 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSPO: Subsentence-level Policy Optimization
Nov 06, 2025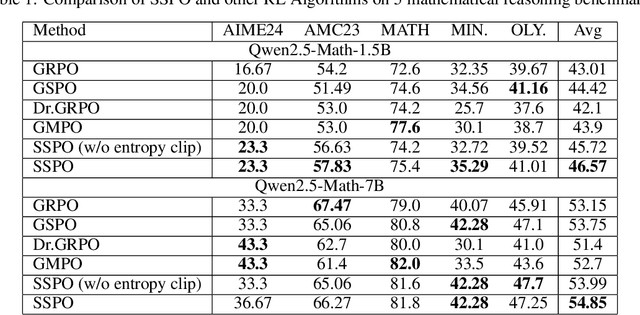
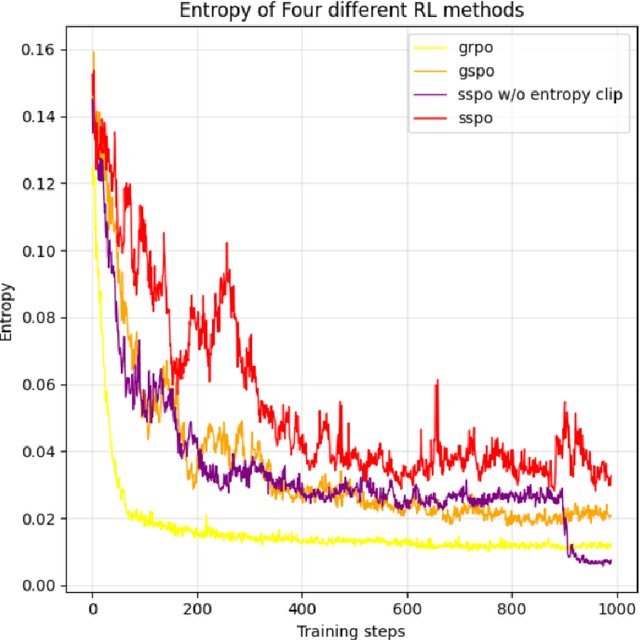
As a significant part of post-training of the Large Language Models (LLMs), Reinforcement Learning from Verifiable Reward (RLVR) has greatly improved LLMs' reasoning skills. However, some RLVR algorithms, such as GRPO (Group Relative Policy Optimization) and GSPO (Group Sequence Policy Optimization), are observed to suffer from unstable policy updates and low usage of sampling data, respectively. The importance ratio of GRPO is calculated at the token level, which focuses more on optimizing a single token. This will be easily affected by outliers, leading to model training collapse. GSPO proposed the calculation of the response level importance ratio, which solves the problem of high variance and training noise accumulation in the calculation of the GRPO importance ratio. However, since all the response tokens share a common importance ratio, extreme values can easily raise or lower the overall mean, leading to the entire response being mistakenly discarded, resulting in a decrease in the utilization of sampled data. This paper introduces SSPO, which applies sentence-level importance ratio, taking the balance between GRPO and GSPO. SSPO not only avoids training collapse and high variance, but also prevents the whole response tokens from being abandoned by the clipping mechanism. Furthermore, we apply sentence entropy to PPO-CLIP to steadily adjust the clipping bounds, encouraging high-entropy tokens to explore and narrow the clipping range of low-entropy tokens. In particular, SSPO achieves an average score of 46.57 across five datasets, surpassing GRPO (43.01) and GSPO (44.42), and wins state-of-the-art performance on three datasets. These results highlight SSPO's effectiveness in leveraging generated data by taking the essence of GSPO but rejecting its shortcomings.
Large Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
Learning to Adapt to Low-Resource Paraphrase Generation
Dec 22, 2024Paraphrase generation is a longstanding NLP task and achieves great success with the aid of large corpora. However, transferring a paraphrasing model to another domain encounters the problem of domain shifting especially when the data is sparse. At the same time, widely using large pre-trained language models (PLMs) faces the overfitting problem when training on scarce labeled data. To mitigate these two issues, we propose, LAPA, an effective adapter for PLMs optimized by meta-learning. LAPA has three-stage training on three types of related resources to solve this problem: 1. pre-training PLMs on unsupervised corpora, 2. inserting an adapter layer and meta-training on source domain labeled data, and 3. fine-tuning adapters on a small amount of target domain labeled data. This method enables paraphrase generation models to learn basic language knowledge first, then learn the paraphrasing task itself later, and finally adapt to the target task. Our experimental results demonstrate that LAPA achieves state-of-the-art in supervised, unsupervised, and low-resource settings on three benchmark datasets. With only 2\% of trainable parameters and 1\% labeled data of the target task, our approach can achieve a competitive performance with previous work.
Planning with Large Language Models for Conversational Agents
Jul 04, 2024Controllability and proactivity are crucial properties of autonomous conversational agents (CAs). Controllability requires the CAs to follow the standard operating procedures (SOPs), such as verifying identity before activating credit cards. Proactivity requires the CAs to guide the conversation towards the goal during user uncooperation, such as persuasive dialogue. Existing research cannot be unified with controllability, proactivity, and low manual annotation. To bridge this gap, we propose a new framework for planning-based conversational agents (PCA) powered by large language models (LLMs), which only requires humans to define tasks and goals for the LLMs. Before conversation, LLM plans the core and necessary SOP for dialogue offline. During the conversation, LLM plans the best action path online referring to the SOP, and generates responses to achieve process controllability. Subsequently, we propose a semi-automatic dialogue data creation framework and curate a high-quality dialogue dataset (PCA-D). Meanwhile, we develop multiple variants and evaluation metrics for PCA, e.g., planning with Monte Carlo Tree Search (PCA-M), which searches for the optimal dialogue action while satisfying SOP constraints and achieving the proactive of the dialogue. Experiment results show that LLMs finetuned on PCA-D can significantly improve the performance and generalize to unseen domains. PCA-M outperforms other CoT and ToT baselines in terms of conversation controllability, proactivity, task success rate, and overall logical coherence, and is applicable in industry dialogue scenarios. The dataset and codes are available at XXXX.