 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoPE: Denoising Rotary Position Embedding
Nov 12, 2025Rotary Position Embedding (RoPE) in Transformer models has inherent limits that weaken length extrapolation. We reinterpret the attention map with positional encoding as a noisy feature map, and propose Denoising Positional Encoding (DoPE), a training-free method based on truncated matrix entropy to detect outlier frequency bands in the feature map. Leveraging the noise characteristics of the feature map, we further reparameterize it with a parameter-free Gaussian distribution to achieve robust extrapolation. Our method theoretically reveals the underlying cause of the attention sink phenomenon and its connection to truncated matrix entropy. Experiments on needle-in-a-haystack and many-shot in-context learning tasks demonstrate that DoPE significantly improves retrieval accuracy and reasoning stability across extended contexts (up to 64K tokens). The results show that the denoising strategy for positional embeddings effectively mitigates attention sinks and restores balanced attention patterns, providing a simple yet powerful solution for improving length generalization. Our project page is Project: https://The-physical-picture-of-LLMs.github.io
Automatic Paper Reviewing with Heterogeneous Graph Reasoning over LLM-Simulated Reviewer-Author Debates
Nov 11, 2025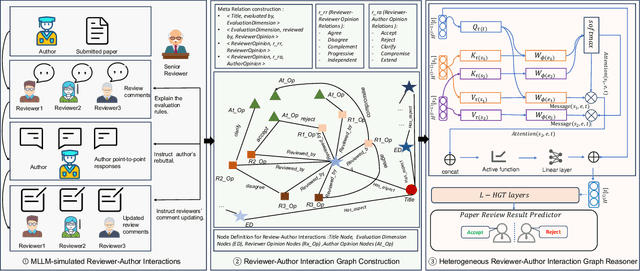
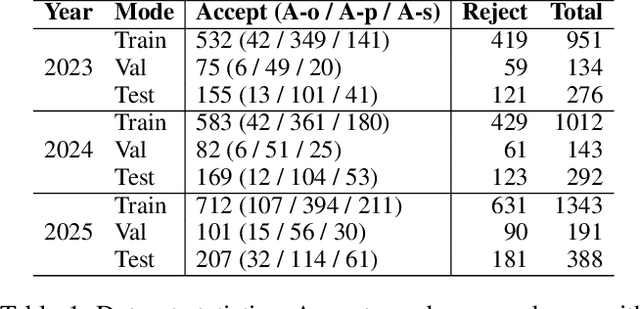
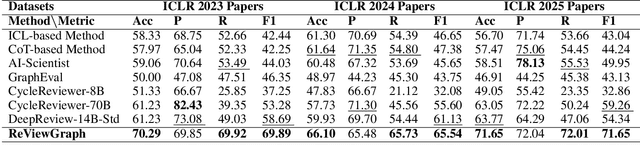
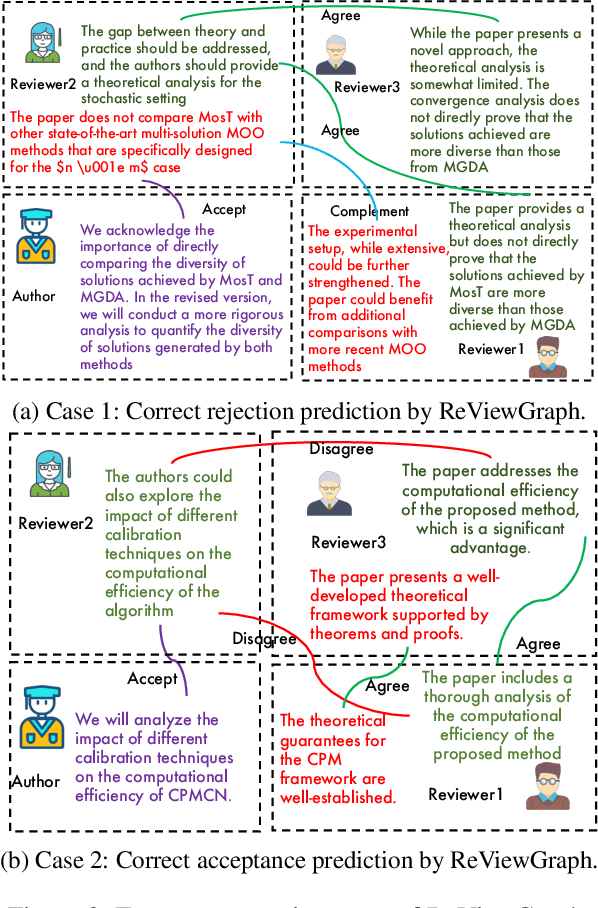
Existing paper review methods often rely on superficial manuscript features or directly on large language models (LLMs), which are prone to hallucinations, biased scoring, and limited reasoning capabilities. Moreover, these methods often fail to capture the complex argumentative reasoning and negotiation dynamics inherent in reviewer-author interactions. To address these limitations, we propose ReViewGraph (Reviewer-Author Debates Graph Reasoner), a novel framework that performs heterogeneous graph reasoning over LLM-simulated multi-round reviewer-author debates. In our approach, reviewer-author exchanges are simulated through LLM-based multi-agent collaboration. Diverse opinion relations (e.g., acceptance, rejection, clarification, and compromise) are then explicitly extracted and encoded as typed edges within a heterogeneous interaction graph. By applying graph neural networks to reason over these structured debate graphs, ReViewGraph captures fine-grained argumentative dynamics and enables more informed review decisions. Extensive experiments on three datasets demonstrate that ReViewGraph outperforms strong baselines with an average relative improvement of 15.73%, underscoring the value of modeling detailed reviewer-author debate structures.
IPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

