 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECI: Effective Contrastive Information to Evaluate Hard-Negatives
Mar 22, 2026Hard negatives play a critical role in training and fine-tuning dense retrieval models, as they are semantically similar to positive documents yet non-relevant, and correctly distinguishing them is essential for improving retrieval accuracy. However, identifying effective hard negatives typically requires extensive ablation studies involving repeated fine-tuning with different negative sampling strategies and hyperparameters, resulting in substantial computational cost. In this paper, we introduce ECI: Effective Contrastive Information , a theoretically grounded metric grounded in Information Theory and Information Retrieval principles that enables practitioners to assess the quality of hard negatives prior to model fine-tuning. ECI evaluates negatives by optimizing the trade-off between Information Capacity the logarithmic bound on mutual information determined by set size and Discriminative Efficiency, a harmonic balance of Signal Magnitude (Hardness) and Safety (Max-Margin). Unlike heuristic approaches, ECI strictly penalizes unsafe, false-positive negatives prevalent in generative methods. We evaluate ECI across hard-negative sets mined or generated using BM25, cross-encoders, and large language models. Our results demonstrate that ECI accurately predicts downstream retrieval performance, identifying that hybrid strategies (BM25+Cross-Encoder) offer the optimal balance of volume and reliability, significantly reducing the need for costly end-to-end ablation studies.
Scaling Laws for Reranking in Information Retrieval
Mar 05, 2026Scaling laws have been observed across a wide range of tasks, such as natural language generation and dense retrieval, where performance follows predictable patterns as model size, data, and compute grow. However, these scaling laws are insufficient for understanding the scaling behavior of multi-stage retrieval systems, which typically include a reranking stage. In large-scale multi-stage retrieval systems, reranking is the final and most influential step before presenting a ranked list of items to the end user. In this work, we present the first systematic study of scaling laws for rerankers by analyzing performance across model sizes and data budgets for three popular paradigms: pointwise, pairwise, and listwise reranking. Using a detailed case study with cross-encoder rerankers, we demonstrate that performance follows a predictable power law. This regularity allows us to accurately forecast the performance of larger models for some metrics more than others using smaller-scale experiments, offering a robust methodology for saving significant computational resources. For example, we accurately estimate the NDCG of a 1B-parameter model by training and evaluating only smaller models (up to 400M parameters), in both in-domain as well as out-of-domain settings. Our experiments encompass span several loss functions, models and metrics and demonstrate that downstream metrics like NDCG, MAP (Mean Avg Precision) show reliable scaling behavior and can be forecasted accurately at scale, while highlighting the limitations of metrics like Contrastive Entropy and MRR (Mean Reciprocal Rank) which do not follow predictable scaling behavior in all instances. Our results establish scaling principles for reranking and provide actionable insights for building industrial-grade retrieval systems.
ViBe: A Text-to-Video Benchmark for Evaluating Hallucination in Large Multimodal Models
Nov 16, 2024



Latest developments in Large Multimodal Models (LMMs) have broadened their capabilities to include video understanding. Specifically, Text-to-video (T2V) models have made significant progress in quality, comprehension, and duration, excelling at creating videos from simple textual prompts. Yet, they still frequently produce hallucinated content that clearly signals the video is AI-generated. We introduce ViBe: a large-scale Text-to-Video Benchmark of hallucinated videos from T2V models. We identify five major types of hallucination: Vanishing Subject, Numeric Variability, Temporal Dysmorphia, Omission Error, and Physical Incongruity. Using 10 open-source T2V models, we developed the first large-scale dataset of hallucinated videos, comprising 3,782 videos annotated by humans into these five categories. ViBe offers a unique resource for evaluating the reliability of T2V models and provides a foundation for improving hallucination detection and mitigation in video generation. We establish classification as a baseline and present various ensemble classifier configurations, with the TimeSFormer + CNN combination yielding the best performance, achieving 0.345 accuracy and 0.342 F1 score. This benchmark aims to drive the development of robust T2V models that produce videos more accurately aligned with input prompts.
A Normal Form Characterization for Efficient Boolean Skolem Function Synthesis
Apr 29, 2021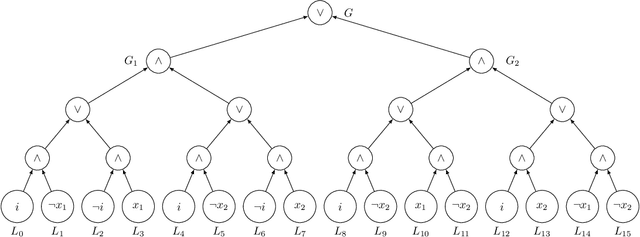
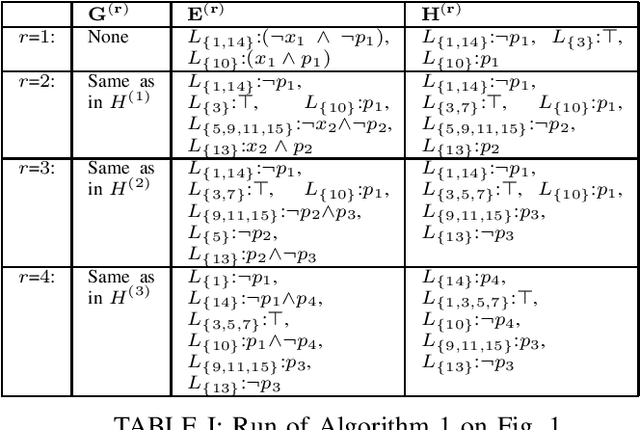
Boolean Skolem function synthesis concerns synthesizing outputs as Boolean functions of inputs such that a relational specification between inputs and outputs is satisfied. This problem, also known as Boolean functional synthesis, has several applications, including design of safe controllers for autonomous systems, certified QBF solving, cryptanalysis etc. Recently, complexity theoretic hardness results have been shown for the problem, although several algorithms proposed in the literature are known to work well in practice. This dichotomy between theoretical hardness and practical efficacy has motivated the research into normal forms or representations of input specifications that permit efficient synthesis, thus explaining perhaps the efficacy of these algorithms. In this paper we go one step beyond this and ask if there exists a normal form representation that can in fact precisely characterize "efficient" synthesis. We present a normal form called SAUNF that precisely characterizes tractable synthesis in the following sense: a specification is polynomial time synthesizable iff it can be compiled to SAUNF in polynomial time. Additionally, a specification admits a polynomial-sized functional solution iff there exists a semantically equivalent polynomial-sized SAUNF representation. SAUNF is exponentially more succinct than well-established normal forms like BDDs and DNNFs, used in the context of AI problems, and strictly subsumes other more recently proposed forms like SynNNF. It enjoys compositional properties that are similar to those of DNNF. Thus, SAUNF provides the right trade-off in knowledge representation for Boolean functional synthesis.