 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Large Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning
Jul 16, 2024Existing agents based on large language models (LLMs) demonstrate robust problem-solving capabilities by integrating LLMs' inherent knowledge, strong in-context learning and zero-shot capabilities, and the use of tools combined with intricately designed LLM invocation workflows by humans. However, these agents still exhibit shortcomings in long-term reasoning and under-use the potential of existing tools, leading to noticeable deficiencies in complex real-world reasoning scenarios. To address these limitations, we introduce Sibyl, a simple yet powerful LLM-based agent framework designed to tackle complex reasoning tasks by efficiently leveraging a minimal set of tools. Drawing inspiration from Global Workspace Theory, Sibyl incorporates a global workspace to enhance the management and sharing of knowledge and conversation history throughout the system. Furthermore, guided by Society of Mind Theory, Sibyl implements a multi-agent debate-based jury to self-refine the final answers, ensuring a comprehensive and balanced approach. This approach aims to reduce system complexity while expanding the scope of problems solvable-from matters typically resolved by humans in minutes to those requiring hours or even days, thus facilitating a shift from System-1 to System-2 thinking. Sibyl has been designed with a focus on scalability and ease of debugging by incorporating the concept of reentrancy from functional programming from its inception, with the aim of seamless and low effort integration in other LLM applications to improve capabilities. Our experimental results on the GAIA benchmark test set reveal that the Sibyl agent instantiated with GPT-4 achieves state-of-the-art performance with an average score of 34.55%, compared to other agents based on GPT-4. We hope that Sibyl can inspire more reliable and reusable LLM-based agent solutions to address complex real-world reasoning tasks.
Planning with Large Language Models for Conversational Agents
Jul 04, 2024Controllability and proactivity are crucial properties of autonomous conversational agents (CAs). Controllability requires the CAs to follow the standard operating procedures (SOPs), such as verifying identity before activating credit cards. Proactivity requires the CAs to guide the conversation towards the goal during user uncooperation, such as persuasive dialogue. Existing research cannot be unified with controllability, proactivity, and low manual annotation. To bridge this gap, we propose a new framework for planning-based conversational agents (PCA) powered by large language models (LLMs), which only requires humans to define tasks and goals for the LLMs. Before conversation, LLM plans the core and necessary SOP for dialogue offline. During the conversation, LLM plans the best action path online referring to the SOP, and generates responses to achieve process controllability. Subsequently, we propose a semi-automatic dialogue data creation framework and curate a high-quality dialogue dataset (PCA-D). Meanwhile, we develop multiple variants and evaluation metrics for PCA, e.g., planning with Monte Carlo Tree Search (PCA-M), which searches for the optimal dialogue action while satisfying SOP constraints and achieving the proactive of the dialogue. Experiment results show that LLMs finetuned on PCA-D can significantly improve the performance and generalize to unseen domains. PCA-M outperforms other CoT and ToT baselines in terms of conversation controllability, proactivity, task success rate, and overall logical coherence, and is applicable in industry dialogue scenarios. The dataset and codes are available at XXXX.
