 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoCBT: An Autonomous Multi-agent Framework for Cognitive Behavioral Therapy in Psychological Counseling
Jan 16, 2025



Traditional in-person psychological counseling remains primarily niche, often chosen by individuals with psychological issues, while online automated counseling offers a potential solution for those hesitant to seek help due to feelings of shame. Cognitive Behavioral Therapy (CBT) is an essential and widely used approach in psychological counseling. The advent of large language models (LLMs) and agent technology enables automatic CBT diagnosis and treatment. However, current LLM-based CBT systems use agents with a fixed structure, limiting their self-optimization capabilities, or providing hollow, unhelpful suggestions due to redundant response patterns. In this work, we utilize Quora-like and YiXinLi single-round consultation models to build a general agent framework that generates high-quality responses for single-turn psychological consultation scenarios. We use a bilingual dataset to evaluate the quality of single-response consultations generated by each framework. Then, we incorporate dynamic routing and supervisory mechanisms inspired by real psychological counseling to construct a CBT-oriented autonomous multi-agent framework, demonstrating its general applicability. Experimental results indicate that AutoCBT can provide higher-quality automated psychological counseling services.
Small Language Model as Data Prospector for Large Language Model
Dec 13, 2024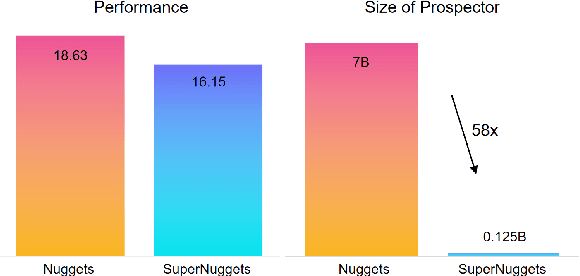
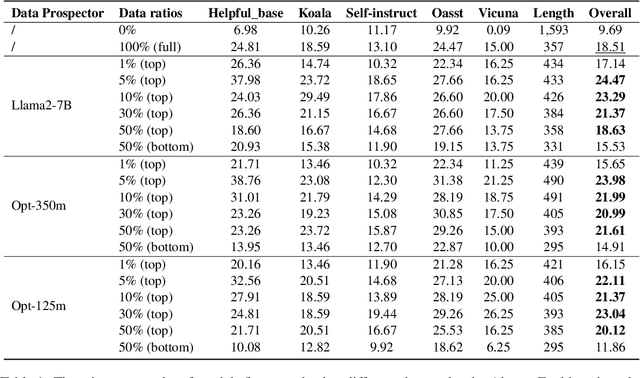
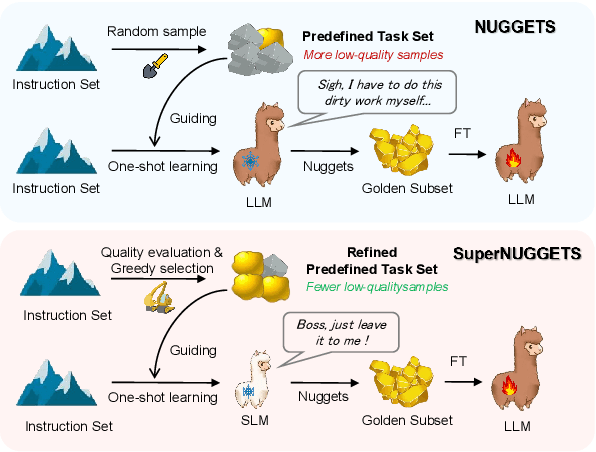
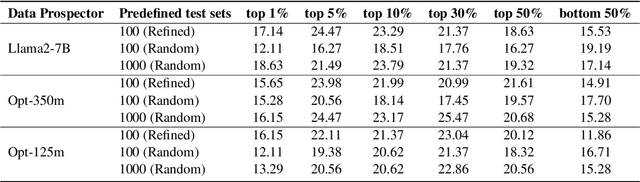
The quality of instruction data directly affects the performance of fine-tuned Large Language Models (LLMs). Previously, \cite{li2023one} proposed \texttt{NUGGETS}, which identifies and selects high-quality quality data from a large dataset by identifying those individual instruction examples that can significantly improve the performance of different tasks after being learnt as one-shot instances. In this work, we propose \texttt{SuperNUGGETS}, an improved variant of \texttt{NUGGETS} optimised for efficiency and performance. Our \texttt{SuperNUGGETS} uses a small language model (SLM) instead of a large language model (LLM) to filter the data for outstanding one-shot instances and refines the predefined set of tests. The experimental results show that the performance of \texttt{SuperNUGGETS} only decreases by 1-2% compared to \texttt{NUGGETS}, but the efficiency can be increased by a factor of 58. Compared to the original \texttt{NUGGETS}, our \texttt{SuperNUGGETS} has a higher utility value due to the significantly lower resource consumption.
