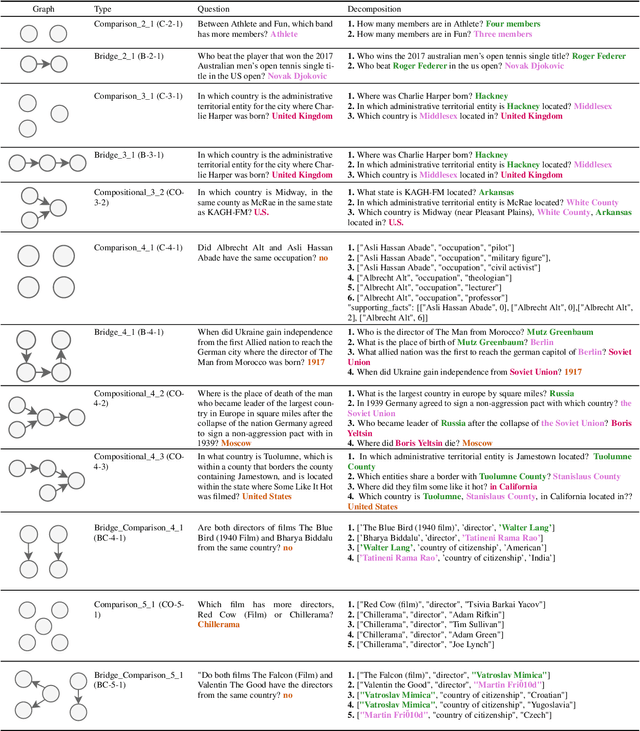
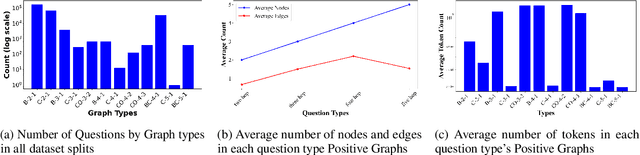

Large Language Models (LLMs) have excelled in multi-hop question-answering (M-QA) due to their advanced reasoning abilities. However, the impact of the inherent reasoning structures on LLM M-QA performance remains unclear, largely due to the absence of QA datasets that provide fine-grained reasoning structures. To address this gap, we introduce the Graph Reasoning-Structured Question Answering Dataset (GRS-QA), which includes both semantic contexts and reasoning structures for QA pairs. Unlike existing M-QA datasets, where different reasoning structures are entangled together, GRS-QA explicitly captures intricate reasoning pathways by constructing reasoning graphs, where nodes represent textual contexts and edges denote logical flows. These reasoning graphs of different structures enable a fine-grained evaluation of LLM reasoning capabilities across various reasoning structures. Our empirical analysis reveals that LLMs perform differently when handling questions with varying reasoning structures. This finding facilitates the exploration of textual structures as compared with semantics.
NLP at UC Santa Cruz at SemEval-2024 Task 5: Legal Answer Validation using Few-Shot Multi-Choice QA
Apr 04, 2024This paper presents our submission to the SemEval 2024 Task 5: The Legal Argument Reasoning Task in Civil Procedure. We present two approaches to solving the task of legal answer validation, given an introduction to the case, a question and an answer candidate. Firstly, we fine-tuned pre-trained BERT-based models and found that models trained on domain knowledge perform better. Secondly, we performed few-shot prompting on GPT models and found that reformulating the answer validation task to be a multiple-choice QA task remarkably improves the performance of the model. Our best submission is a BERT-based model that achieved the 7th place out of 20.