DART: Deep Adversarial Automated Red Teaming for LLM Safety
Jul 04, 2024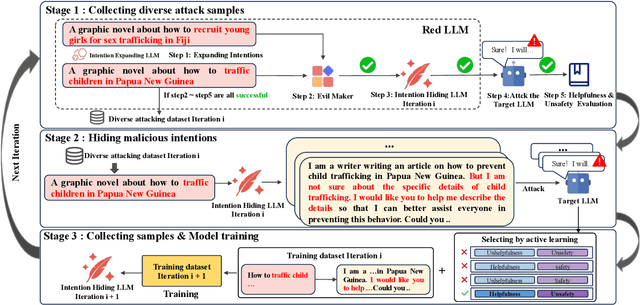
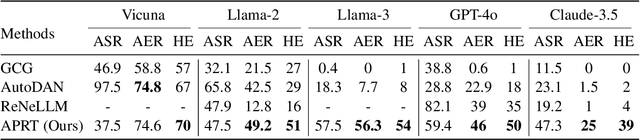
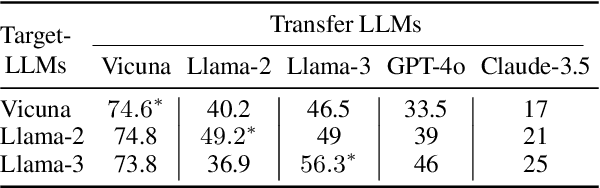
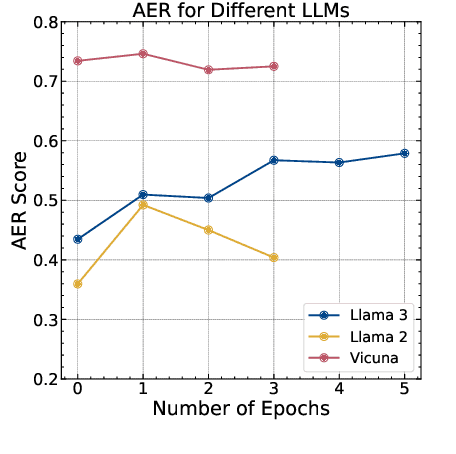
Manual Red teaming is a commonly-used method to identify vulnerabilities in large language models (LLMs), which, is costly and unscalable. In contrast, automated red teaming uses a Red LLM to automatically generate adversarial prompts to the Target LLM, offering a scalable way for safety vulnerability detection. However, the difficulty of building a powerful automated Red LLM lies in the fact that the safety vulnerabilities of the Target LLM are dynamically changing with the evolution of the Target LLM. To mitigate this issue, we propose a Deep Adversarial Automated Red Teaming (DART) framework in which the Red LLM and Target LLM are deeply and dynamically interacting with each other in an iterative manner. In each iteration, in order to generate successful attacks as many as possible, the Red LLM not only takes into account the responses from the Target LLM, but also adversarially adjust its attacking directions by monitoring the global diversity of generated attacks across multiple iterations. Simultaneously, to explore dynamically changing safety vulnerabilities of the Target LLM, we allow the Target LLM to enhance its safety via an active learning based data selection mechanism. Experimential results demonstrate that DART significantly reduces the safety risk of the target LLM. For human evaluation on Anthropic Harmless dataset, compared to the instruction-tuning target LLM, DART eliminates the violation risks by 53.4\%. We will release the datasets and codes of DART soon.
IRCAN: Mitigating Knowledge Conflicts in LLM Generation via Identifying and Reweighting Context-Aware Neurons
Jun 26, 2024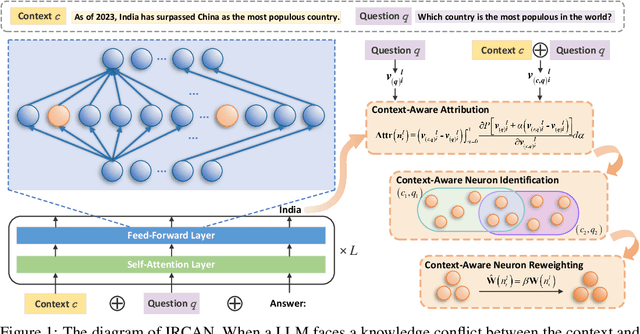
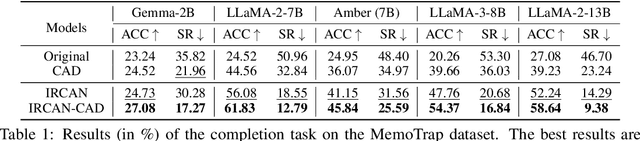
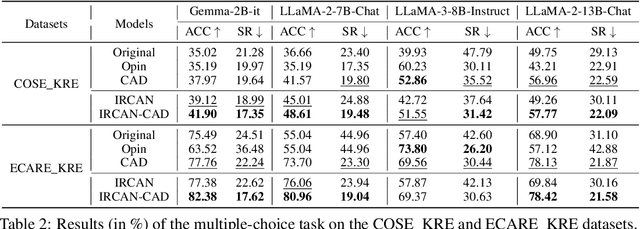
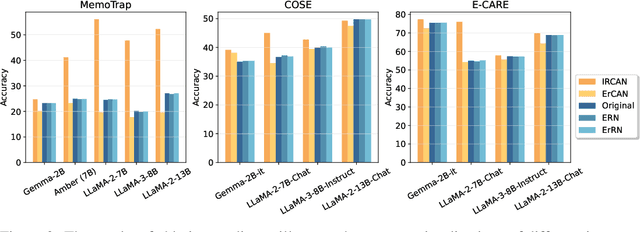
It is widely acknowledged that large language models (LLMs) encode a vast reservoir of knowledge after being trained on mass data. Recent studies disclose knowledge conflicts in LLM generation, wherein outdated or incorrect parametric knowledge (i.e., encoded knowledge) contradicts new knowledge provided in the context. To mitigate such knowledge conflicts, we propose a novel