II-Bench: An Image Implication Understanding Benchmark for Multimodal Large Language Models
Jun 11, 2024
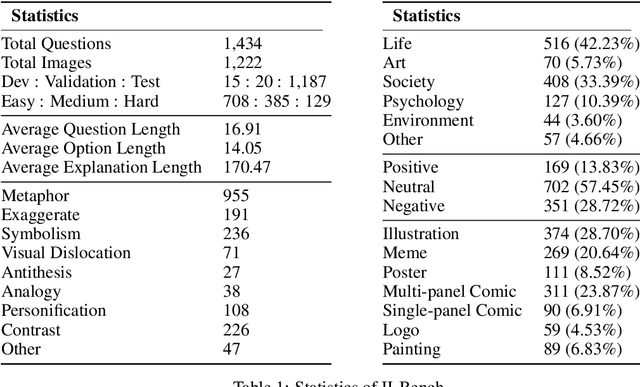
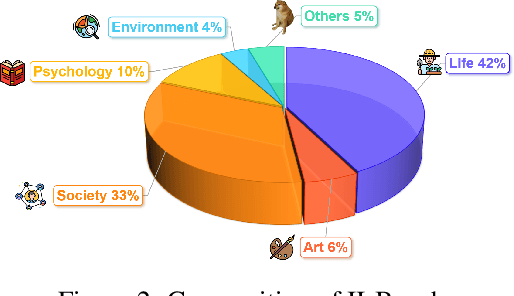
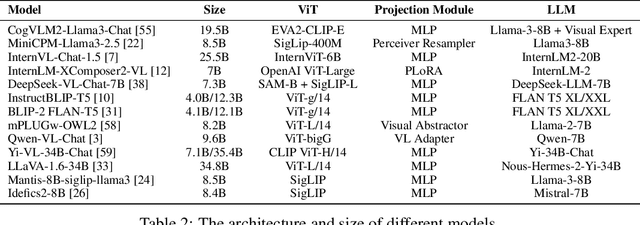
The rapid advancements in the development of multimodal large language models (MLLMs) have consistently led to new breakthroughs on various benchmarks. In response, numerous challenging and comprehensive benchmarks have been proposed to more accurately assess the capabilities of MLLMs. However, there is a dearth of exploration of the higher-order perceptual capabilities of MLLMs. To fill this gap, we propose the Image Implication understanding Benchmark, II-Bench, which aims to evaluate the model's higher-order perception of images. Through extensive experiments on II-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on II-Bench. The pinnacle accuracy of MLLMs attains 74.8%, whereas human accuracy averages 90%, peaking at an impressive 98%. Subsequently, MLLMs perform worse on abstract and complex images, suggesting limitations in their ability to understand high-level semantics and capture image details. Finally, it is observed that most models exhibit enhanced accuracy when image sentiment polarity hints are incorporated into the prompts. This observation underscores a notable deficiency in their inherent understanding of image sentiment. We believe that II-Bench will inspire the community to develop the next generation of MLLMs, advancing the journey towards expert artificial general intelligence (AGI). II-Bench is publicly available at https://huggingface.co/datasets/m-a-p/II-Bench.
