 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawVideo: Generating Long Video from Storyboard Keyframe Sketches
May 22, 2026Long video generation requires high-fidelity synthesis, coherent narrative structure, and user control over extended time spans. Existing text-to-video methods often rely on a single long prompt, limiting control over pose, composition, layout, and motion. We propose DrawVideo, a sketch-guided, storyboard-driven framework for controllable long-video generation. DrawVideo decomposes long videos into independently controllable shots, each defined by a black-and-white sketch, an appearance prompt, and a motion prompt. The sketch controls pose and layout, the appearance prompt defines identity, scene, and style, and the motion prompt guides temporal dynamics. DrawVideo follows a hierarchical 'global multi-shot, local single-sketch' strategy: it first generates a structure-aligned reference keyframe, then expands the motion prompt into derivative keyframes representing action states, and finally synthesizes clips between adjacent keyframes to build each shot. We also introduce SketchLongVideo, the first dataset for sketch-guided text-to-long-video generation, constructed from animation videos via shot detection, keyframe extraction, vision-language recognition, prompt decomposition, and sketch conversion. Experiments show that DrawVideo achieves strong structural controllability, appearance consistency, visual stability, and coherent long-video generation.
Aes3D: Aesthetic Assessment in 3D Gaussian Splatting
May 06, 2026As 3D Gaussian Splatting (3DGS) gains attention in immersive media and digital content creation, assessing the aesthetics of 3D scenes becomes important in helping creators build more visually compelling 3D content. However, existing evaluation methods for 3D scenes primarily emphasize reconstruction fidelity and perceptual realism, largely overlooking higher-level aesthetic attributes such as composition, harmony, and visual appeal. This limitation comes from two key challenges: (1) the absence of general 3DGS datasets with aesthetic annotations, and (2) the intrinsic nature of 3DGS as a low-level primitive representation, which makes it difficult to capture high-level aesthetic features. To address these challenges, we propose Aes3D, the first systematic framework for assessing the aesthetics of 3D neural rendering scenes. Aes3D includes Aesthetic3D, the first dataset dedicated to 3D scene aesthetic assessment, built on our proposed annotation strategy for 3D scene aesthetics. In addition, we present Aes3DGSNet, a lightweight model that directly predicts scene-level aesthetic scores from 3DGS representations. Notably, our model operates solely on 3D Gaussian primitives, eliminating the need for rendering multi-view images and thus reducing computational cost and hardware requirements. Through aesthetics-supervised learning on multi-view 3DGS scene representations, Aes3DGSNet effectively captures high-level aesthetic cues and accurately regresses aesthetic scores. Experimental results demonstrate that our approach achieves strong performance while maintaining a lightweight design, establishing a new benchmark for 3D scene aesthetic assessment. Code and datasets will be made available in a future version.
RuCL: Stratified Rubric-Based Curriculum Learning for Multimodal Large Language Model Reasoning
Feb 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a prevailing paradigm for enhancing reasoning in Multimodal Large Language Models (MLLMs). However, relying solely on outcome supervision risks reward hacking, where models learn spurious reasoning patterns to satisfy final answer checks. While recent rubric-based approaches offer fine-grained supervision signals, they suffer from high computational costs of instance-level generation and inefficient training dynamics caused by treating all rubrics as equally learnable. In this paper, we propose Stratified Rubric-based Curriculum Learning (RuCL), a novel framework that reformulates curriculum learning by shifting the focus from data selection to reward design. RuCL generates generalized rubrics for broad applicability and stratifies them based on the model's competence. By dynamically adjusting rubric weights during training, RuCL guides the model from mastering foundational perception to tackling advanced logical reasoning. Extensive experiments on various visual reasoning benchmarks show that RuCL yields a remarkable +7.83% average improvement over the Qwen2.5-VL-7B model, achieving a state-of-the-art accuracy of 60.06%.
Unifying Stable Optimization and Reference Regularization in RLHF
Feb 12, 2026Reinforcement Learning from Human Feedback (RLHF) has advanced alignment capabilities significantly but remains hindered by two core challenges: \textbf{reward hacking} and \textbf{stable optimization}. Current solutions independently address these issues through separate regularization strategies, specifically a KL-divergence penalty against a supervised fine-tuned model ($π_0$) to mitigate reward hacking, and policy ratio clipping towards the current policy ($π_t$) to promote stable alignment. However, the implicit trade-off arising from simultaneously regularizing towards both $π_0$ and $π_t$ remains under-explored. In this paper, we introduce a unified regularization approach that explicitly balances the objectives of preventing reward hacking and maintaining stable policy updates. Our simple yet principled alignment objective yields a weighted supervised fine-tuning loss with a superior trade-off, which demonstrably improves both alignment results and implementation complexity. Extensive experiments across diverse benchmarks validate that our method consistently outperforms RLHF and online preference learning methods, achieving enhanced alignment performance and stability.
