 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025
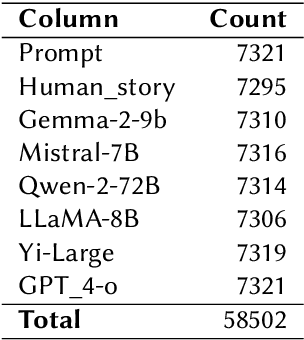

The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
DPO Kernels: A Semantically-Aware, Kernel-Enhanced, and Divergence-Rich Paradigm for Direct Preference Optimization
Jan 08, 2025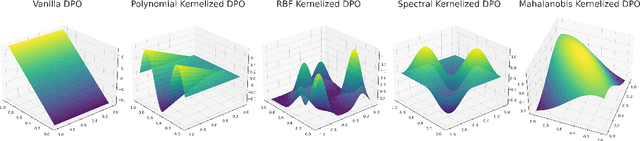


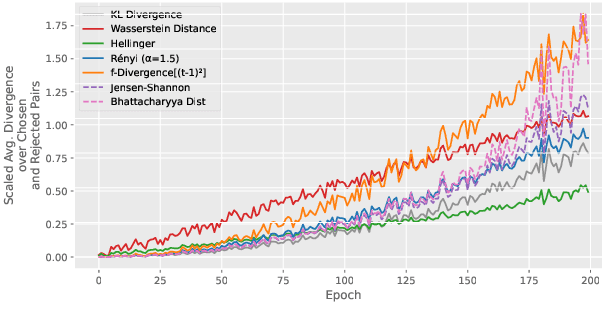
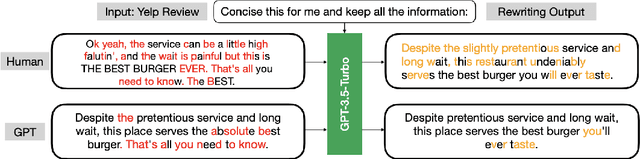
The rapid rise of large language models (LLMs) has unlocked many applications but also underscores the challenge of aligning them with diverse values and preferences. Direct Preference Optimization (DPO) is central to alignment but constrained by fixed divergences and limited feature transformations. We propose DPO-Kernels, which integrates kernel methods to address these issues through four key contributions: (i) Kernelized Representations with polynomial, RBF, Mahalanobis, and spectral kernels for richer transformations, plus a hybrid loss combining embedding-based and probability-based objectives; (ii) Divergence Alternatives (Jensen-Shannon, Hellinger, Renyi, Bhattacharyya, Wasserstein, and f-divergences) for greater stability; (iii) Data-Driven Selection metrics that automatically choose the best kernel-divergence pair; and (iv) a Hierarchical Mixture of Kernels for both local precision and global modeling. Evaluations on 12 datasets demonstrate state-of-the-art performance in factuality, safety, reasoning, and instruction following. Grounded in Heavy-Tailed Self-Regularization, DPO-Kernels maintains robust generalization for LLMs, offering a comprehensive resource for further alignment research.
ViBe: A Text-to-Video Benchmark for Evaluating Hallucination in Large Multimodal Models
Nov 16, 2024



Latest developments in Large Multimodal Models (LMMs) have broadened their capabilities to include video understanding. Specifically, Text-to-video (T2V) models have made significant progress in quality, comprehension, and duration, excelling at creating videos from simple textual prompts. Yet, they still frequently produce hallucinated content that clearly signals the video is AI-generated. We introduce ViBe: a large-scale Text-to-Video Benchmark of hallucinated videos from T2V models. We identify five major types of hallucination: Vanishing Subject, Numeric Variability, Temporal Dysmorphia, Omission Error, and Physical Incongruity. Using 10 open-source T2V models, we developed the first large-scale dataset of hallucinated videos, comprising 3,782 videos annotated by humans into these five categories. ViBe offers a unique resource for evaluating the reliability of T2V models and provides a foundation for improving hallucination detection and mitigation in video generation. We establish classification as a baseline and present various ensemble classifier configurations, with the TimeSFormer + CNN combination yielding the best performance, achieving 0.345 accuracy and 0.342 F1 score. This benchmark aims to drive the development of robust T2V models that produce videos more accurately aligned with input prompts.
Exploring the Relationship between Analogy Identification and Sentence Structure Encoding in Large Language Models
Oct 13, 2023Identifying analogies plays a pivotal role in human cognition and language proficiency. In the last decade, there has been extensive research on word analogies in the form of ``A is to B as C is to D.'' However, there is a growing interest in analogies that involve longer text, such as sentences and collections of sentences, which convey analogous meanings. While the current NLP research community evaluates the ability of Large Language Models (LLMs) to identify such analogies, the underlying reasons behind these abilities warrant deeper investigation. Furthermore, the capability of LLMs to encode both syntactic and semantic structures of language within their embeddings has garnered significant attention with the surge in their utilization. In this work, we examine the relationship between the abilities of multiple LLMs to identify sentence analogies, and their capacity to encode syntactic and semantic structures. Through our analysis, we find that analogy identification ability of LLMs is positively correlated with their ability to encode syntactic and semantic structures of sentences. Specifically, we find that the LLMs which capture syntactic structures better, also have higher abilities in identifying sentence analogies.
ANALOGICAL -- A New Benchmark for Analogy of Long Text for Large Language Models
May 14, 2023



Over the past decade, analogies, in the form of word-level analogies, have played a significant role as an intrinsic measure of evaluating the quality of word embedding methods such as word2vec. Modern large language models (LLMs), however, are primarily evaluated on extrinsic measures based on benchmarks such as GLUE and SuperGLUE, and there are only a few investigations on whether LLMs can draw analogies between long texts. In this paper, we present ANALOGICAL, a new benchmark to intrinsically evaluate LLMs across a taxonomy of analogies of long text with six levels of complexity -- (i) word, (ii) word vs. sentence, (iii) syntactic, (iv) negation, (v) entailment, and (vi) metaphor. Using thirteen datasets and three different distance measures, we evaluate the abilities of eight LLMs in identifying analogical pairs in the semantic vector space. Our evaluation finds that it is increasingly challenging for LLMs to identify analogies when going up the analogy taxonomy.