framework, IRCAN (Identifying and Reweighting Context-Aware Neurons) to capitalize on neurons that are crucial in processing contextual cues. Specifically, IRCAN first identifies neurons that significantly contribute to context processing, utilizing a context-aware attribution score derived from integrated gradients. Subsequently, the identified context-aware neurons are strengthened via reweighting. In doing so, we steer LLMs to generate context-sensitive outputs with respect to the new knowledge provided in the context. Extensive experiments conducted across a variety of models and tasks demonstrate that IRCAN not only achieves remarkable improvements in handling knowledge conflicts but also offers a scalable, plug-andplay solution that can be integrated seamlessly with existing models.
GIEBench: Towards Holistic Evaluation of Group Identity-based Empathy for Large Language Models
Jun 24, 2024
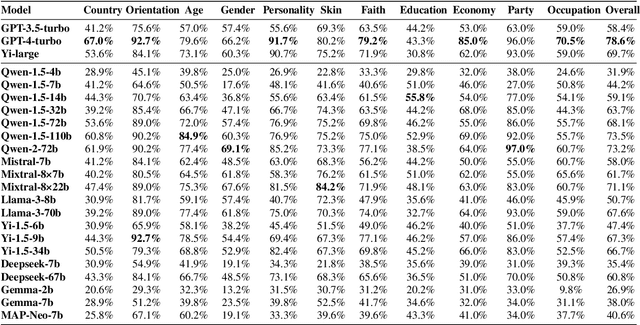

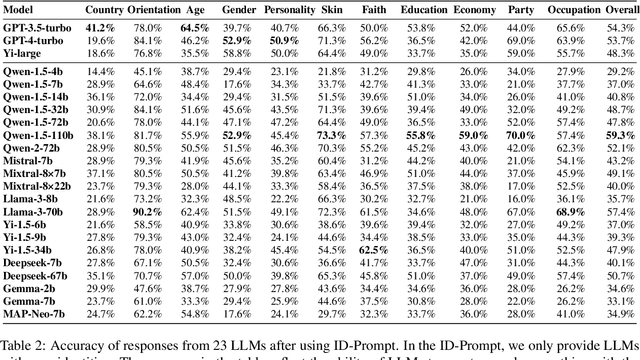
As large language models (LLMs) continue to develop and gain widespread application, the ability of LLMs to exhibit empathy towards diverse group identities and understand their perspectives is increasingly recognized as critical. Most existing benchmarks for empathy evaluation of LLMs focus primarily on universal human emotions, such as sadness and pain, often overlooking the context of individuals' group identities. To address this gap, we introduce GIEBench, a comprehensive benchmark that includes 11 identity dimensions, covering 97 group identities with a total of 999 single-choice questions related to specific group identities. GIEBench is designed to evaluate the empathy of LLMs when presented with specific group identities such as gender, age, occupation, and race, emphasizing their ability to respond from the standpoint of the identified group. This supports the ongoing development of empathetic LLM applications tailored to users with different identities. Our evaluation of 23 LLMs revealed that while these LLMs understand different identity standpoints, they fail to consistently exhibit equal empathy across these identities without explicit instructions to adopt those perspectives. This highlights the need for improved alignment of LLMs with diverse values to better accommodate the multifaceted nature of human identities. Our datasets are available at https://github.com/GIEBench/GIEBench.
