 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIEBench: Towards Holistic Evaluation of Group Identity-based Empathy for Large Language Models
Jun 24, 2024
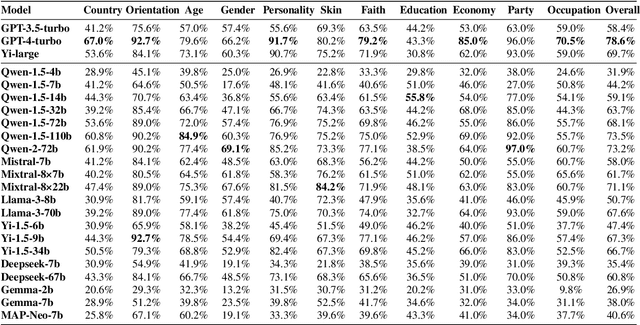

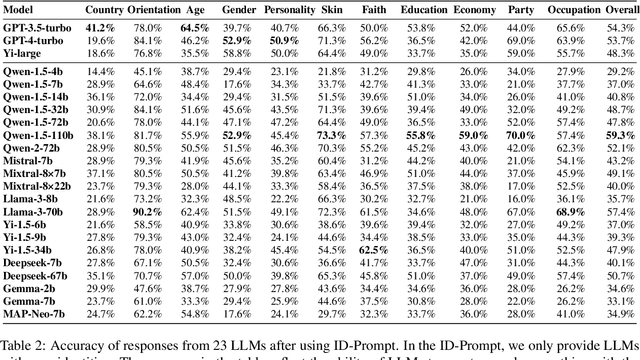
As large language models (LLMs) continue to develop and gain widespread application, the ability of LLMs to exhibit empathy towards diverse group identities and understand their perspectives is increasingly recognized as critical. Most existing benchmarks for empathy evaluation of LLMs focus primarily on universal human emotions, such as sadness and pain, often overlooking the context of individuals' group identities. To address this gap, we introduce GIEBench, a comprehensive benchmark that includes 11 identity dimensions, covering 97 group identities with a total of 999 single-choice questions related to specific group identities. GIEBench is designed to evaluate the empathy of LLMs when presented with specific group identities such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group. This supports the ongoing development of empathetic LLM applications tailored to users with different identities. Our evaluation of 23 LLMs revealed that while these LLMs understand different identity standpoints, they fail to consistently exhibit equal empathy across these identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities. Our datasets are available at https://github.com/GIEBench/GIEBench.
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Mar 26, 2024
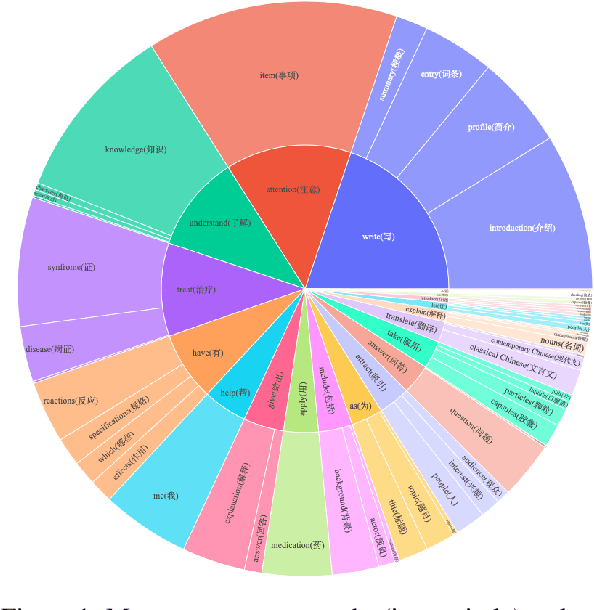
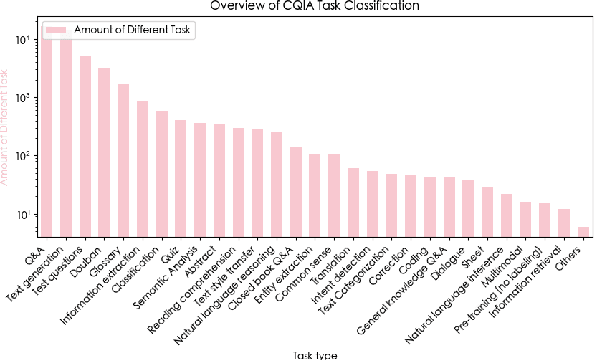

Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA
Read to Play (R2-Play): Decision Transformer with Multimodal Game Instruction
Feb 08, 2024