Beyond Quantity: Trajectory Diversity Scaling for Code Agents
Feb 03, 2026As code large language models (LLMs) evolve into tool-interactive agents via the Model Context Protocol (MCP), their generalization is increasingly limited by low-quality synthetic data and the diminishing returns of quantity scaling. Moreover, quantity-centric scaling exhibits an early bottleneck that underutilizes trajectory data. We propose TDScaling, a Trajectory Diversity Scaling-based data synthesis framework for code agents that scales performance through diversity rather than raw volume. Under a fixed training budget, increasing trajectory diversity yields larger gains than adding more trajectories, improving the performance-cost trade-off for agent training. TDScaling integrates four innovations: (1) a Business Cluster mechanism that captures real-service logical dependencies; (2) a blueprint-driven multi-agent paradigm that enforces trajectory coherence; (3) an adaptive evolution mechanism that steers synthesis toward long-tail scenarios using Domain Entropy, Reasoning Mode Entropy, and Cumulative Action Complexity to prevent mode collapse; and (4) a sandboxed code tool that mitigates catastrophic forgetting of intrinsic coding capabilities. Experiments on general tool-use benchmarks (BFCL, tau^2-Bench) and code agent tasks (RebenchT, CodeCI, BIRD) demonstrate a win-win outcome: TDScaling improves both tool-use generalization and inherent coding proficiency. We plan to release the full codebase and the synthesized dataset (including 30,000+ tool clusters) upon publication.
FinCast: A Foundation Model for Financial Time-Series Forecasting
Aug 27, 2025Financial time-series forecasting is critical for maintaining economic stability, guiding informed policymaking, and promoting sustainable investment practices. However, it remains challenging due to various underlying pattern shifts. These shifts arise primarily from three sources: temporal non-stationarity (distribution changes over time), multi-domain diversity (distinct patterns across financial domains such as stocks, commodities, and futures), and varying temporal resolutions (patterns differing across per-second, hourly, daily, or weekly indicators). While recent deep learning methods attempt to address these complexities, they frequently suffer from overfitting and typically require extensive domain-specific fine-tuning. To overcome these limitations, we introduce FinCast, the first foundation model specifically designed for financial time-series forecasting, trained on large-scale financial datasets. Remarkably, FinCast exhibits robust zero-shot performance, effectively capturing diverse patterns without domain-specific fine-tuning. Comprehensive empirical and qualitative evaluations demonstrate that FinCast surpasses existing state-of-the-art methods, highlighting its strong generalization capabilities.
OmniCharacter: Towards Immersive Role-Playing Agents with Seamless Speech-Language Personality Interaction
May 26, 2025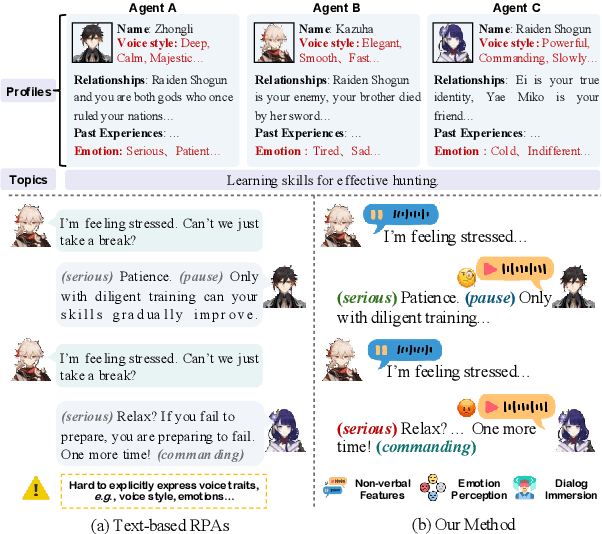



Role-Playing Agents (RPAs), benefiting from large language models, is an emerging interactive AI system that simulates roles or characters with diverse personalities. However, existing methods primarily focus on mimicking dialogues among roles in textual form, neglecting the role's voice traits (e.g., voice style and emotions) as playing a crucial effect in interaction, which tends to be more immersive experiences in realistic scenarios. Towards this goal, we propose OmniCharacter, a first seamless speech-language personality interaction model to achieve immersive RPAs with low latency. Specifically, OmniCharacter enables agents to consistently exhibit role-specific personality traits and vocal traits throughout the interaction, enabling a mixture of speech and language responses. To align the model with speech-language scenarios, we construct a dataset named OmniCharacter-10K, which involves more distinctive characters (20), richly contextualized multi-round dialogue (10K), and dynamic speech response (135K). Experimental results showcase that our method yields better responses in terms of both content and style compared to existing RPAs and mainstream speech-language models, with a response latency as low as 289ms. Code and dataset are available at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/OmniCharacter.
