 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYINYANG-ALIGN: Benchmarking Contradictory Objectives and Proposing Multi-Objective Optimization based DPO for Text-to-Image Alignment
Feb 05, 2025



Precise alignment in Text-to-Image (T2I) systems is crucial to ensure that generated visuals not only accurately encapsulate user intents but also conform to stringent ethical and aesthetic benchmarks. Incidents like the Google Gemini fiasco, where misaligned outputs triggered significant public backlash, underscore the critical need for robust alignment mechanisms. In contrast, Large Language Models (LLMs) have achieved notable success in alignment. Building on these advancements, researchers are eager to apply similar alignment techniques, such as Direct Preference Optimization (DPO), to T2I systems to enhance image generation fidelity and reliability. We present YinYangAlign, an advanced benchmarking framework that systematically quantifies the alignment fidelity of T2I systems, addressing six fundamental and inherently contradictory design objectives. Each pair represents fundamental tensions in image generation, such as balancing adherence to user prompts with creative modifications or maintaining diversity alongside visual coherence. YinYangAlign includes detailed axiom datasets featuring human prompts, aligned (chosen) responses, misaligned (rejected) AI-generated outputs, and explanations of the underlying contradictions.
DPO Kernels: A Semantically-Aware, Kernel-Enhanced, and Divergence-Rich Paradigm for Direct Preference Optimization
Jan 08, 2025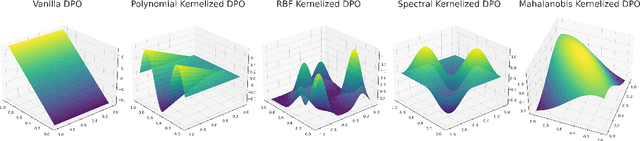


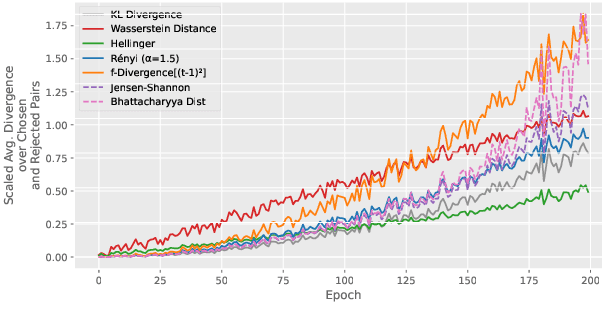
The rapid rise of large language models (LLMs) has unlocked many applications but also underscores the challenge of aligning them with diverse values and preferences. Direct Preference Optimization (DPO) is central to alignment but constrained by fixed divergences and limited feature transformations. We propose DPO-Kernels, which integrates kernel methods to address these issues through four key contributions: (i) Kernelized Representations with polynomial, RBF, Mahalanobis, and spectral kernels for richer transformations, plus a hybrid loss combining embedding-based and probability-based objectives; (ii) Divergence Alternatives (Jensen-Shannon, Hellinger, Renyi, Bhattacharyya, Wasserstein, and f-divergences) for greater stability; (iii) Data-Driven Selection metrics that automatically choose the best kernel-divergence pair; and (iv) a Hierarchical Mixture of Kernels for both local precision and global modeling. Evaluations on 12 datasets demonstrate state-of-the-art performance in factuality, safety, reasoning, and instruction following. Grounded in Heavy-Tailed Self-Regularization, DPO-Kernels maintains robust generalization for LLMs, offering a comprehensive resource for further alignment research.
Review-Feedback-Reason (ReFeR): A Novel Framework for NLG Evaluation and Reasoning
Jul 16, 2024



Assessing the quality of Natural Language Generation (NLG) outputs, such as those produced by large language models (LLMs), poses significant challenges. Traditional approaches involve either resource-intensive human evaluations or automatic metrics, which often exhibit a low correlation with human judgment. In this study, we propose Review-Feedback-Reason (ReFeR), a novel evaluation framework for NLG using LLM agents. We rigorously test ReFeR using two pre-existing benchmark datasets on diverse NLG tasks. The proposed framework not only enhances the accuracy of NLG evaluation, surpassing previous benchmarks by $\sim$20\%, but also generates constructive feedback and significantly improves collective reasoning. This feedback is then leveraged for the creation of instruction-tuning datasets, which, when used to fine-tune smaller models like Mistral-7B, makes them extremely good evaluators, yielding a better correlation with human evaluations and performance nearly on par with GPT-3.5. We highlight the effectiveness of our methodology through its application on three reasoning benchmarks, where it outperforms most of the state-of-the-art methods, and also outperforms the reasoning capabilities of models like GPT-3.5 Turbo by $\sim$11.67\% and GPT-4 by $\sim$1\% on an average.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024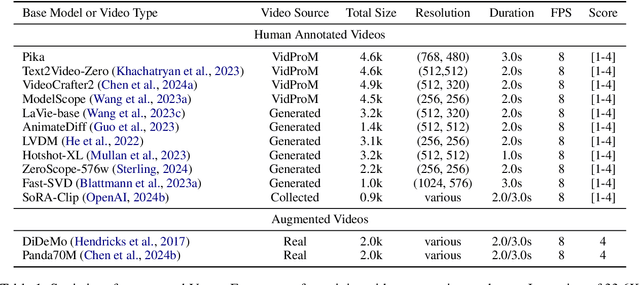