Developing a generalist agent is a longstanding objective in artificial intelligence. Previous efforts utilizing extensive offline datasets from various tasks demonstrate remarkable performance in multitasking scenarios within Reinforcement Learning. However, these works encounter challenges in extending their capabilities to new tasks. Recent approaches integrate textual guidance or visual trajectory into decision networks to provide task-specific contextual cues, representing a promising direction. However, it is observed that relying solely on textual guidance or visual trajectory is insufficient for accurately conveying the contextual information of tasks. This paper explores enhanced forms of task guidance for agents, enabling them to comprehend gameplay instructions, thereby facilitating a "read-to-play" capability. Drawing inspiration from the success of multimodal instruction tuning in visual tasks, we treat the visual-based RL task as a long-horizon vision task and construct a set of multimodal game instructions to incorporate instruction tuning into a decision transformer. Experimental results demonstrate that incorporating multimodal game instructions significantly enhances the decision transformer's multitasking and generalization capabilities.
JARVIS-1: Open-World Multi-task Agents with Memory-Augmented Multimodal Language Models
Nov 30, 2023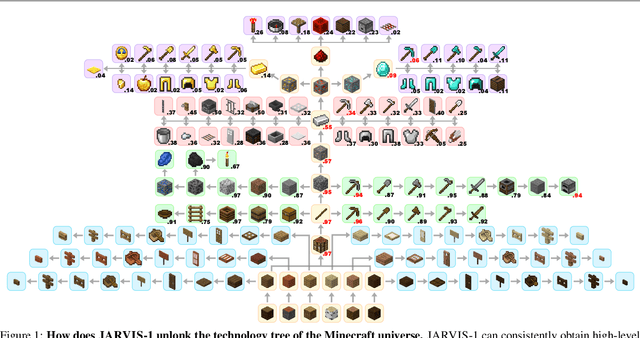
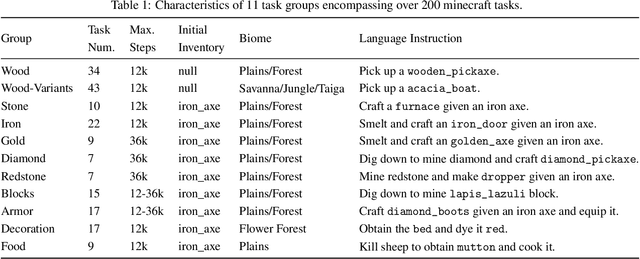


Achieving human-like planning and control with multimodal observations in an open world is a key milestone for more functional generalist agents. Existing approaches can handle certain long-horizon tasks in an open world. However, they still struggle when the number of open-world tasks could potentially be infinite and lack the capability to progressively enhance task completion as game time progresses. We introduce JARVIS-1, an open-world agent that can perceive multimodal input (visual observations and human instructions), generate sophisticated plans, and perform embodied control, all within the popular yet challenging open-world Minecraft universe. Specifically, we develop JARVIS-1 on top of pre-trained multimodal language models, which map visual observations and textual instructions to plans. The plans will be ultimately dispatched to the goal-conditioned controllers. We outfit JARVIS-1 with a multimodal memory, which facilitates planning using both pre-trained knowledge and its actual game survival experiences. JARVIS-1 is the existing most general agent in Minecraft, capable of completing over 200 different tasks using control and observation space similar to humans. These tasks range from short-horizon tasks, e.g., "chopping trees" to long-horizon tasks, e.g., "obtaining a diamond pickaxe". JARVIS-1 performs exceptionally well in short-horizon tasks, achieving nearly perfect performance. In the classic long-term task of $\texttt{ObtainDiamondPickaxe}$, JARVIS-1 surpasses the reliability of current state-of-the-art agents by 5 times and can successfully complete longer-horizon and more challenging tasks. The project page is available at https://craftjarvis.org/JARVIS-1
Deep Reinforcement Learning with Multitask Episodic Memory Based on Task-Conditioned Hypernetwork
Jun 21, 2023



Deep reinforcement learning algorithms are usually impeded by sampling inefficiency, heavily depending on multiple interactions with the environment to acquire accurate decision-making capabilities. In contrast, humans seem to rely on their hippocampus to retrieve relevant information from past experiences of relevant tasks, which guides their decision-making when learning a new task, rather than exclusively depending on environmental interactions. Nevertheless, designing a hippocampus-like module for an agent to incorporate past experiences into established reinforcement learning algorithms presents two challenges. The first challenge involves selecting the most relevant past experiences for the current task, and the second is integrating such experiences into the decision network. To address these challenges, we propose a novel algorithm that utilizes a retrieval network based on a task-conditioned hypernetwork, which adapts the retrieval network's parameters depending on the task. At the same time, a dynamic modification mechanism enhances the collaborative efforts between the retrieval and decision networks. We evaluate the proposed algorithm on the challenging MiniGrid environment. The experimental results demonstrate that our proposed method significantly outperforms strong baselines.