A Survey of 3D Reconstruction with Event Cameras: From Event-based Geometry to Neural 3D Rendering
May 13, 2025Event cameras have emerged as promising sensors for 3D reconstruction due to their ability to capture per-pixel brightness changes asynchronously. Unlike conventional frame-based cameras, they produce sparse and temporally rich data streams, which enable more accurate 3D reconstruction and open up the possibility of performing reconstruction in extreme environments such as high-speed motion, low light, or high dynamic range scenes. In this survey, we provide the first comprehensive review focused exclusively on 3D reconstruction using event cameras. The survey categorises existing works into three major types based on input modality - stereo, monocular, and multimodal systems, and further classifies them by reconstruction approach, including geometry-based, deep learning-based, and recent neural rendering techniques such as Neural Radiance Fields and 3D Gaussian Splatting. Methods with a similar research focus were organised chronologically into the most subdivided groups. We also summarise public datasets relevant to event-based 3D reconstruction. Finally, we highlight current research limitations in data availability, evaluation, representation, and dynamic scene handling, and outline promising future research directions. This survey aims to serve as a comprehensive reference and a roadmap for future developments in event-driven 3D reconstruction.
A Survey on Event-driven 3D Reconstruction: Development under Different Categories
Mar 26, 2025



Event cameras have gained increasing attention for 3D reconstruction due to their high temporal resolution, low latency, and high dynamic range. They capture per-pixel brightness changes asynchronously, allowing accurate reconstruction under fast motion and challenging lighting conditions. In this survey, we provide a comprehensive review of event-driven 3D reconstruction methods, including stereo, monocular, and multimodal systems. We further categorize recent developments based on geometric, learning-based, and hybrid approaches. Emerging trends, such as neural radiance fields and 3D Gaussian splatting with event data, are also covered. The related works are structured chronologically to illustrate the innovations and progression within the field. To support future research, we also highlight key research gaps and future research directions in dataset, experiment, evaluation, event representation, etc.
AccidentSim: Generating Physically Realistic Vehicle Collision Videos from Real-World Accident Reports
Mar 26, 2025

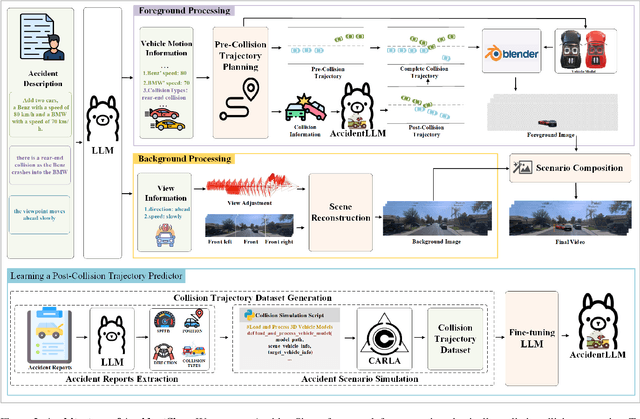

Collecting real-world vehicle accident videos for autonomous driving research is challenging due to their rarity and complexity. While existing driving video generation methods may produce visually realistic videos, they often fail to deliver physically realistic simulations because they lack the capability to generate accurate post-collision trajectories. In this paper, we introduce AccidentSim, a novel framework that generates physically realistic vehicle collision videos by extracting and utilizing the physical clues and contextual information available in real-world vehicle accident reports. Specifically, AccidentSim leverages a reliable physical simulator to replicate post-collision vehicle trajectories from the physical and contextual information in the accident reports and to build a vehicle collision trajectory dataset. This dataset is then used to fine-tune a language model, enabling it to respond to user prompts and predict physically consistent post-collision trajectories across various driving scenarios based on user descriptions. Finally, we employ Neural Radiance Fields (NeRF) to render high-quality backgrounds, merging them with the foreground vehicles that exhibit physically realistic trajectories to generate vehicle collision videos. Experimental results demonstrate that the videos produced by AccidentSim excel in both visual and physical authenticity.