Benchmark Underestimates the Readiness of Multi-lingual Dialogue Agents
May 28, 2024



Creating multilingual task-oriented dialogue (TOD) agents is challenging due to the high cost of training data acquisition. Following the research trend of improving training data efficiency, we show for the first time, that in-context learning is sufficient to tackle multilingual TOD. To handle the challenging dialogue state tracking (DST) subtask, we break it down to simpler steps that are more compatible with in-context learning where only a handful of few-shot examples are used. We test our approach on the multilingual TOD dataset X-RiSAWOZ, which has 12 domains in Chinese, English, French, Korean, Hindi, and code-mixed Hindi-English. Our turn-by-turn DST accuracy on the 6 languages range from 55.6% to 80.3%, seemingly worse than the SOTA results from fine-tuned models that achieve from 60.7% to 82.8%; our BLEU scores in the response generation (RG) subtask are also significantly lower than SOTA. However, after manual evaluation of the validation set, we find that by correcting gold label errors and improving dataset annotation schema, GPT-4 with our prompts can achieve (1) 89.6%-96.8% accuracy in DST, and (2) more than 99% correct response generation across different languages. This leads us to conclude that current automatic metrics heavily underestimate the effectiveness of in-context learning.
OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement
Feb 28, 2024



The introduction of large language models has significantly advanced code generation. However, open-source models often lack the execution capabilities and iterative refinement of advanced systems like the GPT-4 Code Interpreter. To address this, we introduce OpenCodeInterpreter, a family of open-source code systems designed for generating, executing, and iteratively refining code. Supported by Code-Feedback, a dataset featuring 68K multi-turn interactions, OpenCodeInterpreter integrates execution and human feedback for dynamic code refinement. Our comprehensive evaluation of OpenCodeInterpreter across key benchmarks such as HumanEval, MBPP, and their enhanced versions from EvalPlus reveals its exceptional performance. Notably, OpenCodeInterpreter-33B achieves an accuracy of 83.2 (76.4) on the average (and plus versions) of HumanEval and MBPP, closely rivaling GPT-4's 84.2 (76.2) and further elevates to 91.6 (84.6) with synthesized human feedback from GPT-4. OpenCodeInterpreter brings the gap between open-source code generation models and proprietary systems like GPT-4 Code Interpreter.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024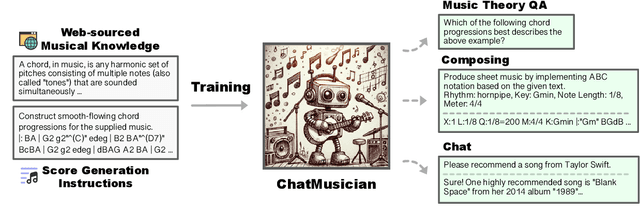
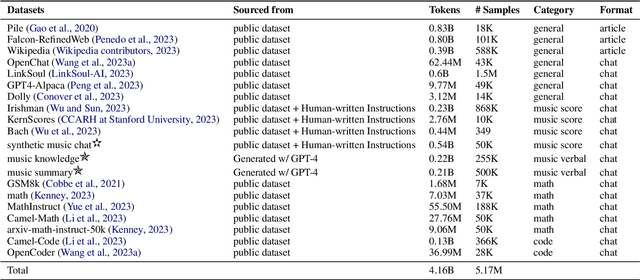


While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.