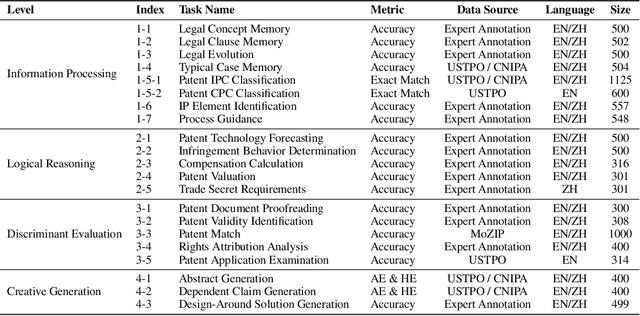
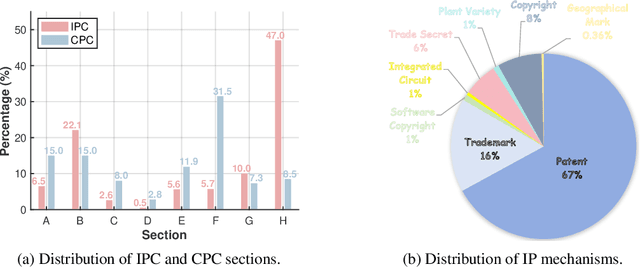
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
xJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
Jan 30, 2025



Safety alignment mechanism are essential for preventing large language models (LLMs) from generating harmful information or unethical content. However, cleverly crafted prompts can bypass these safety measures without accessing the model's internal parameters, a phenomenon known as black-box jailbreak. Existing heuristic black-box attack methods, such as genetic algorithms, suffer from limited effectiveness due to their inherent randomness, while recent reinforcement learning (RL) based methods often lack robust and informative reward signals. To address these challenges, we propose a novel black-box jailbreak method leveraging RL, which optimizes prompt generation by analyzing the embedding proximity between benign and malicious prompts. This approach ensures that the rewritten prompts closely align with the intent of the original prompts while enhancing the attack's effectiveness. Furthermore, we introduce a comprehensive jailbreak evaluation framework incorporating keywords, intent matching, and answer validation to provide a more rigorous and holistic assessment of jailbreak success. Experimental results show the superiority of our approach, achieving state-of-the-art (SOTA) performance on several prominent open and closed-source LLMs, including Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct, and GPT-4o-0806. Our method sets a new benchmark in jailbreak attack effectiveness, highlighting potential vulnerabilities in LLMs. The codebase for this work is available at https://github.com/Aegis1863/xJailbreak.
AgentCourt: Simulating Court with Adversarial Evolvable Lawyer Agents
Aug 15, 2024



In this paper, we present a simulation system called AgentCourt that simulates the entire courtroom process. The judge, plaintiff's lawyer, defense lawyer, and other participants are autonomous agents driven by large language models (LLMs). Our core goal is to enable lawyer agents to learn how to argue a case, as well as improving their overall legal skills, through courtroom process simulation. To achieve this goal, we propose an adversarial evolutionary approach for the lawyer-agent. Since AgentCourt can simulate the occurrence and development of court hearings based on a knowledge base and LLM, the lawyer agents can continuously learn and accumulate experience from real court cases. The simulation experiments show that after two lawyer-agents have engaged in a thousand adversarial legal cases in AgentCourt (which can take a decade for real-world lawyers), compared to their pre-evolutionary state, the evolved lawyer agents exhibit consistent improvement in their ability to handle legal tasks. To enhance the credibility of our experimental results, we enlisted a panel of professional lawyers to evaluate our simulations. The evaluation indicates that the evolved lawyer agents exhibit notable advancements in responsiveness, as well as expertise and logical rigor. This work paves the way for advancing LLM-driven agent technology in legal scenarios. Code is available at https://github.com/relic-yuexi/AgentCourt.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
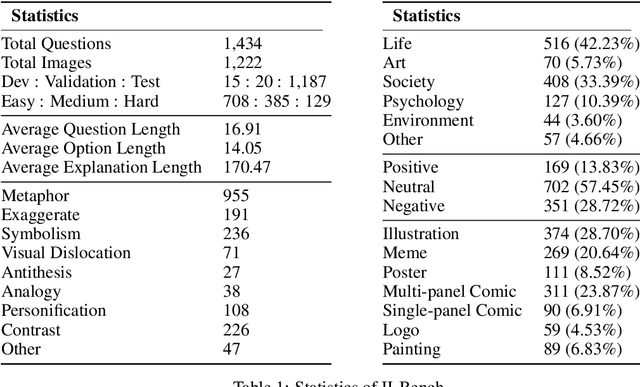
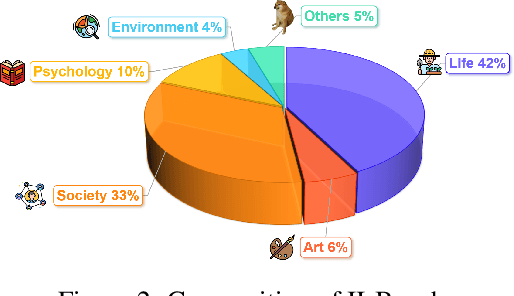
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.