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Mar 26, 2024
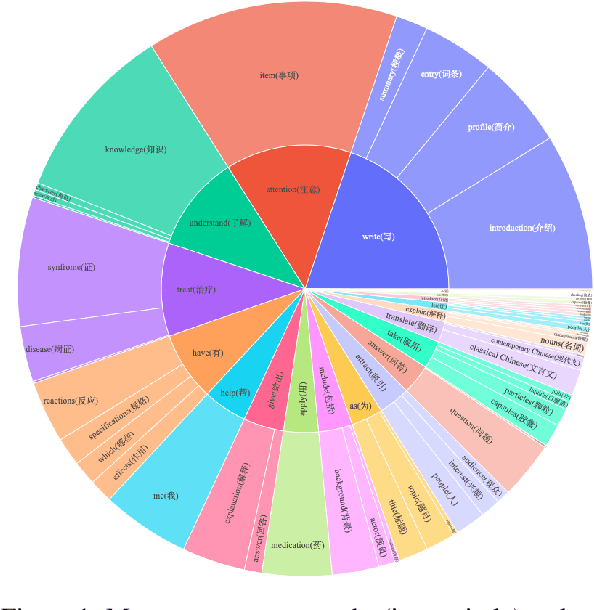
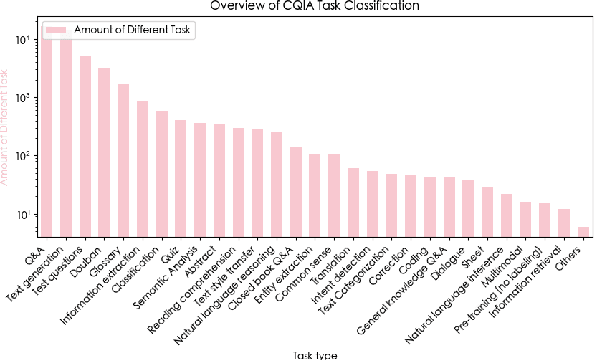

Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA
E-EVAL: A Comprehensive Chinese K-12 Education Evaluation Benchmark for Large Language Models
Jan 29, 2024



With the accelerating development of Large Language Models (LLMs), many LLMs are beginning to be used in the Chinese K-12 education domain. The integration of LLMs and education is getting closer and closer, however, there is currently no benchmark for evaluating LLMs that focuses on the Chinese K-12 education domain. Therefore, there is an urgent need for a comprehensive natural language processing benchmark to accurately assess the capabilities of various LLMs in the Chinese K-12 education domain. To address this, we introduce the E-EVAL, the first comprehensive evaluation benchmark specifically designed for the Chinese K-12 education field. The E-EVAL consists of 4,351 multiple-choice questions at the primary, middle, and high school levels across a wide range of subjects, including Chinese, English, Politics, History, Ethics, Physics, Chemistry, Mathematics, and Geography. We conducted a comprehensive evaluation of E-EVAL on advanced LLMs, including both English-dominant and Chinese-dominant models. Findings show that Chinese-dominant models perform well compared to English-dominant models, with many scoring even above the GPT 4.0. However, almost all models perform poorly in complex subjects such as mathematics. We also found that most Chinese-dominant LLMs did not achieve higher scores at the primary school level compared to the middle school level. We observe that the mastery of higher-order knowledge by the model does not necessarily imply the mastery of lower-order knowledge as well. Additionally, the experimental results indicate that the Chain of Thought (CoT) technique is effective only for the challenging science subjects, while Few-shot prompting is more beneficial for liberal arts subjects. With E-EVAL, we aim to analyze the strengths and limitations of LLMs in educational applications, and to contribute to the progress and development of Chinese K-12 education and LLMs.