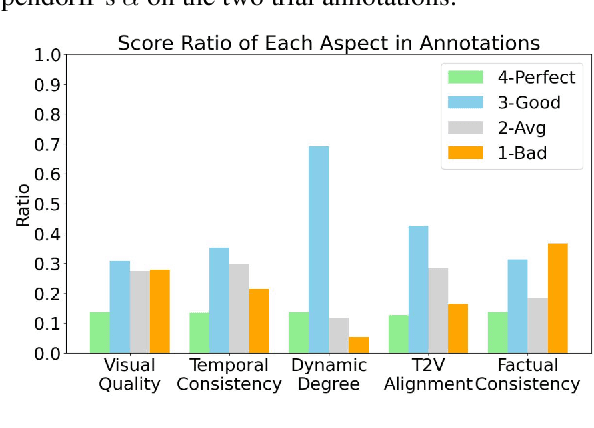

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
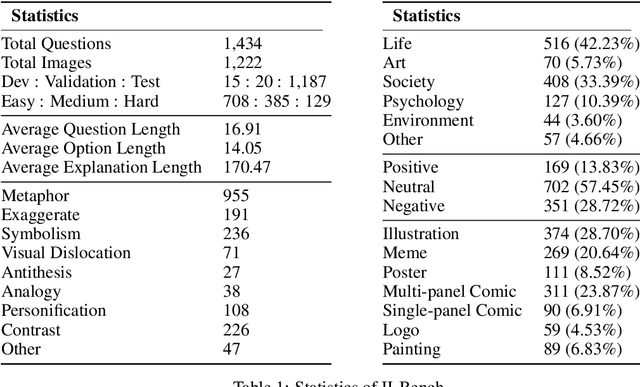
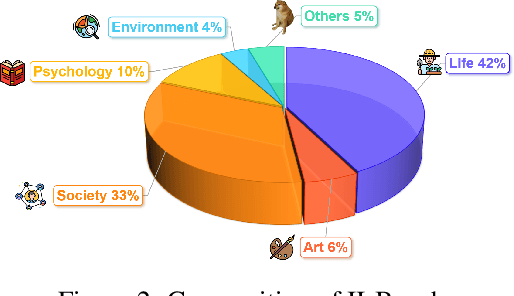
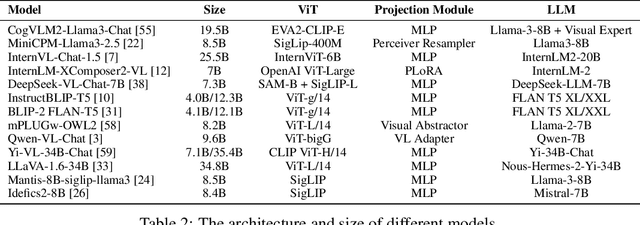
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
DepNeCTI: Dependency-based Nested Compound Type Identification for Sanskrit
Oct 14, 2023



Multi-component compounding is a prevalent phenomenon in Sanskrit, and understanding the implicit structure of a compound's components is crucial for deciphering its meaning. Earlier approaches in Sanskrit have focused on binary compounds and neglected the multi-component compound setting. This work introduces the novel task of nested compound type identification (NeCTI), which aims to identify nested spans of a multi-component compound and decode the implicit semantic relations between them. To the best of our knowledge, this is the first attempt in the field of lexical semantics to propose this task. We present 2 newly annotated datasets including an out-of-domain dataset for this task. We also benchmark these datasets by exploring the efficacy of the standard problem formulations such as nested named entity recognition, constituency parsing and seq2seq, etc. We present a novel framework named DepNeCTI: Dependency-based Nested Compound Type Identifier that surpasses the performance of the best baseline with an average absolute improvement of 13.1 points F1-score in terms of Labeled Span Score (LSS) and a 5-fold enhancement in inference efficiency. In line with the previous findings in the binary Sanskrit compound identification task, context provides benefits for the NeCTI task. The codebase and datasets are publicly available at: https://github.com/yaswanth-iitkgp/DepNeCTI